Querying collections of tree-structured records in the presence of within-record referential constraints
📝 Abstract
In this paper, we consider a tree-structured data model used in many commercial databases like Dremel, F1, JSON stores. We define identity and referential constraints within each tree-structured record. The query language is a variant of SQL and flattening is used as an evaluation mechanism. We investigate querying in the presence of these constraints, and point out the challenges that arise from taking them into account during query evaluation.
💡 Analysis
In this paper, we consider a tree-structured data model used in many commercial databases like Dremel, F1, JSON stores. We define identity and referential constraints within each tree-structured record. The query language is a variant of SQL and flattening is used as an evaluation mechanism. We investigate querying in the presence of these constraints, and point out the challenges that arise from taking them into account during query evaluation.
📄 Content
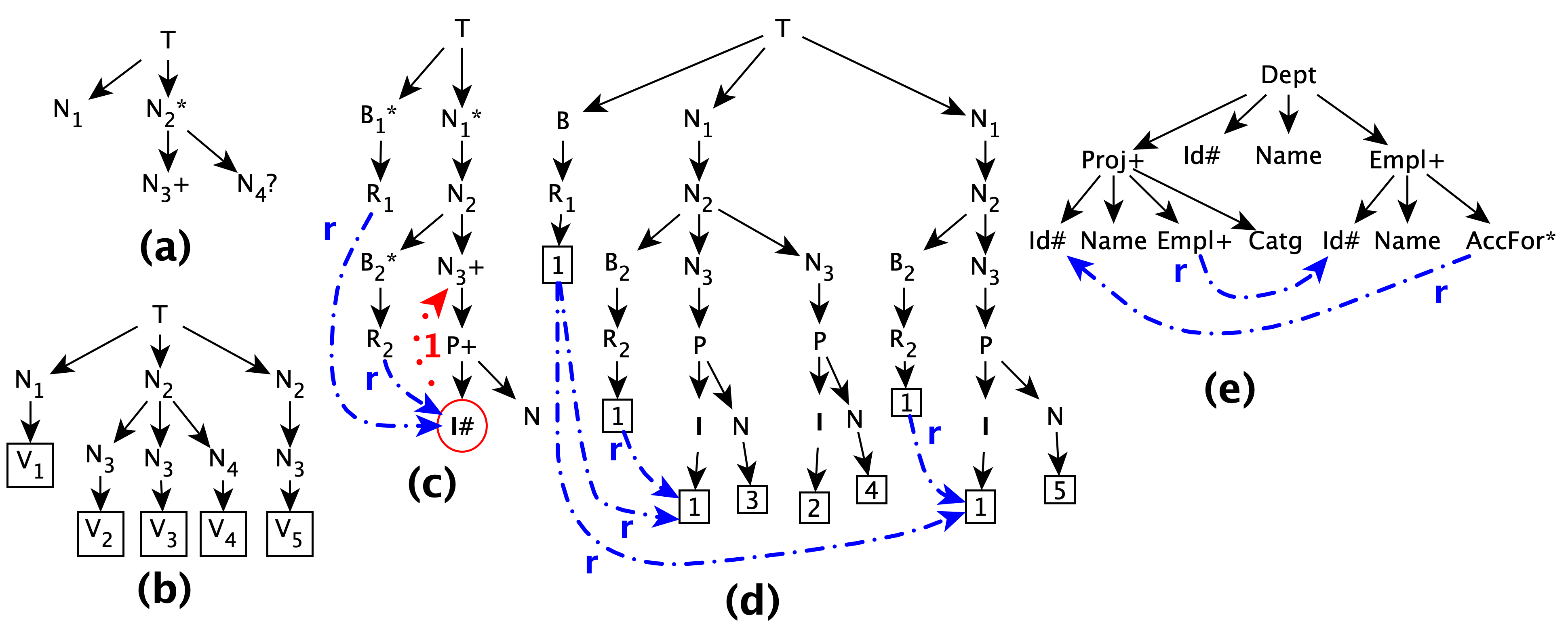
본 논문에서는 현재 상용 데이터베이스 시스템들, 예를 들어 구글이 내부에서 활용하고 있는 Dremel, 대규모 온라인 광고 분석에 특화된 F1, 그리고 최근 각광받고 있는 JSON 기반 스토어와 같이 널리 채택되고 있는 트리 구조(tree‑structured) 데이터 모델을 연구 대상으로 삼는다. 이러한 트리 구조는 전통적인 관계형 테이블 형식과 달리, 하나의 레코드가 계층적이고 중첩된 형태를 띠며, 각 노드가 자식 노드를 가질 수 있는 다중 레벨의 중첩 구조를 특징으로 한다. 따라서 동일한 레코드 안에서도 서로 다른 깊이(depth)와 위치(position)에 존재하는 데이터 요소들 간에 식별(identity) 및 참조(referential) 제약조건을 정의하고 관리하는 것이 필수적이다.
우리는 먼저 각 트리‑구조 레코드 내부에 존재하는 식별 제약조건을 명시한다. 여기서 식별 제약조건이란, 트리의 특정 노드 혹은 서브트리 전체를 유일하게 구분할 수 있는 키(key) 혹은 식별자(identifier)를 지정함으로써, 동일한 레코드 내에서 중복된 값이 발생하지 않도록 보장하는 규칙을 의미한다. 이러한 식별자는 보통 노드의 경로(path)와 속성(attribute) 값을 결합한 형태로 표현되며, 트리 구조의 특성상 동일한 레벨에 존재하는 서로 다른 서브트리라도 서로 다른 식별자를 가짐으로써 **전역적인 유일성(global uniqueness)**을 확보한다.
다음으로 **참조 무결성 제약조건(referential integrity constraints)**을 정의한다. 참조 제약조건은 한 노드가 다른 노드(또는 다른 레코드)의 식별자를 외래키(foreign key) 형태로 참조할 때, 해당 외래키가 실제로 존재하는 유효한 식별자와 일치해야 함을 보장한다. 트리 구조에서는 이러한 참조가 부모‑자식 관계(parent‑child relationship) 뿐만 아니라, 형제‑형제 관계(sibling‑sibling) 혹은 다중 레벨을 가로지르는 교차 참조(cross‑level reference) 형태로도 나타날 수 있다. 따라서 전통적인 관계형 데이터베이스에서와 동일하게, 참조 무결성을 유지하기 위해서는 삽입(insert), 삭제(delete), 갱신(update) 연산 시마다 해당 제약조건을 검사하고 위반이 발생하면 오류를 반환하거나 자동으로 정정하는 메커니즘이 필요하다.
본 논문에서 채택한 **질의 언어(query language)**는 표준 SQL을 기반으로 하면서도 트리‑구조 데이터를 효과적으로 다루기 위해 몇 가지 확장을 가미한 **SQL 변형(variant)**이다. 구체적으로는 중첩된 SELECT 절, 경로 기반의 프로젝션(path‑based projection), 그리고 플랫(flat) 형태로 변환하는 flatten 연산자 등을 포함한다. 여기서 flatten 연산자는 트리 구조의 중첩된 데이터를 일련의 행(row) 형태로 풀어내어, 기존 관계형 엔진이 이해하고 처리할 수 있는 형태로 변환하는 역할을 수행한다. 이러한 변환 과정은 트리 구조의 복잡성을 일시적으로 감소시키지만, 동시에 제약조건을 고려한 정확한 변환 로직이 요구된다.
우리는 이러한 **제약조건이 존재하는 상황에서의 질의 수행(querying in the presence of these constraints)**을 심도 있게 조사한다. 구체적으로는 다음과 같은 두 가지 주요 질문에 초점을 맞춘다. 첫째, 제약조건을 질의 최적화 단계에 어떻게 통합할 것인가이다. 예를 들어, 특정 노드가 반드시 존재한다는 식별 제약조건이 사전에 알려져 있다면, 불필요한 존재 여부 검사(existence check)를 생략함으로써 실행 계획(execution plan)을 간소화할 수 있다. 반면에, 외래키 기반의 참조 제약조건이 존재할 경우, 조인(join) 연산을 수행하기 전에 해당 외래키가 유효한지 사전 검증(pre‑validation)하는 절차가 필요할 수 있다.
둘째, **제약조건을 고려한 평가 메커니즘(evaluation mechanism)**이 실제 실행 시 어떤 **새로운 도전 과제(challenges)**를 야기하는가이다. 첫 번째 도전 과제는 플랫(flat) 변환 과정에서 발생하는 제약조건 위반 검출이다. 트리 데이터를 flatten 하면서 원래 트리 구조가 유지하고 있던 계층적 관계가 사라지기 때문에, 외래키가 가리키는 대상이 동일한 플랫 테이블 내에 존재하는지 여부를 실시간으로 확인해야 한다. 두 번째 도전 과제는 동시성(concurrency) 제어와 무결성 유지이다. 다수의 사용자가 동시에 트리 구조에 삽입·삭제·갱신 작업을 수행할 경우, 식별 제약조건이나 참조 제약조건이 일시적으로 위배되는 상황이 발생할 수 있다. 이를 방지하기 위해서는 잠금(lock) 전략이나 **낙관적 병행 제어(optimistic concurrency control)**와 같은 고급 동시성 제어 기법을 트리‑특화 형태로 설계해야 한다. 세 번째 도전 과제는 **쿼리 최적화기(query optimizer)**가 제약조건 정보를 얼마나 효과적으로 활용할 수 있느냐이다. 기존 관계형 최적화기에서는 기본 키(primary key)와 외래키 정보를 활용해 조인 순서를 결정하거나 인덱스 사용을 판단한다. 그러나 트리 구조에서는 동일한 레코드 내에 다중 레벨의 식별자와 참조가 얽혀 있기 때문에, 이러한 정보를 추출하고 활용하는 로직이 훨씬 복잡해진다.
결론적으로, 본 논문은 트리‑구조 레코드 내부에 정의된 식별 및 참조 제약조건을 명확히 규정하고, 이를 기반으로 SQL 기반의 질의 언어와 flatten 연산자를 활용한 평가 메커니즘을 설계·분석한다. 또한, 이러한 제약조건을 질의 평가 과정에 통합할 때 발생하는 제약조건 위반 검출, 동시성 제어, 최적화 전략 등 여러 측면에서의 어려움을 체계적으로 제시함으로써, 향후 트리‑구조 데이터를 효율적으로 다루는 데이터베이스 시스템 설계에 중요한 이론적·실용적 토대를 제공한다.