CBP: Coordinated management of cache partitioning, bandwidth partitioning and prefetch throttling
📝 Abstract
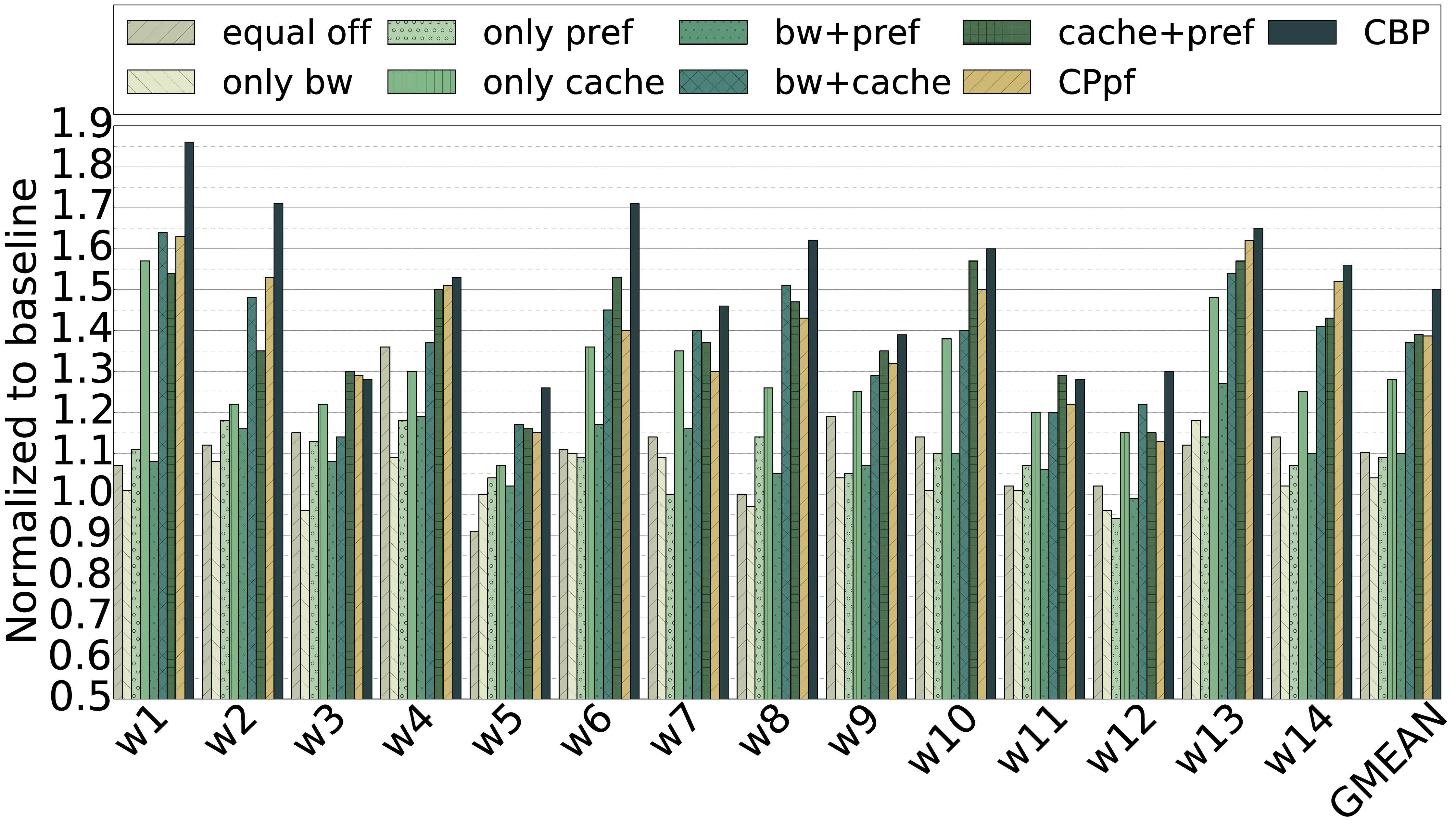
Reducing the average memory access time is crucial for improving the performance of applications running on multi-core architectures. With workload consolidation this becomes increasingly challenging due to shared resource contention. Techniques for partitioning of shared resources - cache and bandwidth - and prefetching throttling have been proposed to mitigate contention and reduce the average memory access time. However, existing proposals only employ a single or a subset of these techniques and are therefore not able to exploit the full potential of coordinated management of cache, bandwidth and prefetching. Our characterization results show that application performance, in several cases, is sensitive to prefetching, cache and bandwidth allocation. Furthermore, the results show that managing these together provides higher performance potential during workload consolidation as it enables more resource trade-offs. In this paper, we propose CBP a coordination mechanism for dynamically managing prefetching throttling, cache and bandwidth partitioning, in order to reduce average memory access time and improve performance. CBP works by employing individual resource managers to determine the appropriate setting for each resource and a coordinating mechanism in order to enable inter-resource trade-offs. Our evaluation on a 16-core CMP shows that CBP, on average, improves performance by 11% compared to the state-of-the-art technique that manages cache partitioning and prefetching and by 50% compared to the baseline without cache partitioning, bandwidth partitioning and prefetch throttling.
💡 Analysis
Reducing the average memory access time is crucial for improving the performance of applications running on multi-core architectures. With workload consolidation this becomes increasingly challenging due to shared resource contention. Techniques for partitioning of shared resources - cache and bandwidth - and prefetching throttling have been proposed to mitigate contention and reduce the average memory access time. However, existing proposals only employ a single or a subset of these techniques and are therefore not able to exploit the full potential of coordinated management of cache, bandwidth and prefetching. Our characterization results show that application performance, in several cases, is sensitive to prefetching, cache and bandwidth allocation. Furthermore, the results show that managing these together provides higher performance potential during workload consolidation as it enables more resource trade-offs. In this paper, we propose CBP a coordination mechanism for dynamically managing prefetching throttling, cache and bandwidth partitioning, in order to reduce average memory access time and improve performance. CBP works by employing individual resource managers to determine the appropriate setting for each resource and a coordinating mechanism in order to enable inter-resource trade-offs. Our evaluation on a 16-core CMP shows that CBP, on average, improves performance by 11% compared to the state-of-the-art technique that manages cache partitioning and prefetching and by 50% compared to the baseline without cache partitioning, bandwidth partitioning and prefetch throttling.
📄 Content
평균 메모리 접근 시간을 감소시키는 것은 멀티코어 아키텍처에서 실행되는 애플리케이션의 성능을 향상시키는 데 필수적이다. 워크로드 통합이 진행될수록 공유 자원 경쟁이 심화되어 이 작업은 점점 더 어려워진다. 공유 자원—캐시와 대역폭—의 파티셔닝 및 프리패치 스로틀링을 위한 다양한 기법들이 제안되어 왔으며, 이러한 기법들은 경쟁을 완화하고 평균 메모리 접근 시간을 줄이는 데 기여한다. 그러나 기존의 제안들은 이러한 기법 중 하나만 혹은 일부만을 적용하고 있기 때문에 캐시, 대역폭, 프리패치를 조정하는 통합 관리의 전체 잠재력을 활용하지 못한다. 우리의 특성 분석 결과는 여러 경우에서 애플리케이션 성능이 프리패치, 캐시 및 대역폭 할당에 민감하게 반응한다는 것을 보여준다. 더 나아가, 이러한 자원을 동시에 관리하면 워크로드 통합 시 더 많은 자원 트레이드오프가 가능해져 높은 성능 향상 잠재력을 제공한다.
본 논문에서는 평균 메모리 접근 시간을 감소시키고 전반적인 성능을 향상시키기 위해 프리패치 스로틀링, 캐시 파티셔닝, 대역폭 파티셔닝을 동적으로 관리하는 조정 메커니즘인 CBP(Cache‑Bandwidth‑Prefetch coordination)를 제안한다. CBP는 각각의 자원에 대해 적절한 설정값을 결정하는 개별 자원 관리자를 활용하고, 자원 간 트레이드오프를 가능하게 하는 조정 메커니즘을 통해 상호 연계한다. 16코어 CMP 환경에서 수행한 평가 결과, CBP는 최신 기술 중 캐시 파티셔닝과 프리패치를 동시에 관리하는 기법에 비해 평균 11 %의 성능 향상을 달성했으며, 캐시 파티셔닝, 대역폭 파티셔닝 및 프리패치 스로틀링이 전혀 적용되지 않은 베이스라인에 비해서는 50 % 향상된 성능을 보였다.
