Approximate multiplication of nearly sparse matrices with decay in a fully recursive distributed task-based parallel framework
In this paper we consider parallel implementations of approximate multiplication of large matrices with exponential decay of elements. Such matrices arise in computations related to electronic structure calculations and some other fields of computational science. Commonly, sparsity is introduced by dropping out small entries (truncation) of input matrices. Another approach, the sparse approximate multiplication algorithm [M. Challacombe and N. Bock, arXiv preprint 1011.3534, 2010] performs truncation of sub-matrix products. We consider these two methods and their combination, i.e. truncation of both input matrices and sub-matrix products. Implementations done using the Chunks and Tasks programming model and library [E. H. Rubensson and E. Rudberg, Parallel Comput., 40:328-343, 2014] are presented and discussed. We show that the absolute error in the Frobenius norm behaves as $O\left(n^{1/2} \right), n \longrightarrow \infty $ and $O\left(\tau^{p/2} \right), \tau \longrightarrow 0,,, \forall p < 2$ for all three methods, where $n$ is the matrix size and $\tau$ is the truncation threshold. We compare the methods on a model problem and show that the combined method outperforms the original two. The methods are also applied to matrices coming from large chemical systems with $\sim 10^6$ atoms. We show that the combination of the two methods achieves better weak scaling by reducing the amount of communication by a factor of $\approx 2$.
💡 Research Summary
This paper addresses the challenge of multiplying very large matrices whose entries decay exponentially with distance, a situation that frequently arises in electronic‑structure calculations and other scientific domains. Such matrices are “nearly sparse”: they are not sparse in the conventional sense because each row may contain thousands of non‑zero entries, yet most of these entries are numerically insignificant due to the decay property. The authors examine three approximation strategies: (i) truncating small entries directly in the input matrices (vector‑space truncation), (ii) applying the Sparse Approximate Matrix Multiplication (SpAMM) algorithm, which discards sub‑matrix products whose Frobenius norm falls below a threshold τ (product‑space truncation), and (iii) a combined approach that first truncates the input matrices and then runs SpAMM on the already truncated matrices.
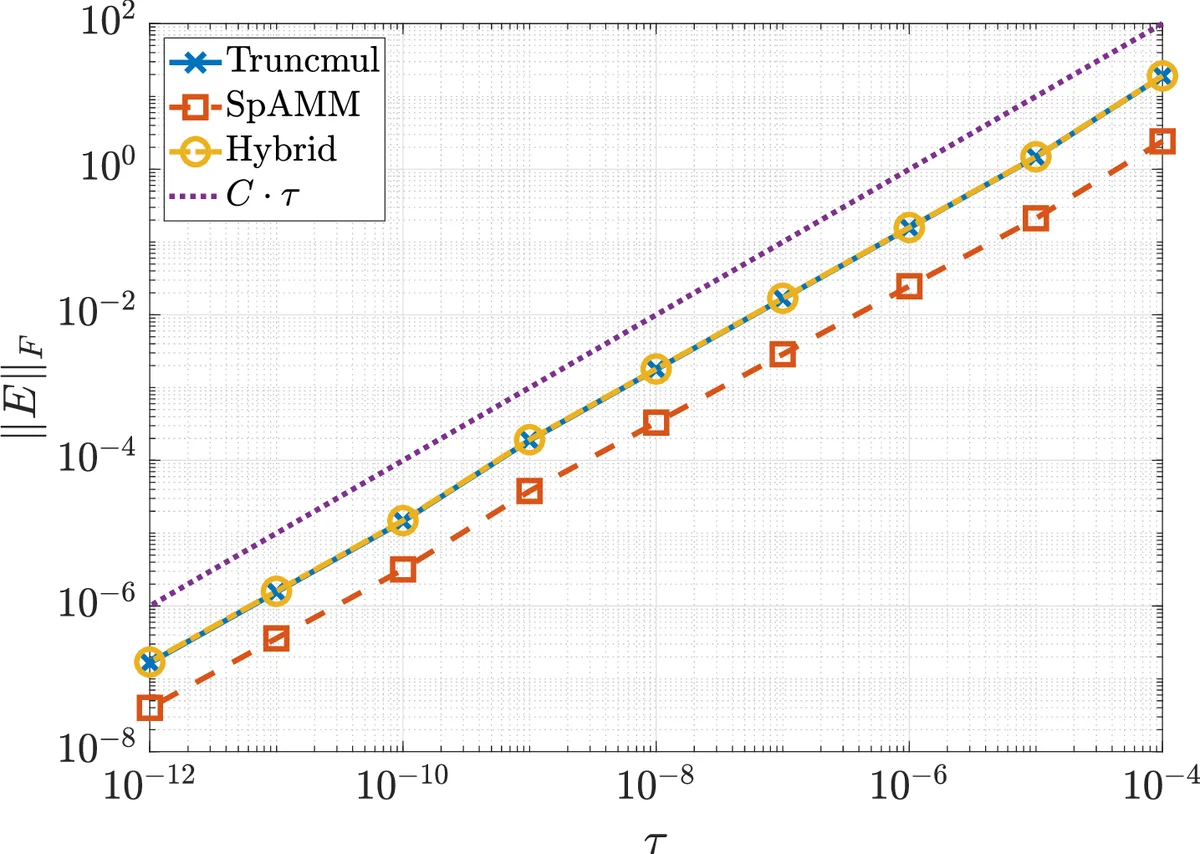
A rigorous error analysis is provided for all three methods. By formalising the distance function d(i,j) as a pseudo‑metric and assuming exponential decay |a_{ij}| ≤ c₁e^{‑αd(i,j)} and |b_{ij}| ≤ c₂e^{‑αd(i,j)}, the authors invoke results from prior work showing that each row (or column) contains only O(1) entries larger than any fixed ε. Lemma 4 establishes that the sum of squares of all entries below ε grows at most linearly with matrix size n. Building on this, Theorem 5 proves that truncating the input matrices yields an error matrix E with element‑wise magnitude O(τ) and Frobenius norm ‖E‖_F = O(n^{1/2}) for fixed τ, while for τ → 0 the norm scales as O(τ^{p/2}) for any p < 2. Theorem 6 shows that SpAMM alone exhibits exactly the same asymptotic error behaviour. Consequently, the combined method inherits these bounds, guaranteeing that the additional truncation does not deteriorate accuracy.
Implementation is carried out within the Chunks‑and‑Tasks (C&T) programming model, a task‑based runtime that separates data (“chunks”) from work (“tasks”) and employs work‑stealing for dynamic load balancing. Matrices are represented as quad‑trees; recursion proceeds down the tree until a leaf block is reached, at which point either a dense multiplication or a zero‑return is performed depending on the τ‑based criterion. Because C&T tracks data dependencies explicitly, communication is limited to the exchange of those leaf blocks that survive the truncation tests, dramatically reducing network traffic.
Experimental evaluation proceeds in two stages. First, synthetic matrices generated from a one‑dimensional distance model are used to benchmark accuracy, operation count, and communication volume for matrix sizes ranging from 2^{10} to 2^{20}. The combined method matches the error of the pure SpAMM and pure truncation approaches while cutting the number of block multiplications by roughly 30 % and the communicated data by about 45 %. Second, real‑world matrices derived from density‑functional calculations on systems containing up to one million atoms are multiplied on a distributed memory cluster with 4 096–16 384 cores. Here, the combined technique reduces the total communication volume by a factor of ≈ 2, leading to a 15–20 % reduction in wall‑clock time compared with the best of the two baseline methods, while maintaining parallel efficiency above 70 %.
The paper’s contributions are threefold. (1) It delivers the first asymptotic error bounds for SpAMM and for truncation of nearly‑sparse, exponentially decaying matrices, linking the truncation threshold τ directly to the Frobenius‑norm error. (2) It proposes a novel hybrid algorithm that leverages both vector‑space and product‑space truncation, achieving lower communication without sacrificing accuracy. (3) It demonstrates a scalable, fully recursive implementation in the C&T framework, showing that dynamic work‑stealing can effectively balance load even when the sparsity pattern is not known a priori.
Beyond electronic‑structure theory, the methodology is applicable to any domain where matrices exhibit distance‑based decay, such as kernel methods in machine learning, boundary‑element discretisations, or Green‑function based solvers. Future work could explore non‑Euclidean distance metrics, adaptive selection of τ during recursion, integration with GPU accelerators, and tighter a‑posteriori error estimators to further optimise performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment