Beyond Expertise and Roles: A Framework to Characterize the Stakeholders of Interpretable Machine Learning and their Needs
📝 Abstract
To ensure accountability and mitigate harm, it is critical that diverse stakeholders can interrogate black-box automated systems and find information that is understandable, relevant, and useful to them. In this paper, we eschew prior expertise- and role-based categorizations of interpretability stakeholders in favor of a more granular framework that decouples stakeholders’ knowledge from their interpretability needs. We characterize stakeholders by their formal, instrumental, and personal knowledge and how it manifests in the contexts of machine learning, the data domain, and the general milieu. We additionally distill a hierarchical typology of stakeholder needs that distinguishes higher-level domain goals from lower-level interpretability tasks. In assessing the descriptive, evaluative, and generative powers of our framework, we find our more nuanced treatment of stakeholders reveals gaps and opportunities in the interpretability literature, adds precision to the design and comparison of user studies, and facilitates a more reflexive approach to conducting this research.
💡 Analysis
To ensure accountability and mitigate harm, it is critical that diverse stakeholders can interrogate black-box automated systems and find information that is understandable, relevant, and useful to them. In this paper, we eschew prior expertise- and role-based categorizations of interpretability stakeholders in favor of a more granular framework that decouples stakeholders’ knowledge from their interpretability needs. We characterize stakeholders by their formal, instrumental, and personal knowledge and how it manifests in the contexts of machine learning, the data domain, and the general milieu. We additionally distill a hierarchical typology of stakeholder needs that distinguishes higher-level domain goals from lower-level interpretability tasks. In assessing the descriptive, evaluative, and generative powers of our framework, we find our more nuanced treatment of stakeholders reveals gaps and opportunities in the interpretability literature, adds precision to the design and comparison of user studies, and facilitates a more reflexive approach to conducting this research.
📄 Content
책임성을 확보하고 해를 최소화하기 위해서는 다양한 이해관계자들이 블랙‑박스 형태의 자동화 시스템을 조사하고, 그 시스템이 제공하는 정보를 자신들이 이해할 수 있는 형태로, 또한 자신들의 목적과 상황에 적합하고 실질적으로 활용 가능한 형태로 찾을 수 있어야 합니다. 이러한 요구는 단순히 기술적인 투명성을 넘어, 사회적·법적·윤리적 차원에서 시스템이 어떻게 작동하는지에 대한 명확한 설명을 요구하며, 이해관계자 각각이 가지고 있는 배경지식과 기대에 따라 그 설명의 깊이와 방식이 달라져야 함을 의미합니다.
본 논문에서는 기존에 흔히 사용되어 온 “전문성 기반” 혹은 “역할 기반”의 해석 가능성(stakeholder interpretability) 이해관계자 분류 방식을 포기하고, 이해관계자의 지식을 그들의 해석 가능성 요구와 명확히 분리하는 보다 세분화된 프레임워크를 제시합니다. 여기서 말하는 지식은 크게 세 가지 차원으로 구분됩니다.
형식적 지식(formal knowledge) – 수학, 통계, 컴퓨터 과학 등과 같이 공식적인 교육이나 훈련을 통해 습득한 이론적·기술적 배경을 말합니다. 예를 들어, 데이터 과학자나 머신러닝 엔지니어는 모델의 구조, 학습 알고리즘, 손실 함수 등에 대한 형식적 지식을 가지고 있기 때문에, 모델 내부의 파라미터 변화가 결과에 미치는 영향을 정량적으로 분석하고자 할 때 보다 깊이 있는 질문을 할 수 있습니다.
도구적 지식(instrumental knowledge) – 특정 도구, 플랫폼, 라이브러리, 혹은 업무 흐름에 대한 실무적인 사용 경험을 의미합니다. 비즈니스 분석가, 제품 매니저, 혹은 운영 담당자는 자신이 일상적으로 사용하는 대시보드나 보고서, 자동화 파이프라인에 대한 도구적 지식을 바탕으로 “왜 이 예측값이 이렇게 나왔는가?”라는 질문을 제기하고, 그 답변이 실제 의사결정에 바로 연결될 수 있기를 기대합니다.
개인적 지식(personal knowledge) – 개인의 가치관, 윤리적 기준, 도메인에 대한 직관적 이해, 그리고 과거 경험에서 비롯된 주관적인 판단을 포함합니다. 예를 들어, 의료 현장의 의사는 환자의 삶에 직접적인 영향을 미치는 모델 결과를 해석할 때, 단순히 통계적 정확도보다 환자 안전, 신뢰성, 그리고 윤리적 타당성을 더 중시하는 개인적 지식을 활용합니다.
우리는 이러한 세 가지 지식 유형이 머신러닝(Machine Learning) 자체, 데이터 도메인(예: 의료, 금융, 제조 등), 그리고 **일반적인 사회·문화적 환경(일반적인 milieu)**이라는 세 가지 맥락(context)에서 어떻게 구체적으로 나타나는지를 상세히 기술합니다. 예를 들어, 형식적 지식은 머신러닝 알고리즘의 수학적 특성에 초점을 맞추는 반면, 도구적 지식은 데이터 파이프라인의 구축·운영 과정에, 개인적 지식은 해당 도메인에서의 윤리적·법적 규제와 사회적 기대에 연결됩니다.
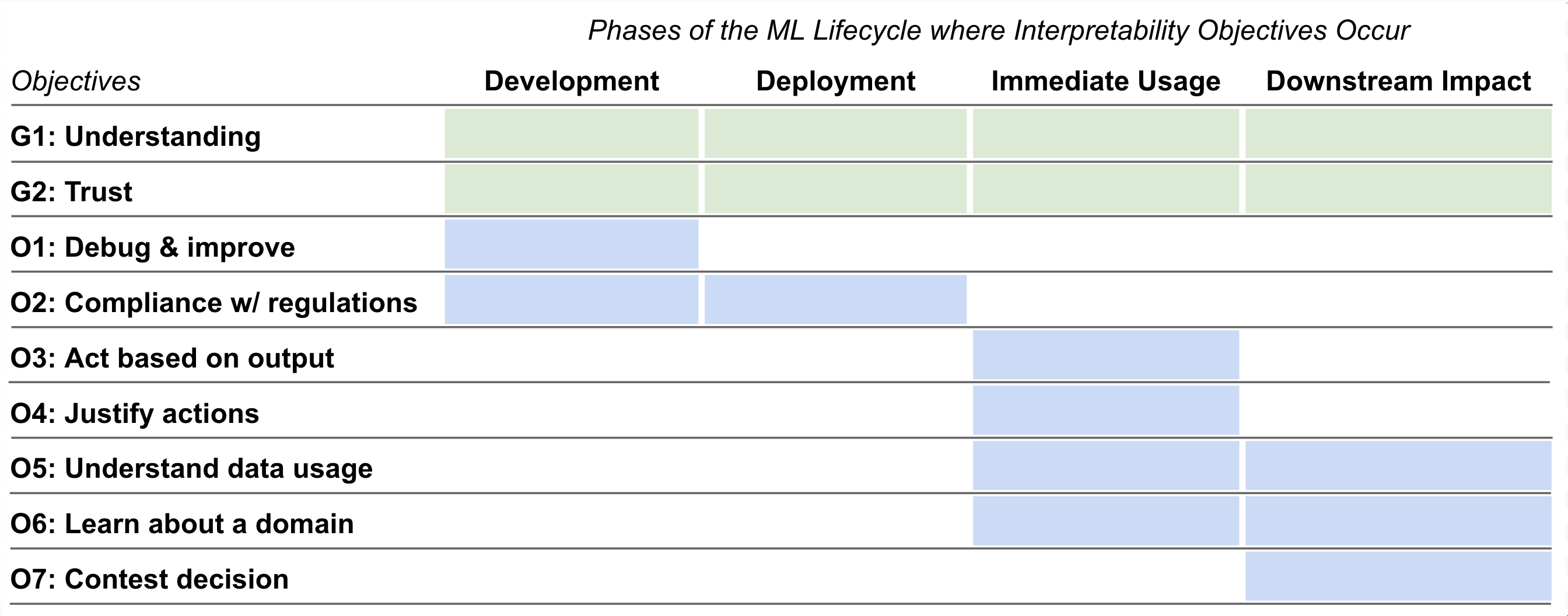
또한, 이해관계자의 요구를 계층적 유형학(hierarchical typology) 으로 정제하여, 상위 수준의 **도메인 목표(domain‑level goals)**와 하위 수준의 **해석 가능성 작업(interpretability tasks)**을 명확히 구분합니다. 도메인 목표는 “모델이 공정성을 보장해야 한다”, “예측 결과가 규제 기준에 부합해야 한다”와 같이 큰 그림의 목적을 의미하고, 해석 가능성 작업은 “특정 입력 특성이 예측에 미치는 영향을 시각화한다”, “모델의 결정 경로를 단계별로 설명한다”와 같이 구체적인 기술적 작업을 의미합니다. 이러한 구분을 통해 연구자는 이해관계자가 실제로 필요로 하는 것이 무엇인지, 그리고 그 필요를 충족시키기 위해 어떤 종류의 해석 도구나 방법론이 적합한지를 보다 체계적으로 파악할 수 있습니다.
우리 프레임워크의 서술적(descriptive), 평가적(evaluative), 그리고 생성적(generative) 힘을 검증하기 위해 여러 사례 연구와 문헌 조사를 수행한 결과, 이해관계자를 보다 미세하고 다차원적으로 다루는 접근이 기존 해석 가능성 문헌에서 간과되거나 충분히 탐구되지 않았던 **공백(gaps)**과 **기회(opportunities)**를 명확히 드러냄을 확인했습니다. 구체적으로, 기존 연구가 주로 “전문가 vs. 비전문가” 혹은 “데이터 과학자 vs. 정책 입안자”와 같은 이분법적 구분에 머물렀던 반면, 우리의 프레임워크는 같은 역할 내에서도 형식적·도구적·개인적 지식 수준에 따라 서로 다른 해석 요구가 존재한다는 점을 강조합니다.
이러한 세밀한 구분은 사용자 연구(user studies) 를 설계하고 결과를 비교할 때 정밀성(precision) 을 크게 향상시킵니다. 예를 들어, 동일한 인터페이스를 평가하더라도 형식적 지식이 높은 참가자와 도구적 지식이 높은 참가자는 서로 다른 평가 기준을 적용하므로, 이를 사전에 파악하고 실험 설계에 반영함으로써 보다 의미 있는 결과를 도출할 수 있습니다.
마지막으로, 우리의 접근은 반성적(reflexive) 연구 태도를 촉진합니다. 연구자는 자신이 어떤 지식 배경을 가지고 어떤 해석 가능성 요구를 전제로 연구를 진행하고 있는지를 명시적으로 인식하게 되며, 이는 연구 과정에서 발생할 수 있는 편향(bias)을 최소화하고, 결과 해석 시 보다 투명하고 책임감 있는 논의를 가능하게 합니다.
요약하면, 이해관계자의 지식을 해석 가능성 요구와 분리하여 보다 granular하고 다차원적인 프레임워크를 제시함으로써, 기존 해석 가능성 연구의 한계를 보완하고, 사용자 중심 설계와 평가를 위한 새로운 기준을 제공하며, 궁극적으로 자동화된 블랙‑박스 시스템에 대한 책임성 확보와 해악 최소화에 기여하고자 합니다.