Optimal Energy Shaping via Neural Approximators
We introduce optimal energy shaping as an enhancement of classical passivity-based control methods. A promising feature of passivity theory, alongside stability, has traditionally been claimed to be intuitive performance tuning along the execution of a given task. However, a systematic approach to adjust performance within a passive control framework has yet to be developed, as each method relies on few and problem-specific practical insights. Here, we cast the classic energy-shaping control design process in an optimal control framework; once a task-dependent performance metric is defined, an optimal solution is systematically obtained through an iterative procedure relying on neural networks and gradient-based optimization. The proposed method is validated on state-regulation tasks.
💡 Research Summary
The paper tackles a long‑standing limitation of passivity‑based control (PBC): while PBC guarantees stability through energy‑based modeling, it offers little systematic guidance for performance tuning. Traditional energy‑shaping methods (especially energy‑balancing PBC, EB‑PBC) rely on ad‑hoc choices of a desired energy function (H^*) (often a simple quadratic) and a constant damping matrix (K). These choices are rarely optimal for a given task, leading to the perception that passivity incurs a performance penalty.
To overcome this, the authors recast the energy‑shaping design as an optimal control problem. They define a task‑specific scalar cost (\ell(t,u,x)) together with a terminal cost (L), and consider the expectation of the total cost over a distribution of initial states. The resulting nonlinear program (equation 6) seeks the optimal desired energy (H^) and state‑time‑dependent damping gain (K^(t,x)) that minimize the expected cost while preserving passivity.
Two major technical obstacles arise: (1) the matching condition for energy shaping appears as a PDE constraint; (2) the decision variables live in infinite‑dimensional function spaces. The paper resolves the first by introducing Proposition 2, which shows that if a low‑rank map (\Lambda(x)) exists such that the image of the annihilator of the input matrix spans the same subspace as (\Lambda(x)), then any desired energy can be expressed as the original Hamiltonian plus a scalar function (\phi(x_a)) defined on a reduced‑dimensional submanifold (X_a). This automatically satisfies the matching equations, eliminating the PDE constraint.
For the second obstacle, the authors approximate (\phi) and (K) with neural networks, (\phi_{\theta_\phi}) and (K_{\theta_K}), respectively. By embedding these networks into the closed‑loop dynamics, the control input becomes a differentiable function of the network parameters. The optimization problem (equation 10) is then tackled with stochastic gradient descent (SGD): a batch of initial states is sampled, the system is simulated forward using the current networks, the task cost is evaluated, and gradients with respect to (\theta = (\theta_\phi,\theta_K)) are obtained via automatic differentiation. A positivity projection ensures (K_{\theta_K}(t,x)) remains positive semidefinite, preserving the energy‑dissipation property.
Stability is guaranteed by construction: if (\phi_{\theta_\phi}) remains bounded, the modified Hamiltonian (H^* = H + \phi_{\theta_\phi}) serves as a Lyapunov function; the non‑negative damping matrix guarantees that (\dot H^* \le 0) along trajectories. Thus the learning process cannot violate the fundamental passivity of the closed loop.
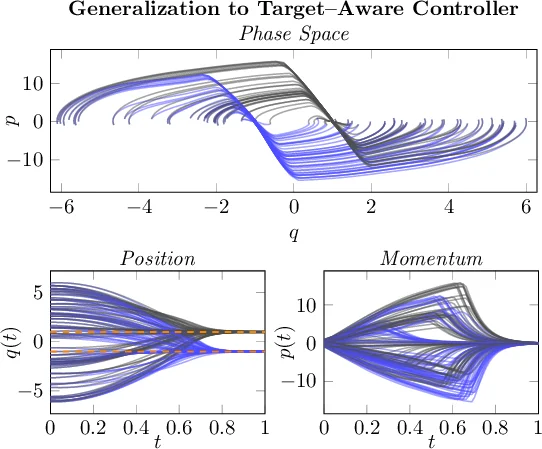
Experimental validation is performed on two benchmark mechanical systems—a 2‑DOF planar manipulator and a 3‑DOF robot arm—tasked with state regulation. The cost combines final‑state error and control‑effort energy. Compared against a conventional quadratic‑potential EB‑PBC, the neural‑approximated optimal energy shaping achieves faster convergence, lower steady‑state error, and reduced control energy, even when the initial states are drawn from a broad distribution.
The paper acknowledges several limitations. Identifying a suitable (\Lambda(x)) may be non‑trivial for high‑dimensional or highly under‑actuated systems. The neural‑network optimization inherits the usual challenges of non‑convex loss landscapes, requiring careful initialization and learning‑rate schedules. Moreover, the presented experiments are limited to relatively low‑dimensional systems; scalability to large‑scale robots or real‑time online adaptation remains to be demonstrated.
In summary, the work presents a novel synthesis of passivity‑based control theory and modern deep learning (Neural ODEs), delivering a systematic, task‑driven method to shape system energy optimally while retaining the intrinsic stability guarantees of PBC. Future directions include automated discovery of the reduction map (\Lambda), richer task‑specific cost formulations, and extensions to online adaptive control in more complex robotic platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment