Augmented Replay Memory in Reinforcement Learning With Continuous Control
Online reinforcement learning agents are currently able to process an increasing amount of data by converting it into a higher order value functions. This expansion of the information collected from the environment increases the agent's state space e…
Authors: Mirza Ramicic, Andrea Bonarini
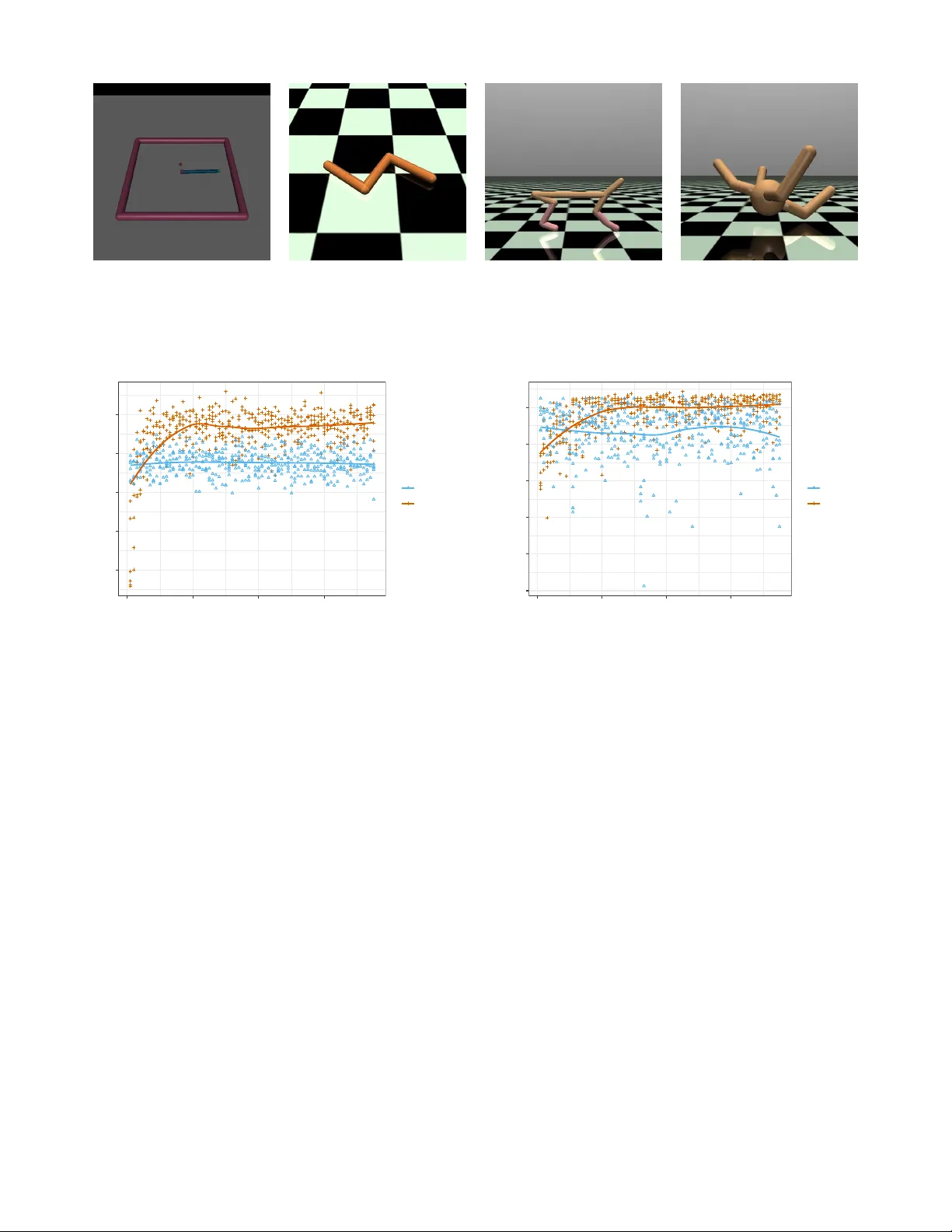
A ugmented Replay Memory in Reinf or cement Learning W ith Continuous Contr ol Mirza Ramicic 1 ∗ , Andrea Bonarini 2 , 1 Artificial Intelligence Center Faculty of Electrical Engineering Czech T echnical Uni versity in Prague Prague, Czech Republic 2 AI and Robotics Lab Dipartimento di Elettronica, Informazione e Bioingegneria Politecnico di Milano Milan, Italy ramicmir@fel.cvut.cz, andrea.bonarini@polimi.it Abstract Online reinforcement learning agents are currently able to process an increasing amount of data by con verting it into a higher order value functions. This expansion of the information collected from the en vironment increases the agent’ s state space enabling it to scale up to a more complex problems but also increases the risk of forgetting by learning on redundant or conflicting data. T o improv e the approximation of a large amount of data, a random mini-batch of the past experiences that are stored in the replay memory buf fer is often replayed at each learning step. The proposed work takes in- spiration from a biological mechanism which act as a protectiv e layer of human brain higher cogni- tiv e functions: activ e memory consolidation miti- gates the ef fect of forgetting of pre vious memories by dynamically processing the ne w ones. The sim- ilar dynamics are implemented by a proposed aug- mented memory replay AMR capable of optimizing the replay of the experiences from the agent’ s mem- ory structure by altering or augmenting their rele- vance. Experimental results sho w that an ev olved AMR augmentation function capable of increasing the significance of the specific memories is able to further increase the stability and con ver gence speed of the learning algorithms dealing with the com- plexity of continuous action domains. 1 Introduction Studies concerning human and animal learning hav e identi- fied that the process of encoding new memories into long term storage is not so straightforward as previously thought. Re- cent studies hav e found that it inv olves a process of active memory consolidation, or AMC [ 1; 2; 3 ] , that facilitates a better memory inte gration into the higher le vel cortical struc- tures and also prevents forgetting previously encoded infor- ∗ Contact Author mation. This process occurs while sleeping, a time when the brain is not encoding or percei ving new stimuli and relies on the memories stored in a short-term hippocampal structure when aw ake. Before their integration in the long term corti- cal structures, experiences are reactiv ated or replayed in the hippocampal memory as a part of the active consolidation. The word “activ e” in AMC implies that, in the process of consolidation, memories are altered in a way that their fur- ther inte gration into the existing knowledge wouldn’t induce forgetting of the pre vious ones. The acti ve structural modification of the consolidated memories is selecti ve and, for the memories that are deemed to be the more important ones it will f acilitate strengthening to reach a certain retrie v al threshold. Ho wever , if the memory trace is deemed not strong enough for some memories it will result in their loss [ 4; 5 ] . Biological architectures found in human brain and the computational reinforcement learning processes both use a functionally similar mechanism of replay memory . Along the introduction of artificial neural networks, or ANN, as function approximators in temporal-dif ference, or TD, learn- ing [ 6 ] , the