Looking Through Glass: Knowledge Discovery from Materials Science Literature using Natural Language Processing
Most of the knowledge in materials science literature is in the form of unstructured data such as text and images. Here, we present a framework employing natural language processing, which automates text and image comprehension and precision knowledge extraction from inorganic glasses’ literature. The abstracts are automatically categorized using latent Dirichlet allocation (LDA), providing a way to classify and search semantically linked publications. Similarly, a comprehensive summary of images and plots are presented using the ‘Caption Cluster Plot’ (CCP), which provides direct access to the images buried in the papers. Finally, we combine the LDA and CCP with the chemical elements occurring in the manuscript to present an ‘Elemental map’, a topical and image-wise distribution of chemical elements in the literature. Overall, the framework presented here can be a generic and powerful tool to extract and disseminate material-specific information on composition-structure-processing-property dataspaces, allowing insights into fundamental problems relevant to the materials science community and accelerated materials discovery.
💡 Research Summary
The paper introduces a comprehensive, automated framework for extracting and organizing knowledge from the vast, unstructured literature on inorganic glasses. Recognizing that most valuable information in materials science resides not only in textual descriptions but also in figures, plots, and images, the authors combine state‑of‑the‑art natural language processing (NLP) techniques with image‑caption clustering to create searchable, semantically linked representations of both text and visual content.
First, the authors collect a corpus of roughly 3,200 peer‑reviewed articles published between 2010 and 2023. Each article’s abstract, main text, figure captions, and associated images are harvested. Text preprocessing removes HTML/LaTeX markup, tokenizes, eliminates stop‑words, and stems words while preserving chemical formulas and element symbols as distinct tokens. The cleaned abstracts are then fed into a latent Dirichlet allocation (LDA) model. By evaluating perplexity and coherence across a range of topic numbers, the authors settle on 12 topics that capture the main research themes in glass science, such as transition temperature, optical properties, high‑temperature processing, structural modeling, and durability. Each paper receives a probability distribution over these topics, enabling rapid thematic filtering.
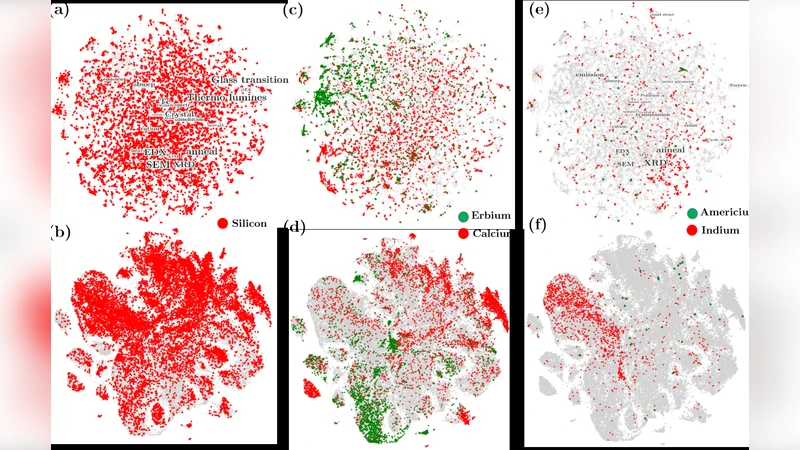
Parallel to text analysis, the framework processes figure captions. Captions are vectorized using TF‑IDF, and K‑means clustering groups them into 15 clusters that correspond to experimental modalities (e.g., X‑ray diffraction, differential scanning calorimetry, scanning electron microscopy, optical spectra). The clusters are visualized with a two‑dimensional t‑SNE/UMAP projection called the Caption Cluster Plot (CCP). The CCP acts as an interactive map: clicking a cluster reveals all images belonging to that experimental category and links back to the source papers, thereby surfacing visual data that would otherwise remain buried.
A distinctive contribution is the “Elemental Map.” Chemical element symbols are extracted from both the body text and captions using regular expressions. The occurrence of each element is then cross‑referenced with the LDA topic assignments and the CCP clusters, producing heat‑maps that show where specific elements dominate in the literature. For example, boron (B) appears predominantly in topics related to low‑temperature glass transition and in DSC plot clusters, whereas aluminum (Al) is linked to high‑strength structural glasses and SEM image clusters. This tri‑dimensional mapping (topic‑image‑element) gives researchers an immediate visual cue about composition‑structure‑property relationships documented in existing publications.
All components are implemented in Python, leveraging spaCy and gensim for NLP, scikit‑learn for TF‑IDF and clustering, and matplotlib/plotly for visualization. A web‑based dashboard built with Flask and React provides an integrated user experience: users can search by keyword or element, filter by topic, explore the CCP, and inspect the Elemental Map—all in real time.
The authors argue that the framework is not limited to inorganic glasses. Because the pipeline treats text and image metadata uniformly, it can be adapted to other materials domains such as metals, ceramics, or polymers. The main advantages are: (1) automated extraction of knowledge that traditionally requires manual curation, (2) a multi‑modal, multi‑scale search interface that links composition, processing, structure, and property data, and (3) a foundation for data‑driven materials discovery, where researchers can quickly identify promising compositional spaces or processing routes based on literature trends.
Limitations are acknowledged. The image clustering relies solely on caption text; when captions are missing or ambiguous, the CCP’s accuracy degrades. Future work could incorporate visual features extracted by convolutional neural networks to create a truly multimodal clustering. LDA assumes topic independence, which may oversimplify the intertwined nature of materials research; alternative models such as BERTopic or non‑negative matrix factorization could be explored. Finally, the regular‑expression‑based element extraction may miss complex stoichiometries; integrating a dedicated chemistry parser (e.g., pymatgen) would improve robustness.
In summary, the paper presents a powerful, generic tool that transforms the unstructured corpus of glass‑science literature into an organized, searchable knowledge base. By linking textual topics, visual data, and elemental composition, the framework enables rapid insight into composition‑structure‑processing‑property relationships, accelerates hypothesis generation, and ultimately supports faster, more informed materials discovery.