A Comparison of Audio Signal Preprocessing Methods for Deep Neural Networks on Music Tagging
In this paper, we empirically investigate the effect of audio preprocessing on music tagging with deep neural networks. We perform comprehensive experiments involving audio preprocessing using different time-frequency representations, logarithmic magnitude compression, frequency weighting, and scaling. We show that many commonly used input preprocessing techniques are redundant except magnitude compression.
💡 Research Summary
This paper conducts a systematic empirical study of audio preprocessing techniques for deep neural network–based music tagging. The authors fix a representative convolutional architecture (the k2c2 ConvNet) that uses 2‑D kernels on a single‑channel input of size (1, 96, 1360), corresponding to 96 mel‑frequency bins over 1 360 time frames. The dataset is the Million Song Dataset, with 30‑second MP3 excerpts down‑mixed, down‑sampled to 12 kHz, and transformed using a hop size of 256 samples and a 512‑point FFT, yielding 96 mel bins per frame.
Four preprocessing dimensions are explored: (1) time‑frequency representation (STFT vs. mel‑spectrogram), (2) magnitude compression (logarithmic/decibel scaling vs. linear), (3) frequency‑axis weighting (per‑frequency standardisation, A‑weighting, or no weighting), and (4) overall magnitude scaling (multiplying the input by 10 or leaving it unchanged). Combining these yields twelve distinct configurations.
Key findings:
-
STFT vs. mel‑spectrogram – When the STFT has higher frequency resolution (23.3 Hz) than the mel‑spectrogram (35.9 Hz for <1 kHz), both representations achieve virtually identical AUC scores across a range of training set sizes. The performance gap never exceeds 0.007, and with sufficient data the network learns equally effective features from either representation. Nevertheless, mel‑spectrograms are computationally cheaper due to their reduced dimensionality.
-
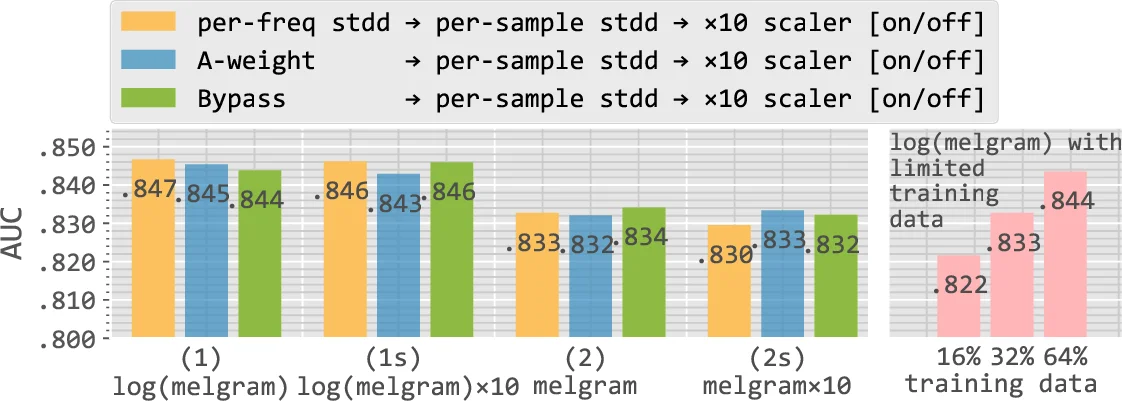
Frequency‑axis weighting – Applying per‑frequency standardisation (spectral whitening), A‑weighting (human loudness curve), or no weighting results in negligible AUC differences (within 0.004). The convolutional layers’ locality appears robust to the energy imbalance across frequencies, so the network can learn useful patterns regardless of the weighting scheme.
-
Magnitude scaling – Multiplying the entire input by a factor of 10 does not improve performance. The authors observe that batch‑normalisation in the first convolutional layer compensates for the changed scale, altering only the bias magnitude (approximately 3.4× larger when scaling is applied). Consequently, scaling has no measurable impact on AUC.
-
Logarithmic compression – This is the sole preprocessing step that yields a statistically significant boost. Log‑compressed mel‑spectrograms produce an approximately Gaussian distribution of time‑frequency magnitudes, eliminating extreme values and improving numerical stability. Linear‑scale inputs remain highly skewed, requiring higher numerical precision and making the network more vulnerable to noise. Empirically, log compression improves AUC by about 0.007–0.009. Moreover, to match the performance of a log‑compressed system, a non‑compressed system would need roughly twice as much training data, quantifying the practical cost of omitting this step.
The authors also assess variance due to weight initialisation by repeating each experiment 15 times with He‑normal initialisation. The resulting standard deviation of AUC is below 0.001, confirming that the reported differences are not due to random initialisation noise.
In conclusion, the study demonstrates that most common audio preprocessing variations—choice of time‑frequency representation, frequency‑axis weighting, and magnitude scaling—have minimal effect on deep music‑tagging performance when a well‑designed ConvNet and sufficient data are used. Logarithmic magnitude compression, however, is essential: it consistently enhances performance, reduces the amount of data required for a given accuracy, and stabilises training. These insights, while derived from music tagging, are likely transferable to related MIR tasks such as genre classification, instrument detection, and vocal detection.
Comments & Academic Discussion
Loading comments...
Leave a Comment