techniques that aim at their ef ficient training most commonly use a replay buf fer of previous experiences out of which a mini-batch is sampled for re-learning at each time step. This technique has been recently revi ved in Deep Q- learning [ 7; 8 ] . Since in TD approaches the ANN is con- stantly updated to better represent the state-action v alue pairs Q ( s, a ) , which gov ern the agent’ s policy π , the mechanisms in volv ed in its training such as mini-batch replay became in- creasingly influential to the learning process itself. Another adv antage of the replay memory structure is that, when implemented, it acts as a form of agent’ s cognition: de- pending on the way it is populated, it can alter ho w the agent perceiv es the information. In this w ay , a learning agent is not only concerned about the information it receiv es from its im- mediate en vironment, but also about the way in which this information is interpreted by this cognitiv e mechanism. In the proposed approach an effecti ve, but simple, mecha- nism of replay memory is extended with the ability to acti vely and dynamically process the information during the replay and thus bringing it closer to the functional characteristics of actual biological mechanisms. The dynamic processing mechanism of A ugmented Memory Replay or AMR presented here is inspired by human active memory consolidation and it is capable of altering the importance of specific memories by altering their re ward values, thus mimicking the AMC’ s process of deeming the memory abov e the retriev al thresh- old. In the experiments reported in this paper , the augmenta- tion dynamics are ev olved over generations of learning agents performing reinforcement learning tasks in various environ- ments. Their fitness function is defined in a straightforward way as their cumulati ve performance ov er a specific en viron- ment. Experimental results indicate that AMR type of mem- ory buf fer sho ws an improv ement in learning performance ov er the standard static replay method in all of the tested en- vironments. 2 Related W ork An extension of DDPG algorithm was proposed by Hausknecht and Stone [ 9 ] allowing it to deal with a lo w le vel parameterized-continouos action space. Ho wev er the ev alua- tion of the approach was limited to a single simulated envi- ronment of RoboCup 2D Half-Field-Offense [ 10 ] . Hoothoft et. al [ 11 ] proposed a meta-learning approach capable of ev olving a specialized loss function for a specific task dis- tribution that would provide higher rew ards during its min- imization by stochastic gradient descent. The algorithm is capable to produce a significant improv ement of the agent’ s con ver gence to the optimal policy but as its the case with the AMR approach the ev olved impro vements are task specific. In contrast with the distributed methods like Apex which was proposed by Horg an et. al [ 12 ] which rely on a hundreds of actors learning in their o wn instance of the en vironment AMR algorithm works with a single instance just like vanilla DDPG [ 13 ] does. This fact has a significant impact on the computational time a specific algorithm induces to the prob- lem. W ang et. al [ 14 ] introduced an approach that is combining the importance or prioritized sampling techniques together with stochastic dueling networks in order to improv e the con- ver gence of some continuous action tasks such as Cheetah, W alker and Humanoid. Another improv ement of a vanilla DDPG is presented by Dai et. al [ 15 ] as Dual-Critic architecture where the critic is not updated using the standard temporal-difference algo- rithms b ut it’ s optimized according to the gradient of the ac- tor . An approach by P acella et. al [ 16 ] ev olved basic emotions such as fear, used as a kind of motiv ational dri ve that gov- erned the agent’ s behavior by directly influencing action se- lection. Similar to the AMR approach a population of virtual agents were tested at each generation. In this process, each of the agents e volv ed a specific neural network that w as capa- ble of selecting its actions based on the input; this consisted of temporal information, visual perception and good and bad sensation neurons. Over time, the selection of best perform- ing agents ga ve rise to populations that adopted specific be- havioral driv es such as being cautious or fearful as a part of a surviv al strategy . Contrary to the AMR which ev olves a cog- nitiv e mechanism which only complements the main learning process, in [ 16 ] the genetic algorithm represents the learning process itself. Another e volutionary approach that is used to comple- ment the main reinforcement learning algorithm was pre- sented in [ 17 ] . Similarly to AMR , it uses a genetic algorithm to ev olve an optimal r ewar d function which builds upon the basic rew ard function in a way that maximizes the agent’ s fitness o ver a distrib ution of environments. Experimental re- sults show the emergence of an intrinsic rew ard function that supports the actions that are not in line with the primary goal of the agent. [ 18 ] also presented an a reinforcement learn- ing approach which relied on a e volv ed reinforcer in order to support learning atomic meta-skills. The reinforcement was ev olved in a childhood phase, which equipped the agents with the meta-actions or skills for the use in the adulthood phase. Persiani et al. [ 19 ] proposes a cogniti ve improv ement through the use of replay memory structure like AMR . The algorithm makes it possible to learn which chunks of agent’ s experiences are most appropriate for replay based on their ability to maximize the future expected re ward. A cogniti ve filter structure was proposed by Ramicic and Bonarini [ 20 ] able to improve the conv ergence of temporal- difference learning implementing discrete control rather than a continuous one. It was able to e volv e the ANN capable to select whether a specific experience will be sampled into replay memory or not. Unlike AMR this approach did not modify the properties of the experiences. 3 Theoretical Backgr ound 3.1 T emporal-difference learning The goal of a reinforcement learning agent is to constantly update the function which maps its state to their actions i.e. its polic y π as close as possible to the optimal policy π ∗ . The optimal policy is a policy that selects the actions which maximize the future expected reward of an agent in the long run [ 21 ] and it is represented by a function, possibly approx- imated by an Artificial Neural Network or ANN. The pro- cess of updating the policy is performed iterati vely after each of the consecutiv e discrete time-steps in which the agent in- teracts with its environment by executing its action a t and gets the immediate re ward scalar r t defined by the r einforce- ment function . This iterativ e step is defined as a transition ov er Marko v Decision Process , and represented it by a tuple ( s t , a t , r t , s t +1 ) . After each transition the agent corrects its existing policy π according to the optimal action-value func- tion sho wn in Equation 1 in order to maximize its expected rew ard within the existing policy . In the approaches that deal with discrete action spaces, such as [ 22 ] , the agent can fol- low the optimal policy π ∗ by taking an optimal action a ∗ ( s ) which maximizes the optimal action-value function Q ∗ ( s, a ) defined by Equation 2. Q ∗ ( s, a ) = max π E [ R t | s t = s, a t = a, π ] (1) µ ( s ) = a ∗ ( s ) = max a Q ∗ ( s, a ) (2) Q π ( s, a ) = E h r + γ max a 0 Q π ( s 0 , a 0 ) | s, a i (3) The correction update to the policy π starts by determining how wrong the current policy is with respect to the expecta- tion, or v alue for the current state-action pair Q ( s, a ) . In case of a discrete action space this e xpectation of return is defined by the Bellman-optimality equation Equation 3 and it is basi- cally the sum of the immediate rew ard r and the discounted prediction of a maximum Q-value, gi ven the state s ‘ o ver all of the possible actions a ‘ . 3.2 Going continuous Maximizing ov er actions in Equation 2 is not a problem when facing discrete action spaces, because the Q-v alues for each of the possible actions can be estimated and compared. Ho w- ev er , when coping with continuous action values this ap- proach is not realistic: we cannot just explore brute force the values of the whole action space in order to find the maxi- mum. The more recent approach of [ 13 ] eliminates the maxi- mization problem by approximating the optimal action a ∗ ( s ) and thus creating a deterministic policy µ ( s ) in addition to the optimal state-value function Q ∗ ( s, a ) . T aking the ne w ap- proximated policy into consideration the Bellman-optimality equation takes the form of Equation 4 and av oids the inner expectation. Q µ ( s, a ) = E [ r + γ Q µ ( s 0 , µ ( s 0 )) | s, a ] (4) In common among all the before mentioned approaches is the concept of temporal differ ence , or TD error, which is ba- sically a dif ference between the current approximate predic- tion and the expectation of the Q v alue. The learning process performs an iterative reduction of a TD error using Bellman- optimality equation as a target, which guarantees the con ver - gence of the agent’ s polic y to the optimal one giv en an infinite amount of steps [ 21 ] . 3.3 Function approximation In order to deal with the increasing dimensionality and con- tinuous nature of state and action spaces imposed by the real-life applications the aforementioned algorithms depend heavily on approximate methods usually implemented using ANN. A primary function approximation makes it possible to predict a Q value for each of the possible actions av ail- able to the agent by providing an agent’ s current state as in- put of the ANN. After each time step, the expected Q value is computed using Equation 4, and then compared to the es- timate that the function approximator provides as its output Q ( s, a ; Θ) ≈ Q ∗ ( s, a ) by forwarding the state s0 as its input. The dif ference between the pre vious estimate of the approx- imator and the e xpectation is the TD error . This discrepanc y is actually a loss function L i (Θ i ) that can bi minimized by performing a stochastic gradient descent on the parameters Θ in order to update the current approximation of Q ∗ ( s, a ) according to Equation 5: ∇ Θ i L i (Θ i ) = ( y i − Q ( s, a ; Θ i )) ∇ Θ i Q ( s, a ; Θ i ) , (5) where y i = r + γ Q µ ( s 0 , µ ( s 0 )); Θ i − 1 ) is in fact the Bellman equation defining the target value which depends on an yet another ANN that approximates the policy function µ ( s ) in policy-gradient approaches such as [ 13 ] . The update to the policy function approximator µ Θ ( s ) is more straightforward as it is possible to perform a gradient ascent on the respecti ve network parameters Θ in order to maximize the Q µ ( s, a ) as shown in Equation 6. max θ E s ∼D [ Q µ ( s, µ θ ( s ))] (6) 4 Model Architectur e and Lear ning Algorithm In this section we propose a new model that combines the learning approaches of genetic algorithm with reinforcement learning order to improve the conv ergence of the latter . For clarity , the proposed model is separated in two main func- tional parts: ev aluation and e volution. The e v aluation part is defined as a temporal-dif ference re- inforcement problem where a rew ard function is dynamically modified by the proposed AMR block. AMR is a function ap- proximator implemented by an ANN, which receiv es in input characteristics of experience that is percei ved by the learning agent, and outputs a single scalar value , used to modify the reinforcement value of the transition. The architecture of the AFB neural netw ork approximator ( f ) consists of three layers: three input nodes fully connected to a hidden layer of four nodes, in turn connected to tw o soft- max nodes to produce the final classification. This ANN is able to approximate the four parameters of the experience, respectiv ely gi ven in input, as TD error , reinforcement r i , en- tropy of the starting state s t , and entropy of the next transi- tioning state s t +1 , to a regression output layer that provides a scalar augmentation value or A t ( s t , s t +1 , r t ) . The augmen- tation process alters the re ward v alue of each transition by an augmentation rate or β as sho wn in Equation 7. r t := r t + β A t (7) While altering the re ward scalar r t the AMR block is able to precisely and dynamically change the amount of influence each transition ex erts on the learning process ant thus mimic the aforementioned biological processes [ 1; 2; 3 ] . The second component of the proposed architecture ev olves the AMR block using a genetic algorithm , or GA , in order to maximize its fitness function which is represented by the total learning score received by an agent during its ev alu- ation phase. 5 Experimental Setup 5.1 En vir onment The ev aluation phase applied the proposed variations of the D DP G learning algorithm to a variety of continuous con- trol tasks running on an efficient and realistic physics simu- lator as a part of OpenAI Gym framework [ 23 ] and shown in Figure ?? . The considered en vironments range from a relativ ely simple 2D robot ( Reacher -v2 ), with a humble 11- dimensional state space, to a complex four-legged 3D robot Figure 1: General learning model architecture including the attention focus block : ( a ) Replay memory implemented as a sliding windo w buf fer of N experiences; ( b ) Main learning loop which consists of: 1) the transition in which the agent performs an action, receiving an immediate re ward r t , while transitioning to a next state s t +1 ; 2) performing an update on main function approximator ANN ( d ) by back propagating the TD error as a gradient of the a t output; 3) shifting the states for the next iteration in which the s t becomes our s t +1 ; 4) Updating deterministic policy µ ( s ) by changing the weights Θ µ of the actor ANN approximator ( e ) ; 5) Getting the next action a t +1 which maximizes the Q value for the given state s t according to the actor ANN ( d ) A block implementing Q-v alue function approximator taking the starting state s t on the input and pre dicting Q-v alues for each of the av ailable actions on its output; ( c ) Raw stream of the experiences that are perceived representing unfiltered cognition of an agent; ( f ) Augmented Memory Replay block consisting of an ANN that approximates the augmentation parameter A i based on the properties of the experience. such as Ant-v2 [ 24 ] , which boasts a total of 111-dimensional states coupled with 8 possible continuous actions. V arious different tasks of intermediate complexity like making a 2D animal robot run ( HalfCheetah-v2 ), and making a 2D snake- like robot mov e on a flat surface ( Swimmer -v2 [ 25 ] ) hav e also be faced. 5.2 Function Appr oximation An approximation of Q ( s, a ; Θ) ≈ Q ∗ ( s, a ) has been imple- mented using an ANN with one hidden fully connected layer of 50 neurons, able to take an agent’ s state as an input and produce as output the Q v alues of all the actions av ailable to the agent. The learning rate of an critic Q approximator α is set to 0 . 002 . The actor function approximator of a ( s ; Θ) ≈ a ∗ ( s ) is im- plemented using one hidden dense layer of 30 neurons which outputs a deterministic action policy based on the agent’ s cur- rent state. The actor ANN has been trained using slightly higher learning rate of 0 . 001 compared to the critic one. The architecture of the AMR function approximator con- sists of three layers: four input nodes connected to a fully connected hidden layer of four nodes, in turn connected to a single regression node able to produce an augmentation scalar as output. This ANN is able to approximate four pa- rameters of the current agent’ s experience, respecti vely giv en in input as an absolute value of TD error , reinforcement, en- tropy of the starting state s t , entropy of the transitioning state s t +1 , to scalar v alue A t that indicates ho w important the spe- cific experience it to the learning algorithm. Figure 2: Main function approximator ANN implemented in the (d) block of Figure 1: it receiv es an N-dimensional state as its input and approximates it to Q v alues of each of A possible actions av ailable to an agent at its output, therefore providing an approximation for Q ( s, a ) pairs. 5.3 Meta Learning Parameters During the e v aluations phase at each learning step a batch of 32 experiences were replayed from the fixed capacity mem- ory buf fer of 10000. Learning steps per episode were limited to a maximum of 2000. Reward discount factor γ was set to a high 0 . 9 and soft replacement parameter τ was 0 . 01 . In order to achie ve action space exploration an artificially gener- ated noise is added to the deterministic action polic y which is approximated by the actor ANN. The noise is gradually de- creased or adjusted linearly from an initial scalar v alue 3 . 0 to 0 . 0 to wards the end of the learning. 6 Experimental Results The proposed algorithm ev olved the AMR’s neural network weights Θ AM R trough a total of 75 generations. At each generation, the learning performance of 10 agents were e v al- uated based on their their total cumulativ e score during 200 learning episodes. Only the best 5 scoring agents of each generation had an opportunity to propagate their genotypes to the next generation in order to form a new population. As shown in ?? this process inv olved common GA techniques such as crossov er and random mutation. The crossover of the genotypes, which are actually the AMR weights, were pri- oritized based on the agents cumulativ e score and the mu- tation was additionally applied at a rate of 0 . 25 by adding a random scalar between 0 . 1 and − 0 . 1 to the weights. The obtained experimental results which are presented along the Figures 8, 9, 10, 11 indicate that the most complex setup of Ant-v2 improved its learning performance the most when us- ing the proposed AMR approach when compared to the base- line approach that ha ve not used memory augmentation . Re- gardless of the en vironment, it i evident that the proposed ev olutionary approach with memory augmentation underper - forms at the very first generations but quickly surpasses the baseline in less than 10 generations and further improves Algorithm 1 DDPG with Augmented Memory Initialize critic network Q ( s, a | Θ Q ) , actor network µ ( s | Θ µ ) and augmentation network A ( s, r | Θ β ) with ran- dom weights Θ Q , Θ µ and Θ β Initialize target network Q 0 and µ 0 with weights Θ Q 0 ← Θ Q and Θ µ 0 ← Θ µ Initialize replay buf fer R for episode = 1, M do Initialize a random process N for action exploration Observe initial state s 1 for t=1, T do Select action a t = µ ( s t | Θ µ ) + N t according to the current policy and e xploration noise Execute action a t and observ e re ward r t and ne w state s t +1 Augment the rew ard r t ← r t + A t ( s t , s t +1 , r t ) ac- cording to the augmentation network parameters Θ β Store transition ( s t , a t , r t , s t +1 ) in R Sample a random minibatch of S transitions ( s t , a t , r t , s t +1 ) from R Set y i = r i + γ Q 0 ( s i +1 , µ 0 ( s i +1 | Θ µ 0 ) | Θ Q 0 ) Update critic by minimizing the loss L = 1 S P i ( y i − Q ( s i , a i | Θ Q 0 )) 2 Update the actor policy using the sampled policy gra- dient ∇ Θ µ J ≈ 1 S P i ∇ a Q ( s, a | Θ Q ) | s = s i ,a = µ ( s i ) ∇ Θ µ µ ( s | Θ µ ) | s i Update the networks Θ Q 0 ← τ Θ Q + (1 − τ )Θ Q 0 Θ µ 0 ← τ Θ µ + (1 − τ )Θ µ 0 end f or end f or the total score of the agent in the follo wing generations. As we can see from 8 the AMR e volutionary approach im- prov es the Ant’s quad-le gged robot learning about how to walk by a total of 18 . 9% towards the end of the 75th gen- eration. AMR algorithm have also sho wed a significant im- prov ement in Reacher : the simplest of the en vironments. In this task the proposed evolutionary approach made the 2D robot hand with one actuating joint learn to fetch a randomly instantiated target faster and produced a 35 . 4% increase in agent’ s total cumulativ e score. Although not as significant as in Ant and Reacher setups, the AMR approach is also able to improv e the performance in the Cheetah and Swim- mer environments as evident from the Figure 10 and Fig- ure 11, respectiv ely . W e can also notice the difference of the score variance between the setups which can be attrib uted to distinctiv e robot/environment characteristics; while Ant and Reacher show relati vely low variance in their scores, other problems like Cheetah and Swimmer have a very high vari- ance. Figure 3: Reacher Figure 4: Swimmer Figure 5: Half Cheetah Figure 6: Ant Figure 7: V ariety of OpenAI Gym en vironments considered in e valuation. Ordered from low to high complexity . 200 300 400 500 600 0 20 40 60 Generation A verage Score of Agents sampling BASE EVOLUTION Figure 8: A verage score or total reinforcement in Ant en vironment receiv ed ov er 75 generations of learning agents. 7 Discussion The presented approach represents yet another inspiration from biological systems, which implements a biologically in- spired mechanisms that enables artificial learning agents to better adapt to a specific en vironment by selectiv ely increas- ing the relev ance of the information perceiv ed. An agent im- plementing an AMR neural network is able to e v olve its mem- ory augmentation criteria to best fit the en vironment that is facing, in few generations. The ev olved AMR’ s augmenta- tion criteria modifies the rele v ance of the information that an agents collects from its immediate en vironment into its replay memory allowing it to use the same data in a more efficient way during the learning process; this yields a direct impro ve- ment in the performance. Thus, augmenting memory allows for the emer gence of an artificial cognition as a intermediary dynamic filtering mech- anism in learning agents, which opens a possibility for a v a- riety of applications in the future. −700 −600 −500 −400 −300 −200 0 20 40 60 Generation A verage Score of Agents sampling BASE EVOLUTION Figure 9: A verage score or total reinforcement in Reacher environ- ment receiv ed ov er 75 generations of learning agents. 8 References References [ 1 ] S. Diekelmann and J. Born, “The memory function of sleep, ” Natur e Revie ws Neur oscience , vol. 11, no. 2, p. 114, 2010. [ 2 ] B. Rasch and J. Born, “ About sleep’ s role in mem- ory , ” Physiological r eviews , v ol. 93, no. 2, pp. 681–766, 2013. [ 3 ] G. B. Feld and S. Diekelmann, “Sleep smart—optimizing sleep for declarativ e learning and memory , ” F r ontiers in psychology , vol. 6, p. 622, 2015. [ 4 ] N. Dumay , “Sleep not just protects memories against forgetting, it also makes them more accessible, ” Corte x , vol. 74, pp. 289–296, 2016. [ 5 ] T . Schreiner and B. Rasch, “T o gain or not to gain–the complex role of sleep for memory , ” Corte x , v ol. 101, pp. 282–287, 2018. [ 6 ] L.-J. Lin, “Reinforcement learning for robots using neu- ral networks, ” DTIC Document, T ech. Rep., 1993. −200 0 200 0 20 40 60 Generation A verage Score of Agents sampling BASE EVOLUTION Figure 10: A verage score or total reinforcement in Cheetah en viron- ment receiv ed ov er 75 generations of learning agents. 20 25 30 0 20 40 60 Generation A verage Score of Agents sampling BASE EVOLUTION Figure 11: A verage score or total reinforcement in Swimmer envi- ronment receiv ed ov er 75 generations of learning agents. [ 7 ] V . Mnih, K. Kavukcuoglu, D. Silver , A. Grav es, I. Antonoglou, D. W ierstra, and M. Riedmiller , “Playing atari with deep reinforcement learning, ” arXiv pr eprint arXiv:1312.5602 , 2013. [ 8 ] V . Mnih, K. Kavukcuoglu, D. Silver , A. A. Rusu, J. V e- ness, M. G. Bellemare, A. Grav es, M. Riedmiller , A. K. Fidjeland, G. Ostrovski et al. , “Human-le vel control through deep reinforcement learning, ” Natur e , vol. 518, no. 7540, pp. 529–533, 2015. [ 9 ] M. Hausknecht and P . Stone, “Deep reinforcement learning in parameterized action space, ” arXiv pr eprint arXiv:1511.04143 , 2015. [ 10 ] M. Hausknecht, P . Mupparaju, S. Subramanian, S. Kalyanakrishnan, and P . Stone, “Half field offense: An en vironment for multiagent learning and ad hoc teamwork, ” in AAMAS Adaptive Learning Ag ents (ALA) W orkshop , 2016. [ 11 ] R. Houthooft, Y . Chen, P . Isola, B. Stadie, F . W olski, O. J. Ho, and P . Abbeel, “Evolved policy gradients, ” in Advances in Neural Information Pr ocessing Systems , 2018, pp. 5400–5409. [ 12 ] D. Horg an, J. Quan, D. Budden, G. Barth-Maron, M. Hessel, H. V an Hasselt, and D. Silver , “Dis- tributed prioritized experience replay , ” arXiv pr eprint arXiv:1803.00933 , 2018. [ 13 ] T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver , and D. W ierstra, “Continuous con- trol with deep reinforcement learning, ” arXiv preprint arXiv:1509.02971 , 2015. [ 14 ] Z. W ang, V . Bapst, N. Heess, V . Mnih, R. Munos, K. Kavukcuoglu, and N. de Freitas, “Sample ef fi- cient actor -critic with experience replay , ” arXiv preprint arXiv:1611.01224 , 2016. [ 15 ] B. Dai, A. Shaw , N. He, L. Li, and L. Song, “Boosting the actor with dual critic, ” arXiv preprint arXiv:1712.10282 , 2017. [ 16 ] D. P acella, M. Ponticorvo, O. Gigliotta, and O. Miglino, “Basic emotions and adaptation. a computational and ev olutionary model, ” PLoS one , v ol. 12, no. 11, p. e0187463, 2017. [ 17 ] S. Singh, R. L. Lewis, A. G. Barto, and J. Sor g, “Intrin- sically moti vated reinforcement learning: An e volution- ary perspectiv e, ” IEEE T ransactions on Autonomous Mental Development , v ol. 2, no. 2, pp. 70–82, 2010. [ 18 ] M. Schembri, M. Mirolli, and G. Baldassarre, “Evolu- tion and learning in an intrinsically motiv ated reinforce- ment learning robot, ” in Eur opean Conference on Arti- ficial Life . Springer , 2007, pp. 294–303. [ 19 ] M. Persiani, A. M. Franchi, and G. Gini, “ A working memory model improves cognitiv e control in agents and robots, ” Cognitive Systems Resear ch , vol. 51, pp. 1–13, 2018. [ 20 ] M. Ramicic and A. Bonarini, “Selectiv e perception as a mechanism to adapt agents to the environment: An ev olutionary approach, ” IEEE T ransactions on Cogni- tive and Developmental Systems , 2019. [ 21 ] R. S. Sutton and A. G. Barto, Reinforcement learning: An intr oduction . MIT press Cambridge, 1998, vol. 1, no. 1. [ 22 ] C. J. W atkins and P . Dayan, “Q-learning, ” Machine learning , vol. 8, no. 3-4, pp. 279–292, 1992. [ 23 ] G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schulman, J. T ang, and W . Zaremba, “Openai gym, ” 2016. [ 24 ] J. Schulman, P . Moritz, S. Le vine, M. Jordan, and P . Abbeel, “High-dimensional continuous control us- ing generalized adv antage estimation, ” arXiv pr eprint arXiv:1506.02438 , 2015. [ 25 ] R. Coulom, “Reinforcement learning using neural net- works, with applications to motor control, ” Ph.D. dis- sertation, Institut National Polytechnique de Grenoble- INPG, 2002.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment