Deep Innovation Protection: Confronting the Credit Assignment Problem in Training Heterogeneous Neural Architectures
Deep reinforcement learning approaches have shown impressive results in a variety of different domains, however, more complex heterogeneous architectures such as world models require the different neural components to be trained separately instead of end-to-end. While a simple genetic algorithm recently showed end-to-end training is possible, it failed to solve a more complex 3D task. This paper presents a method called Deep Innovation Protection (DIP) that addresses the credit assignment problem in training complex heterogenous neural network models end-to-end for such environments. The main idea behind the approach is to employ multiobjective optimization to temporally reduce the selection pressure on specific components in multi-component network, allowing other components to adapt. We investigate the emergent representations of these evolved networks, which learn to predict properties important for the survival of the agent, without the need for a specific forward-prediction loss.
💡 Research Summary
The paper tackles the credit assignment problem (CAP) that arises when evolving heterogeneous neural architectures such as world models, which consist of a visual encoder, an LSTM‑based memory (MDN‑RNN), and a linear controller. Prior work trained each module separately or used a simple genetic algorithm (GA) that only optimizes final reward. While this works on simple 2‑D tasks, it fails on more complex 3‑D environments like VizDoom:Take Cover because changes in upstream modules (visual or memory) immediately degrade controller performance, preventing useful innovations from being propagated.
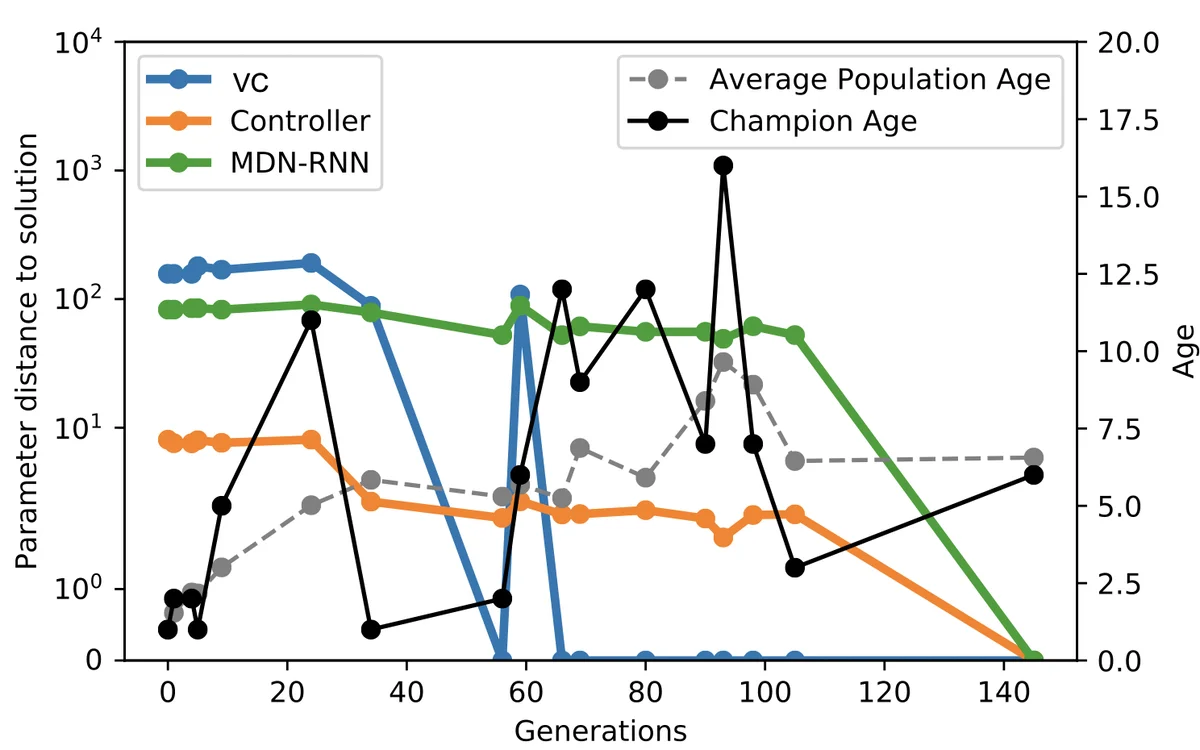
To address this, the authors introduce Deep Innovation Protection (DIP), a multi‑objective evolutionary strategy built on NSGA‑II. DIP optimizes two objectives: (1) accumulated task reward and (2) an “age” metric that counts generations since the visual encoder or memory module was last mutated. Whenever a mutation alters either the visual component (VC) or the MDN‑RNN, the individual’s age is reset to zero, giving the downstream controller time to adapt before the individual is judged by selection pressure. This age‑based protection differs from traditional age‑based diversity mechanisms; here it explicitly protects recent innovations upstream.
Four experimental treatments are compared: (i) DIP (protect VC and MDN‑RNN), (ii) controller‑only protection, (iii) MDN‑RNN + controller protection, (iv) random age values, and (v) a standard GA with no protection. All treatments use the same mutation probability across the three modules, population size 200, σ = 0.03, and no crossover. The tasks are CarRacing‑v0 (2‑D continuous control) and VizDoom:Take Cover (3‑D first‑person survival). Results show that on CarRacing both DIP and the standard GA achieve similar high scores (~905), indicating that protection is unnecessary for simple tasks. In contrast, on VizDoom DIP dramatically outperforms all baselines, achieving an average survival score of 824 ± 492, while the standard GA fails to solve the task entirely. Random age improves performance modestly by increasing population diversity, but still lags behind DIP, confirming that selective protection rather than mere diversity is key.
The authors further analyze the evolved policies. Perturbation‑based saliency maps reveal that agents focus on walls, incoming fireballs, monster positions, and even HUD elements such as health and ammo—features directly relevant to survival. t‑SNE visualizations of the 32‑dimensional latent vector (z) from the visual encoder, the LSTM hidden state, and their concatenation show that z alone does not separate states meaningfully, whereas the hidden state alone or combined with z forms clear clusters that correspond to distinct action decisions. This demonstrates that the evolutionary process discovers internal representations aligned with task‑relevant information without any explicit reconstruction or forward‑prediction loss.
Key contributions are: (1) the DIP mechanism that temporally reduces selection pressure on individuals whose upstream modules have just changed, allowing downstream components to readapt; (2) integration of DIP with NSGA‑II to jointly optimize performance and adaptation time; (3) empirical evidence that DIP enables end‑to‑end evolution of heterogeneous architectures on challenging 3‑D tasks, producing agents that implicitly learn predictive, survival‑focused representations. The work opens avenues for applying protected evolutionary strategies to other multi‑module systems such as robotics, autonomous driving, and multimodal perception, where coordinated learning across heterogeneous components is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment