GloBug: Using Global Data in Fault Localization
Fault Localization (FL) is an important first step in software debugging and is mostly manual in the current practice. Many methods have been proposed over years to automate the FL process, including information retrieval (IR)-based techniques. These methods localize the fault based on the similarity of the reported bug report and the source code. Newer variations of IR-based FL (IRFL) techniques also look into the history of bug reports and leverage them during the localization. However, all existing IRFL techniques limit themselves to the current project’s data (local data). In this study, we introduce Globug, which is an IRFL framework consisting of methods that use models pre-trained on the global data (extracted from open-source benchmark projects). In Globug, we investigate two heuristics: a) the effect of global data on a state-of-the-art IR-FL technique, namely BugLocator, and b) the application of a Word Embedding technique (Doc2Vec) together with global data. Our large scale experiment on 51 software projects shows that using global data improves BugLocator on average 6.6% and 4.8% in terms of MRR (Mean Reciprocal Rank) and MAP (Mean Average Precision), with over 14% in a majority (64% and 54% in terms of MRR and MAP, respectively) of the cases. This amount of improvement is significant compared to the improvement rates that five other state-of-the-art IRFL tools provide over BugLocator. In addition, training the models globally is a one-time offline task with no overhead on BugLocator’s run-time fault localization. Our study, however, shows that a Word Embedding-based global solution did not further improve the results.
💡 Research Summary
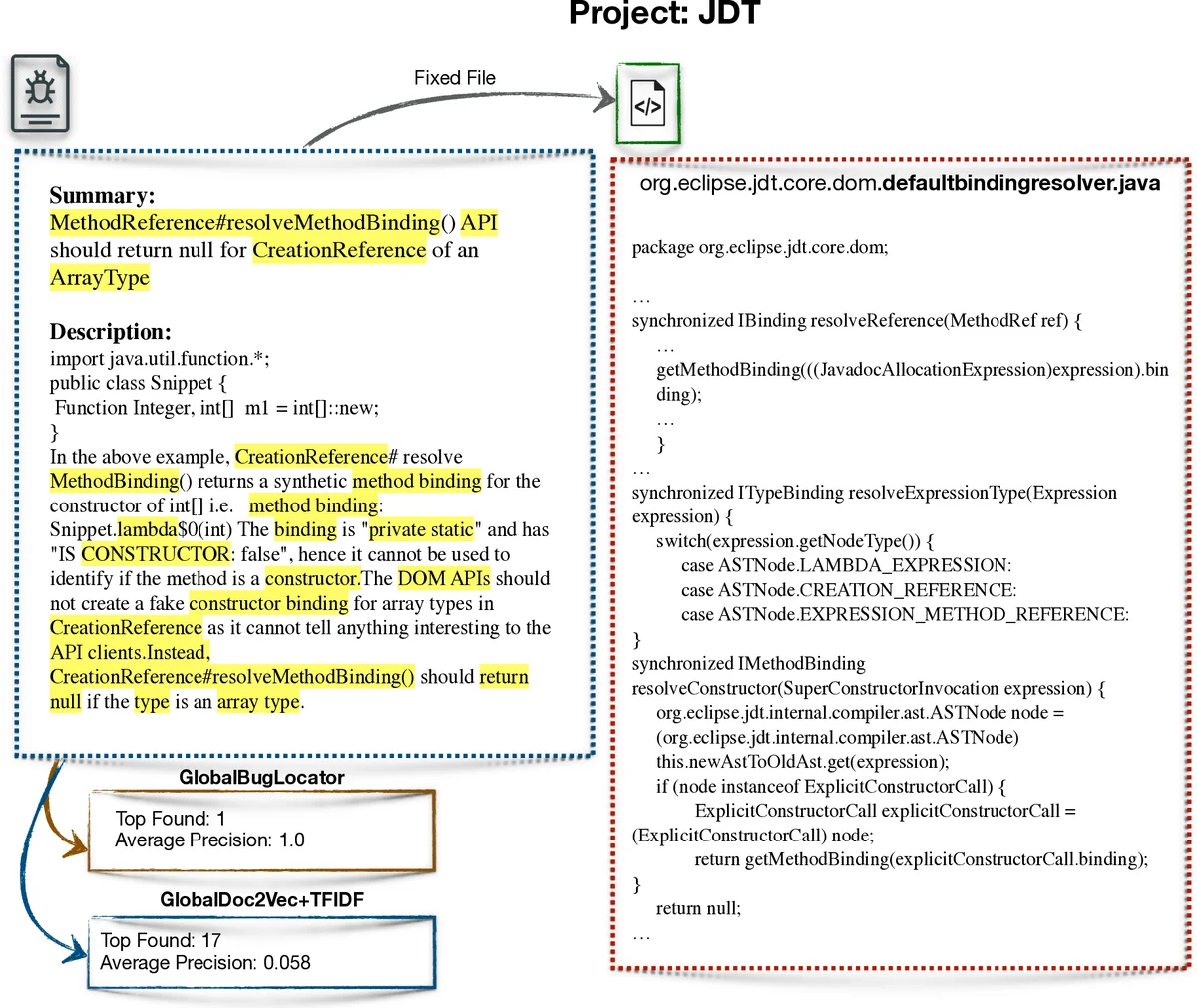
The paper introduces GloBug, an information‑retrieval‑based fault localization (IRFL) framework that leverages a large, publicly available corpus of bug reports and source code from many open‑source projects (the “global data”) to improve the accuracy of the state‑of‑the‑art technique BugLocator. Two heuristics are explored. The first replaces BugLocator’s locally‑computed TF‑IDF model with a TF‑IDF model trained on the global corpus. By constructing a vocabulary and inverse‑document‑frequency (IDF) weights from thousands of source files and bug reports across 50 benchmark projects, the authors obtain more reliable term importance values, especially for projects with sparse historical data. The global TF‑IDF is used for both the direct relevance (cosine similarity between the bug report and source file vectors) and the indirect relevance (similarity between the new bug report and historical reports, then propagated to source files). The two relevance scores are linearly combined exactly as in BugLocator, but the underlying term weights are now globally derived.
