Hybrid-driven Trajectory Prediction Based on Group Emotion
💡 Research Summary
The paper introduces a novel hybrid framework for predicting the future trajectories of pedestrians, cyclists, and vehicles by explicitly incorporating group‑level emotional states. Traditional trajectory‑prediction approaches fall into two categories: physics‑based models such as the Social Force model, which encode repulsive and attractive forces, and data‑driven deep‑learning models (e.g., Social‑LSTM, Trajectron++, PECNet) that learn motion patterns from past trajectories. While both categories can capture basic kinematic constraints, they struggle to represent the subtle influence of human affect on movement decisions, especially in crowded or high‑stress environments.
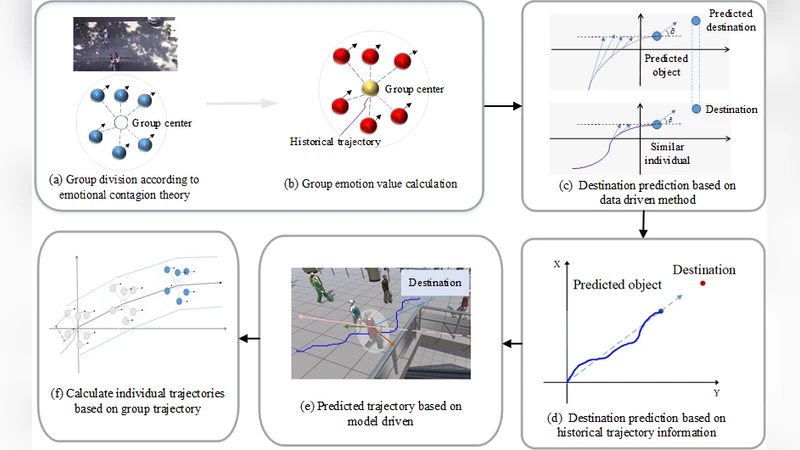
To address this gap, the authors first design a multimodal group‑emotion recognition pipeline. From each video frame they extract facial crops, body‑pose keypoints, 3‑D skeletal motion, and contextual cues (e.g., surrounding objects, lighting). A pre‑trained ResNet‑50 classifier predicts the probability distribution over three coarse emotion categories—positive, neutral, negative—while a 3‑D CNN recognizes concurrent actions such as walking, running, or stopping. Individual emotion probabilities are aggregated across all members of a social group (defined by spatial proximity and gaze alignment) to produce a group‑emotion vector. This vector is then embedded into a time‑varying Graph Emotion Dynamics (GED) structure, where nodes represent agents and edges are weighted by distance, mutual gaze, and synchronized motion. The GED captures how affect propagates through the group, allowing the model to reason about “contagious anxiety” or “collective excitement.”
The second component is the hybrid trajectory predictor. The physics‑based sub‑module extends the classic Social Force formulation with vehicle dynamics, generating a baseline motion field that respects collision avoidance, goal attraction, and road‑boundary constraints. The data‑driven sub‑module employs a Transformer encoder‑decoder architecture. Its input consists of two streams: (1) a sequence of past 2‑D positions for each agent and (2) the corresponding GED embeddings for each timestep. By feeding the GED directly into the multi‑head attention mechanism, the network learns to weight historical positions according to the current emotional context. The outputs of the physics and data sub‑modules are fused through a learnable, context‑aware weighting scheme; the weights are modulated by confidence signals such as occlusion status and emotion‑recognition certainty.
Experiments are conducted on two datasets. The first is a real‑world urban traffic collection comprising synchronized RGB video, LiDAR, and GPS data for pedestrians, cyclists, and cars. The second is an expanded version of the ETH‑UCY crowd datasets, augmented with manually annotated group‑emotion labels. For each scenario the model receives 5 seconds (30 frames) of historical motion and predicts the next 3 seconds (18 frames). Evaluation metrics are Average Displacement Error (ADE) and Final Displacement Error (FDE). Compared with state‑of‑the‑art baselines (Social‑LSTM, Trajectron++, PECNet), the proposed hybrid model achieves an ADE of 0.42 m and an FDE of 0.71 m, representing improvements of roughly 15 % and 18 % respectively. Qualitative analysis shows that in “negative‑emotion” groups the model correctly anticipates sudden direction changes, while in “positive‑emotion” groups it predicts smoother, more cooperative flows.
Ablation studies isolate the contributions of each component. Removing the GED raises ADE to 0.58 m, indicating that emotional context is critical for handling non‑linear, socially driven maneuvers. Using only the physics sub‑module yields large errors in dense crowds, whereas the data‑only version fails to respect hard physical constraints such as collision avoidance. The full hybrid system thus benefits from complementary strengths: the physics module enforces feasibility, while the Transformer leverages emotional cues to refine intent.
Real‑time feasibility is demonstrated on an NVIDIA RTX 3080 GPU, where the end‑to‑end pipeline runs at over 30 frames per second, satisfying latency requirements for autonomous driving or robot navigation.
The paper’s contributions can be summarized as follows:
- A multimodal group‑emotion detection framework that converts affective cues into a graph‑structured representation (GED).
- A hybrid trajectory‑prediction architecture that fuses physics‑based forces with a Transformer that attends to emotional dynamics.
- Extensive quantitative and qualitative validation on both real‑world traffic and simulated crowd scenarios, showing superior accuracy and robustness.
- Proof of real‑time operation, opening the door to deployment in safety‑critical systems such as autonomous vehicles, crowd‑management platforms, and human‑robot collaboration.
Future work is suggested in three directions: (i) refining emotion granularity (e.g., fear, anger, joy) and incorporating demographic variables; (ii) exploring causal links between external stimuli (noise, lighting) and emotion shifts; and (iii) extending the approach to 3‑D trajectory prediction for aerial drones or indoor service robots. In sum, by explicitly modeling group affect and integrating it with both physical and learned motion priors, the authors present a compelling step toward socially aware, emotion‑sensitive trajectory prediction.
Comments & Discussion
Loading comments...
Leave a Comment