The Impact of RDMA on Agreement
Remote Direct Memory Access (RDMA) is becoming widely available in data centers. This technology allows a process to directly read and write the memory of a remote host, with a mechanism to control access permissions. In this paper, we study the fundamental power of these capabilities. We consider the well-known problem of achieving consensus despite failures, and find that RDMA can improve the inherent trade-off in distributed computing between failure resilience and performance. Specifically, we show that RDMA allows algorithms that simultaneously achieve high resilience and high performance, while traditional algorithms had to choose one or another. With Byzantine failures, we give an algorithm that only requires $n \geq 2f_P + 1$ processes (where $f_P$ is the maximum number of faulty processes) and decides in two (network) delays in common executions. With crash failures, we give an algorithm that only requires $n \geq f_P + 1$ processes and also decides in two delays. Both algorithms tolerate a minority of memory failures inherent to RDMA, and they provide safety in asynchronous systems and liveness with standard additional assumptions.
💡 Research Summary
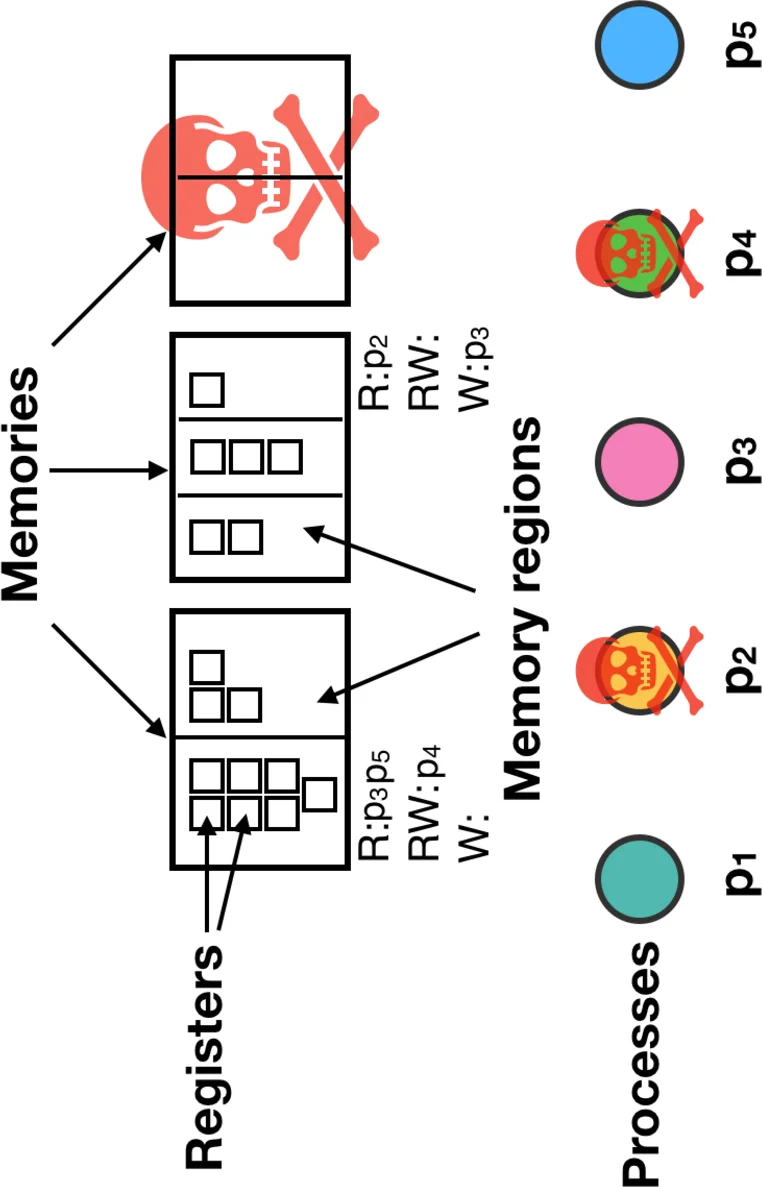
The paper investigates how Remote Direct Memory Access (RDMA), now common in modern data‑centers, can be leveraged to improve the classic consensus (agreement) problem under both Byzantine and crash failures. The authors formalize an extended Message‑and‑Memory (M&M) model that captures two distinctive RDMA features: (1) the ability of a process to read and write remote memory directly, and (2) fine‑grained, dynamically changeable access permissions on memory regions. In this model, each memory region carries three disjoint permission sets (read, write, read‑write) and a function legalChange determines whether a process may modify those permissions. The model also accounts for failures of the memories themselves (crash‑only), introducing a bound f_M on the number of faulty memories.
Using this model, the paper presents two consensus algorithms. The first addresses weak Byzantine agreement. By revoking write permissions before a write and requiring that a successful write implies uncontended access, the algorithm prevents a Byzantine process from corrupting shared memory. Consequently, the protocol tolerates up to f Byzantine processes with only n ≥ 2f + 1 participants (instead of the classic n ≥ 3f + 1) and decides in two network delays (two rounds) in the common case. The second algorithm handles pure crash failures. It further reduces the required number of processes to n ≥ f + 1 while still achieving a two‑delay decision. Both algorithms also tolerate memory crashes, requiring at least m ≥ 2f_M + 1 memories, and they can combine memory and process failures as long as the faulty memories form a minority.
The key insight is that the “dynamic permission” mechanism acts as a small trusted component. By restricting which processes may change permissions, Byzantine processes are effectively reduced to crash failures, and a successful write after permission revocation guarantees that no other process is concurrently writing the same register. This eliminates the need for extra coordination steps that traditional message‑only or memory‑only protocols require. The paper also proves a lower bound showing that pure shared‑memory algorithms cannot achieve a two‑round decision, underscoring the necessity of dynamic permissions.
Comparisons with prior work highlight that existing Byzantine Fault Tolerant (BFT) protocols either need n ≥ 3f + 1 processes or rely on large trusted components (coordinators, reliable broadcast, etc.) to obtain low latency. The RDMA‑based approach achieves both higher resilience and lower latency with only the hardware‑provided permission checks.
Finally, the authors discuss practical considerations: the cost of permission changes, handling unresponsive memories (which are indistinguishable from slow ones in an asynchronous setting), and how the model maps to real RDMA APIs. They argue that the theoretical gains translate into concrete design guidelines for building high‑availability, low‑latency services in modern data‑centers.
In summary, the paper demonstrates that RDMA’s direct remote‑memory access combined with dynamic access control fundamentally changes the trade‑off between fault tolerance and performance in distributed agreement. It provides algorithms that simultaneously achieve near‑optimal resilience (n ≥ 2f + 1 for Byzantine, n ≥ f + 1 for crash) and optimal common‑case latency (two network delays), thereby opening a new design space for future high‑performance, fault‑tolerant systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment