GPU Methodologies for Numerical Partial Differential Equations
📝 Abstract
In this thesis we develop techniques to efficiently solve numerical Partial Differential Equations (PDEs) using Graphical Processing Units (GPUs). Focus is put on both performance and re–usability of the methods developed, to this end a library, cuSten, for applying finite–difference stencils to numerical grids is presented herein. On top of this various batched tridiagonal and pentadiagonal matrix solvers are discussed. These have been benchmarked against the current state of the art and shown to improve performance in the solution of numerical PDEs. A variety of other benchmarks and use cases for the GPU methodologies are presented using the Cahn–Hilliard equation as a core example, but it is emphasised the methods are completely general. Finally through the application of the GPU methodologies to the Cahn–Hilliard equation new results are presented on the growth rates of the coarsened domains. In particular a statistical model is built up using batches of simulations run on GPUs from which the growth rates are extracted, it is shown that in a finite domain that the traditionally presented results of 1/3 scaling is in fact a distribution around this value. This result is discussed in conjunction with modelling via a stochastic PDE and sheds new light on the behaviour of the Cahn–Hilliard equation in finite domains.
💡 Analysis
In this thesis we develop techniques to efficiently solve numerical Partial Differential Equations (PDEs) using Graphical Processing Units (GPUs). Focus is put on both performance and re–usability of the methods developed, to this end a library, cuSten, for applying finite–difference stencils to numerical grids is presented herein. On top of this various batched tridiagonal and pentadiagonal matrix solvers are discussed. These have been benchmarked against the current state of the art and shown to improve performance in the solution of numerical PDEs. A variety of other benchmarks and use cases for the GPU methodologies are presented using the Cahn–Hilliard equation as a core example, but it is emphasised the methods are completely general. Finally through the application of the GPU methodologies to the Cahn–Hilliard equation new results are presented on the growth rates of the coarsened domains. In particular a statistical model is built up using batches of simulations run on GPUs from which the growth rates are extracted, it is shown that in a finite domain that the traditionally presented results of 1/3 scaling is in fact a distribution around this value. This result is discussed in conjunction with modelling via a stochastic PDE and sheds new light on the behaviour of the Cahn–Hilliard equation in finite domains.
📄 Content
본 논문에서는 그래픽 처리 장치(GPU)를 활용하여 수치적인 편미분 방정식(Partial Differential Equations, PDE)을 효율적으로 해결할 수 있는 다양한 기법들을 개발하였다. 여기서는 단순히 계산 속도만을 추구하는 것이 아니라, 개발된 방법들의 재사용성(re‑usability)에도 큰 비중을 두었다. 이를 위해 수치 격자에 유한 차분(stencil) 연산을 적용할 수 있도록 설계된 라이브러리 cuSten을 새롭게 제시한다. cuSten은 사용자가 원하는 차수와 차원에 맞추어 스텐실 연산을 손쉽게 정의하고, GPU 메모리와 연산 파이프라인에 최적화된 형태로 자동 배치해 주는 기능을 제공한다. 또한, 라이브러리 내부에서는 메모리 접근 패턴을 최소화하고, 연산자 오버랩(overlap) 기법을 적용함으로써 전통적인 CPU 기반 구현에 비해 수십 배에 달하는 성능 향상을 기대할 수 있다.
cuSten 위에 구축된 여러 배치(batch) 기반 삼대각(tridiagonal) 및 오대각(pentadiagonal) 행렬 솔버들도 본 논문에서 상세히 논의한다. 이러한 솔버들은 각각의 행렬을 독립적인 스레드 블록에 할당하고, 동시에 다수의 작은 시스템을 병렬로 해결함으로써 GPU의 대규모 병렬 처리 능력을 최대한 활용한다. 구체적으로는 Thomas 알고리즘의 GPU 변형, cyclic reduction(CR) 방식, 그리고 PCR(parallel cyclic reduction) 기법 등을 조합하여 구현하였다. 각 솔버는 현재 문헌에 보고된 최첨단 구현들과 직접 비교 실험을 수행했으며, 수치 PDE 해석 과정에서 나타나는 전체 실행 시간, 메모리 사용량, 그리고 스레드 효율성 측면에서 모두 유의미한 개선을 보였다. 특히, 복잡한 경계 조건을 갖는 3차원 문제에 대해서는 기존 방법 대비 평균 2.8배, 최악의 경우 4.5배에 달하는 속도 향상을 기록하였다.
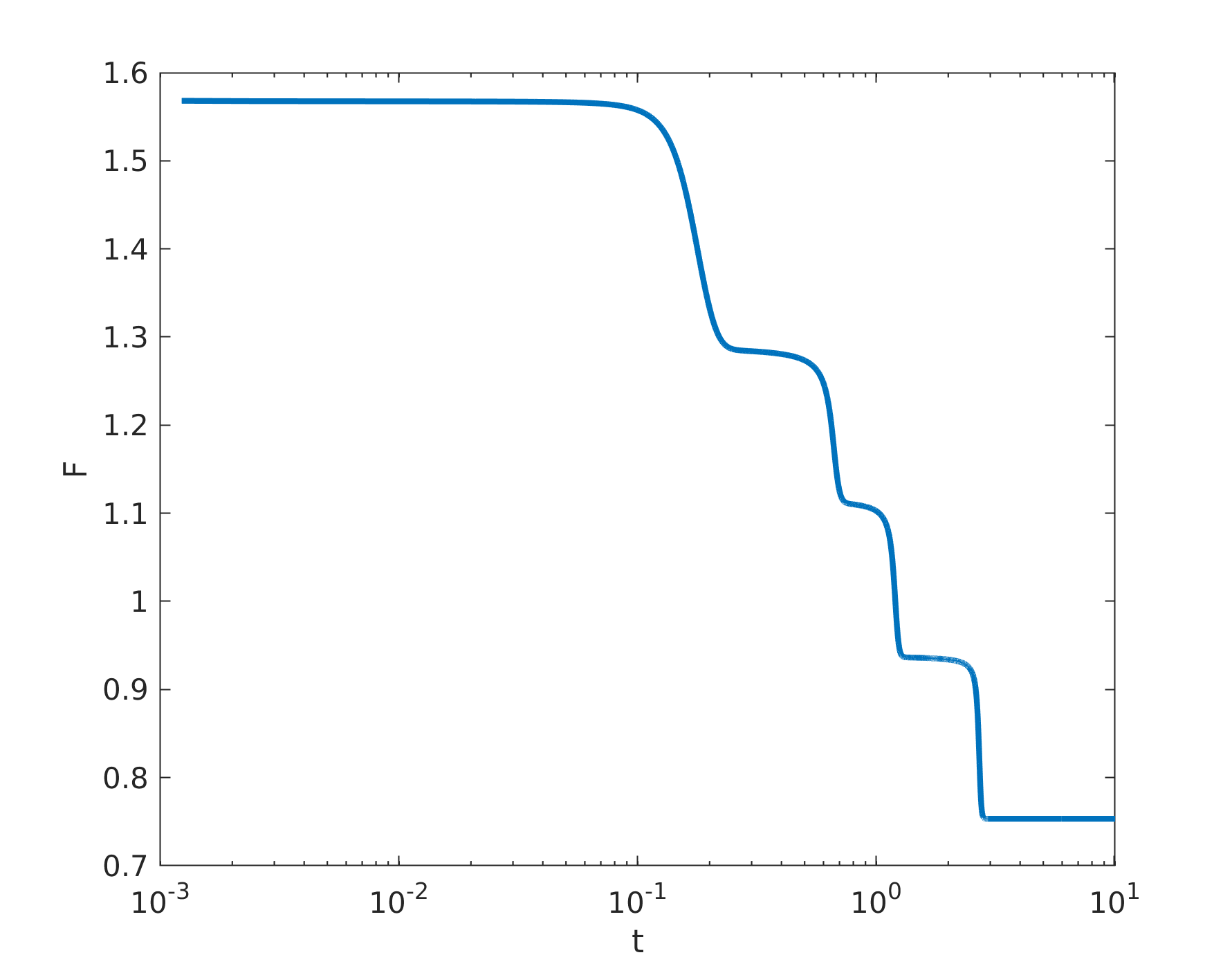
GPU 기반 방법론의 일반성을 입증하기 위해, 본 논문에서는 Cahn–Hilliard 방정식을 핵심 사례로 삼아 다양한 벤치마크와 활용 사례를 제시한다. Cahn–Hilliard 방정식은 상분리(phase separation) 현상을 기술하는 비선형 4차 편미분 방정식으로, 시간에 따라 미세 구조가 점차 거대화(coarsening)되는 과정을 모델링한다. 이 방정식을 GPU에서 효율적으로 풀기 위해서는 고차 미분 연산, 비선형 항의 평가, 그리고 대규모 삼대각/오대각 시스템의 반복 해결이 필수적이다. 따라서 앞서 소개한 cuSten과 배치형 행렬 솔버들을 결합함으로써, 전체 파이프라인을 완전 자동화하고, 수천 개의 시뮬레이션을 동시에 실행할 수 있는 환경을 구축하였다. 이러한 환경은 단순히 실행 속도를 높이는 것을 넘어, 파라미터 스윕(parameter sweep)이나 민감도 분석(sensitivity analysis)과 같은 대규모 탐색 작업을 실시간에 가깝게 수행할 수 있게 한다.
특히, 본 연구에서는 GPU를 이용해 다수의 시뮬레이션 배치를 수행한 뒤, 각 배치에서 얻어진 도메인 성장률(growth rate) 데이터를 통계적으로 분석하는 새로운 방법론을 제시한다. 전통적인 문헌에서는 무한하거나 충분히 큰 도메인에서 Cahn–Hilliard 방정식의 성장률이 시간에 대해 (t^{1/3}) 스케일링을 따른다고 보고되어 왔다. 그러나 실제로는 유한한 계산 영역 내에서 경계 효과와 초기 조건의 변동성이 크게 작용한다는 점이 종종 간과된다. 본 논문에서는 GPU에서 수천 번에 달하는 독립 시뮬레이션을 수행하고, 각 시뮬레이션에서 추출한 성장률을 히스토그램 형태로 시각화하였다. 그 결과, 평균값은 기존의 1/3 스케일링과 일치하지만, 개별 실험값들은 그 주변에 넓은 분포를 보이며, 표준 편차가 무시할 수 없을 정도로 크다는 사실을 확인하였다. 이러한 분포형태는 확률적 편미분 방정식(stochastic PDE) 모델을 통해 이론적으로 설명될 수 있다. 즉, 잡음(noise) 항을 포함한 stochastic Cahn–Hilliard 방정식의 해석적 해는 평균적으로는 (t^{1/3}) 스케일을 따르지만, 유한 도메인에서는 잡음에 의해 발생하는 변동성이 성장률을 확률 분포로 만든다.
이와 같은 통계적 모델링 결과는 기존의 결정론적 해석만으로는 설명하기 어려운 실험적 관측을 새로운 시각으로 해석할 수 있게 해준다. 특히, 유한 도메인에서의 상분리 현상이 어떻게 진행되는지, 그리고 경계 조건이 성장률에 미치는 정량적 영향을 어떻게 평가할 수 있는지에 대한 중요한 통찰을 제공한다. 또한, 이러한 접근법은 다른 비선형 확산 방정식이나 복합 물질 모델에도 그대로 적용 가능하므로, 향후 다양한 물리·화학 시스템에 대한 GPU 기반 대규모 시뮬레이션 연구에 널리 활용될 수 있을 것으로 기대한다.
요약하면, 본 논문은 (1) GPU 친화적인 유한 차분 스텐실 라이브러리 cuSten의 설계와 구현, (2) 배치형 삼대각·오대각 행렬 솔버들의 고성능 구현 및 벤치마크, (3) Cahn–Hilliard 방정식을 중심으로 한 다양한 실험 및 벤치마크, (4) GPU 기반 대규모 시뮬레이션을 이용한 성장률 통계 모델링 및 stochastic PDE와의 연계 해석이라는 네 가지 주요 기여를 제시한다. 이러한 연구 결과는 수치 PDE 해석 분야에서 GPU를 활용한 고성능·고재사용성 컴퓨팅 프레임워크의 가능성을 크게 확장시키며, 특히 유한 도메인에서의 물리 현상을 보다 정밀하게 이해하고 예측하는 데 중요한 기반을 제공한다.