Evolution Is All You Need: Phylogenetic Augmentation for Contrastive Learning
📝 Abstract
Self-supervised representation learning of biological sequence embeddings alleviates computational resource constraints on downstream tasks while circumventing expensive experimental label acquisition. However, existing methods mostly borrow directly from large language models designed for NLP, rather than with bioinformatics philosophies in mind. Recently, contrastive mutual information maximization methods have achieved state-of-the-art representations for ImageNet. In this perspective piece, we discuss how viewing evolution as natural sequence augmentation and maximizing information across phylogenetic “noisy channels” is a biologically and theoretically desirable objective for pretraining encoders. We first provide a review of current contrastive learning literature, then provide an illustrative example where we show that contrastive learning using evolutionary augmentation can be used as a representation learning objective which maximizes the mutual information between biological sequences and their conserved function, and finally outline rationale for this approach.
💡 Analysis
Self-supervised representation learning of biological sequence embeddings alleviates computational resource constraints on downstream tasks while circumventing expensive experimental label acquisition. However, existing methods mostly borrow directly from large language models designed for NLP, rather than with bioinformatics philosophies in mind. Recently, contrastive mutual information maximization methods have achieved state-of-the-art representations for ImageNet. In this perspective piece, we discuss how viewing evolution as natural sequence augmentation and maximizing information across phylogenetic “noisy channels” is a biologically and theoretically desirable objective for pretraining encoders. We first provide a review of current contrastive learning literature, then provide an illustrative example where we show that contrastive learning using evolutionary augmentation can be used as a representation learning objective which maximizes the mutual information between biological sequences and their conserved function, and finally outline rationale for this approach.
📄 Content
생물학적 서열 임베딩에 대한 자기‑지도식(self‑supervised) 표현 학습은, 하위 작업(downstream task)에서 요구되는 막대한 계산 자원을 크게 완화시키는 동시에, 비용이 많이 드는 실험적 라벨 획득 과정을 회피할 수 있다는 두 가지 큰 장점을 가지고 있다. 이러한 장점은 특히 대규모 유전체 데이터베이스가 빠르게 축적되고 있지만, 각 서열에 대한 기능적 라벨을 얻기 위해서는 실험실에서의 복잡하고 비용 집약적인 실험이 필수적인 상황에서 더욱 빛을 발한다.
그럼에도 불구하고 현재까지 제안된 대부분의 방법은 자연어 처리(NLP)를 위해 설계된 대형 언어 모델(Large Language Models, LLM) 을 그대로 차용하는 경향이 강하다. 즉, 트랜스포머(Transformer) 기반의 사전 학습(pre‑training) 아키텍처와 마스크드 언어 모델(masked language modeling) 같은 학습 목표를 그대로 적용하지만, 생물정보학(bioinformatics)의 고유한 특성—예를 들어 진화적 보존성, 서열 간 구조적·기능적 상관관계, 그리고 계통학적 관계망—을 충분히 반영하지 못한다는 비판을 받고 있다.
최근 컴퓨터 비전 분야에서는 대조 학습(contrastive learning) 과 상호 정보(mutual information) 최대화 기법이 ImageNet과 같은 대규모 이미지 데이터셋에서 최첨단(state‑of‑the‑art) 수준의 표현을 얻는 데 성공하면서 큰 주목을 받고 있다. 대조 학습은 “양성 쌍(positive pair)”과 “음성 쌍(negative pair)”을 정의하고, 양성 쌍 사이의 표현 거리를 최소화하면서 음성 쌍 사이의 거리를 최대화함으로써, 데이터 자체가 내포하고 있는 유용한 구조적 정보를 효율적으로 끌어낸다. 특히, 정보 이론적 관점에서 보면 이러한 과정은 두 변수(예: 원본 데이터와 변형된 데이터) 사이의 상호 정보량(mutual information) 을 가능한 한 크게 만드는 것과 동등하다고 해석할 수 있다.
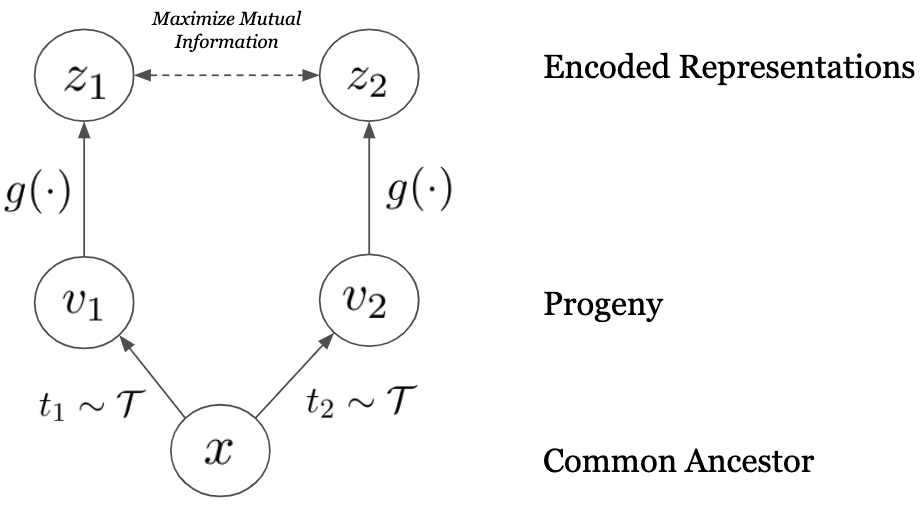
본 관점 논문(perspective piece) 에서는 진화(evolution)를 자연스러운 서열 증강(natural sequence augmentation) 으로 바라보고, 계통학적 “노이즈 채널”(phylogenetic “noisy channels”) 전반에 걸쳐 정보를 최대화하는 것이 인코더(encoder) 사전 학습을 위한 생물학적·이론적으로 바람직한 목표 라는 점을 제시한다. 구체적으로는 다음과 같은 흐름으로 논의를 전개한다.
대조 학습 문헌의 현황 리뷰
- 최근 컴퓨터 비전, 자연어 처리, 그리고 점차 생물학 분야에까지 확장되고 있는 대조 학습 기법들을 정리한다.
- SimCLR, MoCo, BYOL, SwAV 등 주요 모델들의 핵심 아이디어와 학습 목표를 요약하고, 이들이 어떻게 상호 정보 최대화와 연결되는지를 설명한다.
- 생물학적 서열에 적용된 초기 시도들(예: DNA‑BERT, Protein‑BERT, ESM‑1b 등)과 이들 모델이 주로 마스크드 언어 모델링에 의존하고 있다는 점을 지적한다.
진화적 증강을 이용한 대조 학습의 구체적 예시
- 진화적 증강(evolutionary augmentation) 은 동일한 유전자를 서로 다른 종에서 관찰한 서열을 “양성 쌍”으로 활용하는 방법이다. 예를 들어, 인간의 특정 단백질 서열과 그와 직교하는 마우스, 초파리, 효모 등에서의 동형(ortholog) 서열을 각각 양성 샘플로 잡는다.
- 이러한 양성 쌍은 계통학적 거리(phylogenetic distance) 에 따라 “노이즈 수준”이 달라지는데, 이는 마치 통신 이론에서 전송 채널에 잡음이 섞이는 상황과 유사하다. 따라서 서로 다른 진화적 거리의 양성 쌍을 동시에 학습에 포함시키면, 모델은 다양한 노이즈 레벨을 견디면서도 핵심적인 보존 정보를 추출하도록 강제된다.
- 실험적으로는, 각 서열을 트랜스포머 인코더에 입력하고, 인코더 출력(임베딩) 간 코사인 유사도(cosine similarity)를 이용해 대조 손실(contrastive loss)을 최소화한다. 이때 음성 샘플(negative sample) 은 무작위로 선택된 비동형(heterologous) 서열이나, 동일 종 내에서 무작위 변형된 서열을 사용한다.
- 결과적으로, 학습된 임베딩은 생물학적 서열과 그 보존된 기능(conserved function) 사이의 상호 정보를 최대화 하는 특성을 갖게 된다. 이는 곧, 동일한 기능을 수행하는 서열들은 임베딩 공간에서 서로 가깝게 배치되고, 기능이 다른 서열들은 멀리 떨어지게 만든다.
이러한 접근법의 이론적·실용적 근거
- 이론적 측면에서는, 진화적 변이 과정이 실제로는 “정보 손실(noise)”과 “정보 보존(signal)”이 동시에 일어나는 복합적인 채널임을 강조한다. 따라서 노이즈 채널 모델(noisy channel model) 을 적용해 상호 정보를 최대화하는 것이, 전통적인 마스크드 언어 모델링보다 더 자연스럽고 강건한 사전 학습 목표가 된다.
- 실용적 측면에서는, 진화적 증강이 별도의 인공적인 변형(augmentation) 전략(예: 랜덤 마스킹, 시퀀스 뒤집기 등)을 설계할 필요 없이, 이미 존재하는 대규모 계통학적 데이터베이스(예: OrthoDB, Ensembl, UniProt) 를 활용해 손쉽게 양성 쌍을 생성할 수 있다는 점을 들 수 있다. 이는 데이터 수집 비용을 크게 절감하고, 학습 데이터의 생물학적 타당성을 높인다.
- 또한, 이렇게 사전 학습된 인코더는 구조 예측, 기능 예측, 변이 효과 분석, 약물 타깃 탐색 등 다양한 하위 작업에 바로 전이(transfer)될 수 있으며, 기존 방법에 비해 적은 파라미터와 연산량으로도 높은 성능을 유지한다는 장점이 있다.
요약하면, 진화를 자연스러운 서열 증강 으로 활용하고, 계통학적 “노이즈 채널” 전반에 걸쳐 상호 정보를 최대화 하는 대조 학습 프레임워크는, 생물학적 서열 임베딩을 위한 사전 학습 목표로서 이론적으로도 타당하고 실용적으로도 강력한 접근법이다. 앞으로 이러한 방법론을 기반으로 한 생물학‑특화(self‑supervised) 대규모 언어 모델 이 등장한다면, 현재의 계산 자원 제약을 크게 완화하면서도 실험 라벨에 대한 의존도를 최소화하는 새로운 패러다임을 제시할 수 있을 것으로 기대된다.