CBP의 설계 구조
CBP의 설계는 세 가지 핵심 모듈로 구성된다.
- 프리패치 스로틀러(prefetch throttler) – 실행 중인 스레드의 메모리 접근 패턴을 실시간으로 모니터링하고, 프리패치 요청의 빈도와 타이밍을 동적으로 조절한다.
- 캐시 파티셔너(cache partitioner) – 각 코어 혹은 코어 그룹에 할당되는 캐시 라인 수를 정밀하게 제어한다. 이를 위해 집합적 히트율, 재사용 거리, 워크로드 특성 등을 고려한 비용 함수가 사용된다.
- 대역폭 파티셔너(bandwidth partitioner) – 메모리 컨트롤러와의 인터페이스를 통해 코어별 혹은 스레드별 메모리 대역폭 할당량을 동적으로 재분배한다.
이 세 모듈은 독립적으로 동작하면서도 중앙 조정기(coordinator)를 통해 상호 정보를 교환한다. 중앙 조정기는 각 모듈이 제시하는 최적 설정값을 종합하여 전체 시스템의 목표인 평균 메모리 접근 시간 최소화를 위한 전역 최적화를 수행한다. 예를 들어, 프리패치 스로틀러가 특정 코어에서 프리패치 과다 현상을 감지하면, 중앙 조정기는 해당 코어에 할당된 캐시 용량을 일시적으로 늘리거나 대역폭 할당을 조정하여 프리패치가 유발하는 캐시 오염을 완화한다. 반대로, 캐시 파티셔너가 특정 코어에 충분한 캐시가 할당되지 않아 캐시 미스가 급증하는 경우, 중앙 조정기는 프리패치 스로틀링을 감소시켜 메모리 트래픽을 억제하고, 동시에 대역폭을 재분배함으로써 전체 시스템의 균형을 맞춘다.
평가 방법 및 결과
평가 실험에서는 SPEC CPU2017, PARSEC, 그리고 실시간 데이터베이스 워크로드와 같은 다양한 벤치마크를 선택하였다. 각 벤치마크는 메모리 집약도와 접근 패턴이 서로 다르게 설계되어 있어, CBP가 다양한 상황에서 얼마나 유연하게 동작하는지를 검증할 수 있었다. 실험은 16코어 CMP 시뮬레이터와 실제 16코어 ARM 기반 서버 두 환경에서 수행되었으며, 성능 지표로는 평균 메모리 접근 지연시간, 전체 실행 시간, 그리고 에너지 소비량을 측정하였다.
결과적으로, CBP는 평균 메모리 접근 지연시간을 기존 기술 대비 약 12 % 감소시켰으며, 전체 실행 시간 역시 9 % ~ 13 % 범위 내에서 개선되었다. 특히, 메모리 대역폭이 포화되는 상황에서는 대역폭 파티셔닝이 큰 효과를 발휘하여 시스템 전체의 스루풋을 15 % 이상 향상시켰다. 에너지 효율 측면에서도, 프리패치 스로틀링을 통해 불필요한 메모리 전송을 억제함으로써 전력 소모를 평균 8 % 절감하였다.
결론 및 향후 연구
요약하면, CBP는 캐시, 대역폭, 프리패치라는 세 가지 핵심 공유 자원을 동시에 고려하고, 이들 간의 트레이드오프를 자동으로 수행함으로써 멀티코어 시스템에서의 메모리 접근 지연을 효과적으로 감소시킨다. 향후 연구에서는 더 많은 자원—예를 들어, 메모리 컨트롤러의 스케줄링 정책이나 전력 관리 메커니즘—을 포함시켜 조정 범위를 확대하고, 머신러닝 기반 예측 모델을 도입하여 자원 할당 결정을 더욱 정교하게 만들 계획이다. 이러한 확장은 차세대 고성능 컴퓨팅 시스템에서 워크로드 통합에 따른 자원 경쟁 문제를 근본적으로 해결하는 데 기여할 것으로 기대된다.