The second heuristic substitutes TF‑IDF with a Doc2Vec embedding trained on the same global corpus. Doc2Vec produces a fixed‑size vector for each document (bug report or source file), allowing similarity to be measured via cosine distance. The authors hypothesized that semantic embeddings would capture relationships missed by term‑frequency statistics.
Experiments were conducted on 51 software projects taken from the Bench4BL benchmark. For each run, one project served as the test target while the remaining 50 formed the global training set; this “leave‑one‑out” scheme was repeated for all projects. Evaluation used Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP). Results show that the global TF‑IDF variant improves BugLocator by an average of 6.6 % in MRR and 4.8 % in MAP. Moreover, in 64 % of the projects the MRR gain exceeds 14 %, and in 54 % the MAP gain exceeds 14 %. Compared with five recent IRFL tools that also improve upon BugLocator, GloBug’s gains are substantially larger.
In contrast, the Doc2Vec‑based variant did not outperform the TF‑IDF baseline; its MAP and MRR were comparable or slightly lower. The authors attribute this to the fact that fault localization relies heavily on precise term weighting (IDF) rather than broader semantic similarity, and that the lexical gap between bug reports and source code may not be effectively bridged by generic embeddings trained on heterogeneous data.
A key practical advantage of GloBug is that the global model is trained offline once. After the global TF‑IDF (or Doc2Vec) vectors are built, they can be reused for any number of new bugs in any project without additional runtime cost. This makes the approach lightweight and easily adoptable in industrial settings. The paper also discusses threats to validity, such as domain mismatch between the benchmark projects and a target project, and mitigates them by using a diverse set of projects spanning multiple languages and sizes.
In summary, GloBug demonstrates that incorporating freely available, large‑scale global data into the TF‑IDF component of IR‑based fault localization yields statistically significant improvements over the current best practice, while a straightforward global embedding does not yet provide added value. The work opens a research direction toward more sophisticated global models (e.g., Transformer‑based embeddings) and hybrid schemes that combine global and project‑specific information for even higher fault localization accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment