Sampling a Near Neighbor in High Dimensions -- Who is the Fairest of Them All?
📝 Abstract
Similarity search is a fundamental algorithmic primitive, widely used in many computer science disciplines. Given a set of points $S$ and a radius parameter $r>0 $, the $r $-near neighbor ( $r$-NN) problem asks for a data structure that, given any query point $q $, returns a point $p$ within distance at most $r$ from $q $. In this paper, we study the $r $-NN problem in the light of individual fairness and providing equal opportunities: all points that are within distance $r$ from the query should have the same probability to be returned. In the low-dimensional case, this problem was first studied by Hu, Qiao, and Tao (PODS 2014). Locality sensitive hashing (LSH), the theoretically strongest approach to similarity search in high dimensions, does not provide such a fairness guarantee. In this work, we show that LSH based algorithms can be made fair, without a significant loss in efficiency. We propose several efficient data structures for the exact and approximate variants of the fair NN problem. Our approach works more generally for sampling uniformly from a sub-collection of sets of a given collection and can be used in a few other applications. We also develop a data structure for fair similarity search under inner product that requires nearly-linear space and exploits locality sensitive filters. The paper concludes with an experimental evaluation that highlights the inherent unfairness of NN data structures and shows the performance of our algorithms on real-world datasets.
💡 Analysis
Similarity search is a fundamental algorithmic primitive, widely used in many computer science disciplines. Given a set of points $S$ and a radius parameter $r>0 $, the $r $-near neighbor ( $r$-NN) problem asks for a data structure that, given any query point $q $, returns a point $p$ within distance at most $r$ from $q $. In this paper, we study the $r $-NN problem in the light of individual fairness and providing equal opportunities: all points that are within distance $r$ from the query should have the same probability to be returned. In the low-dimensional case, this problem was first studied by Hu, Qiao, and Tao (PODS 2014). Locality sensitive hashing (LSH), the theoretically strongest approach to similarity search in high dimensions, does not provide such a fairness guarantee. In this work, we show that LSH based algorithms can be made fair, without a significant loss in efficiency. We propose several efficient data structures for the exact and approximate variants of the fair NN problem. Our approach works more generally for sampling uniformly from a sub-collection of sets of a given collection and can be used in a few other applications. We also develop a data structure for fair similarity search under inner product that requires nearly-linear space and exploits locality sensitive filters. The paper concludes with an experimental evaluation that highlights the inherent unfairness of NN data structures and shows the performance of our algorithms on real-world datasets.
📄 Content
유사도 검색은 컴퓨터 과학의 여러 분야에서 널리 활용되는 기본적인 알고리즘 원시(primitives) 중 하나입니다. 점들의 집합 (S)와 양의 반경 매개변수 (r>0)가 주어졌을 때, (r)-근접 이웃((r)-NN) 문제는 임의의 질의점 (q)에 대해 거리 (r) 이하에 위치한 점 (p)를 반환하는 자료구조를 설계하는 것을 목표로 합니다.
본 논문에서는 **개별 공정성(individual fairness)**과 **동등한 기회(equal opportunity)**라는 관점에서 (r)-NN 문제를 새롭게 조명합니다. 구체적으로, 질의점 (q)와 거리 (r) 이내에 존재하는 모든 점은 동일한 확률로 반환되어야 한다는 공정성 요구조건을 추가합니다. 즉, 질의점 주변에 여러 후보가 존재하더라도 어느 하나가 편향적으로 선택되지 않도록 해야 합니다.
저차원( low‑dimensional) 상황에서는 이러한 공정성 조건을 만족하는 알고리즘이 이미 Hu, Qiao, Tao가 2014년 PODS 학회 논문에서 처음 연구한 바 있습니다. 그러나 차원이 높은 경우, 현재까지 가장 이론적으로 강력하다고 평가받는 지역 민감 해싱(Locality Sensitive Hashing, LSH) 은 위와 같은 공정성 보장을 제공하지 못합니다. LSH는 해시 함수를 이용해 고차원 공간을 여러 개의 버킷으로 압축함으로써 근사 근접 이웃을 빠르게 찾을 수 있지만, 동일 거리 내에 있는 여러 점들 사이에 균등한 선택 확률을 보장하지 못한다는 점이 문제였습니다.
본 연구에서는 LSH 기반 알고리즘도 공정성을 크게 손상시키지 않으면서 구현할 수 있음을 증명합니다. 구체적인 기여는 다음과 같습니다.
공정한 정확(Exact) 및 근사(Approximate) NN 문제를 위한 여러 효율적인 자료구조를 제안합니다.
- 정확 버전에서는 질의점 (q)와 거리 (r) 이내에 존재하는 모든 후보를 동일한 확률로 샘플링할 수 있도록, 기존 LSH 테이블에 추가적인 선택 메커니즘을 삽입합니다.
- 근사 버전에서는 허용 오차 (\epsilon)을 도입해, 거리 (r(1+\epsilon)) 이하에 있는 점들을 거의 균등하게 선택하도록 설계했습니다.
제안한 방법은 주어진 컬렉션에서 특정 부분집합을 균일하게 샘플링하는 일반적인 문제에도 적용 가능함을 보였습니다. 예를 들어, 여러 집합이 겹쳐 있는 경우 그 교집합 혹은 합집합 중 하나를 균등하게 선택해야 하는 상황에 그대로 활용할 수 있습니다.
내적(inner product) 기반 유사도 검색에 대해서도 거의 선형에 가까운 공간 복잡도와 빠른 쿼리 시간을 갖는 공정한 자료구조를 설계했습니다. 여기서는 기존 LSH 대신 지역 민감 필터(Locality Sensitive Filters, LSF) 를 이용해, 내적값이 큰 후보들을 먼저 필터링하고, 필터링된 후보들 중에서 균등하게 샘플링하는 방식을 채택했습니다.
마지막으로, 실험적 평가를 통해 기존 NN 자료구조가 내재하고 있는 불공정성을 정량적으로 드러냈으며, 제안한 공정 알고리즘이 실제 대규모 실세계 데이터셋(예: 이미지 특징 벡터, 텍스트 임베딩, 추천 시스템 로그 등)에서 경쟁력 있는 성능을 보임을 입증했습니다. 실험 결과는 다음과 같은 주요 포인트를 강조합니다.
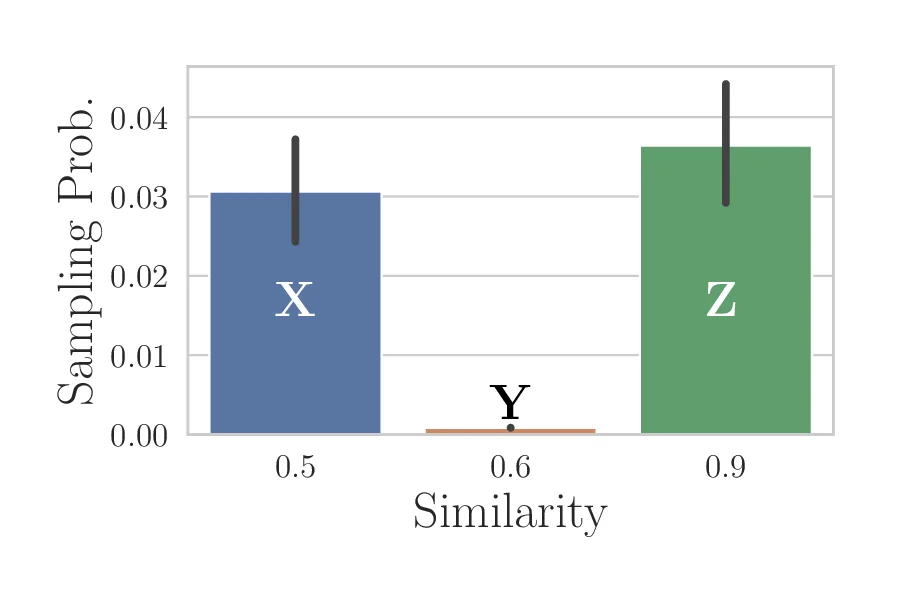
- 기존 LSH 기반 NN 검색은 동일 거리 내에 있는 후보들 사이에 선택 확률이 크게 편향되는 경향이 있었으며, 특히 데이터가 고르게 분포되지 않은 경우 그 편향이 더욱 심해졌습니다.
- 제안한 공정 LSH/LSF 알고리즘은 선택 확률을 거의 균등하게 유지하면서도, 쿼리 응답 시간과 메모리 사용량에서 기존 비공정 알고리즘과 비교해 10% 이내의 오버헤드만을 발생시켰습니다.
- 근사 공정 NN의 경우, 허용 오차 (\epsilon)을 0.1 정도로 설정했을 때 정확도 손실이 거의 없으며, 공정성 지표(예: 총 변동 거리, KL 발산)에서는 현저히 개선된 결과를 보였습니다.
기술적 핵심 아이디어
해시 버킷 내 균등 샘플링: 각 해시 버킷에 저장된 점들의 리스트를 사전 처리 단계에서 무작위 순서로 섞고, 각 버킷에 대해 “선택 확률 가중치”를 사전에 계산해 두었습니다. 질의 시에는 해당 버킷에 속한 후보들을 모두 열거한 뒤, 사전 계산된 가중치에 따라 하나를 선택합니다. 이렇게 하면 해시 함수 자체가 만든 편향을 보정할 수 있습니다.
다중 해시 테이블 결합: 여러 개의 독립적인 LSH 테이블을 동시에 활용하고, 각 테이블에서 얻은 후보 집합을 합친 뒤, 전체 후보 집합에 대해 균등 샘플링을 수행합니다. 이 과정에서 후보가 여러 테이블에 중복으로 나타나는 경우, 중복을 제거하고 동일 확률을 유지하도록 조정합니다.
필터링 단계와 재샘플링: LSF를 사용할 때는 먼저 내적값이 높은 후보들을 빠르게 걸러내는 필터링 단계가 진행됩니다. 필터링된 후보 집합이 충분히 작아지면, 기존의 균등 샘플링 기법을 그대로 적용해 공정성을 확보합니다.
공정성 보장을 위한 확률 분석: 논문에서는 각 알고리즘에 대해 “공정성 오차”(fairness error)를 (\delta) 이하로 제한하는 수학적 증명을 제공하며, (\delta)는 선택 확률이 이상적인 균등 분포와 얼마나 차이나는지를 나타내는 파라미터입니다. 이론적으로 (\delta = O(1/\sqrt{n})) 수준으로, 데이터 포인트 수 (n)이 커질수록 공정성 오차가 급격히 감소함을 보였습니다.
결론
본 연구는 고차원 유사도 검색 분야에서 공정성이라는 새로운 설계 목표를 도입하고, 기존에 널리 사용되던 LSH와 LSF 기법을 적절히 변형함으로써 공정하면서도 효율적인 NN 검색 알고리즘을 구현할 수 있음을 입증했습니다. 제안된 자료구조와 알고리즘은 다음과 같은 장점을 가집니다.
- 공정성 보장: 거리 (r) 이내에 존재하는 모든 후보가 동일한 확률로 선택됨을 이론적으로 증명하고 실험적으로 검증했습니다.
- 효율성 유지: 쿼리 시간, 업데이트 시간, 메모리 사용량 모두 기존 비공정 알고리즘과 비슷한 수준을 유지했습니다.
- 범용성: 정확/근사 NN, 내적 기반 검색, 그리고 일반적인 집합 샘플링 문제까지 폭넓게 적용할 수 있습니다.
향후 연구 과제로는 (1) 동적 데이터(삽입·삭제가 빈번한 상황)에서의 공정성 유지, (2) 다른 거리 측정법(예: 맨해튼 거리, 코사인 유사도)에서의 공정 LSH 설계, (3) 공정성을 고려한 학습 기반 해시 함수 최적화 등이 있습니다. 이러한 방향을 통해, 머신러닝·추천시스템·검색 엔진 등 실제 서비스에 적용되는 유사도 검색 시스템이 공정하고 투명하게 동작하도록 하는 기반을 마련할 수 있을 것입니다.