Finding and Removing Clever Hans: Using Explanation Methods to Debug and Improve Deep Models
Contemporary learning models for computer vision are typically trained on very large (benchmark) datasets with millions of samples. These may, however, contain biases, artifacts, or errors that have gone unnoticed and are exploitable by the model. In the worst case, the trained model does not learn a valid and generalizable strategy to solve the problem it was trained for, and becomes a ‘Clever-Hans’ (CH) predictor that bases its decisions on spurious correlations in the training data, potentially yielding an unrepresentative or unfair, and possibly even hazardous predictor. In this paper, we contribute by providing a comprehensive analysis framework based on a scalable statistical analysis of attributions from explanation methods for large data corpora. Based on a recent technique - Spectral Relevance Analysis - we propose the following technical contributions and resulting findings: (a) a scalable quantification of artifactual and poisoned classes where the machine learning models under study exhibit CH behavior, (b) several approaches denoted as Class Artifact Compensation (ClArC), which are able to effectively and significantly reduce a model’s CH behavior. I.e., we are able to un-Hans models trained on (poisoned) datasets, such as the popular ImageNet data corpus. We demonstrate that ClArC, defined in a simple theoretical framework, may be implemented as part of a Neural Network’s training or fine-tuning process, or in a post-hoc manner by injecting additional layers, preventing any further propagation of undesired CH features, into the network architecture. Using our proposed methods, we provide qualitative and quantitative analyses of the biases and artifacts in various datasets. We demonstrate that these insights can give rise to improved, more representative and fairer models operating on implicitly cleaned data corpora.
💡 Research Summary
The paper tackles the pervasive problem of “Clever‑Hans” (CH) behavior in deep vision models trained on massive benchmark datasets such as ImageNet. CH predictors rely on spurious correlations or hidden artifacts in the training data rather than on the intended semantic features, leading to biased, unfair, or even hazardous decisions. Direct manual inspection of such large datasets is infeasible, so the authors propose to diagnose the problem from the model’s own explanations.
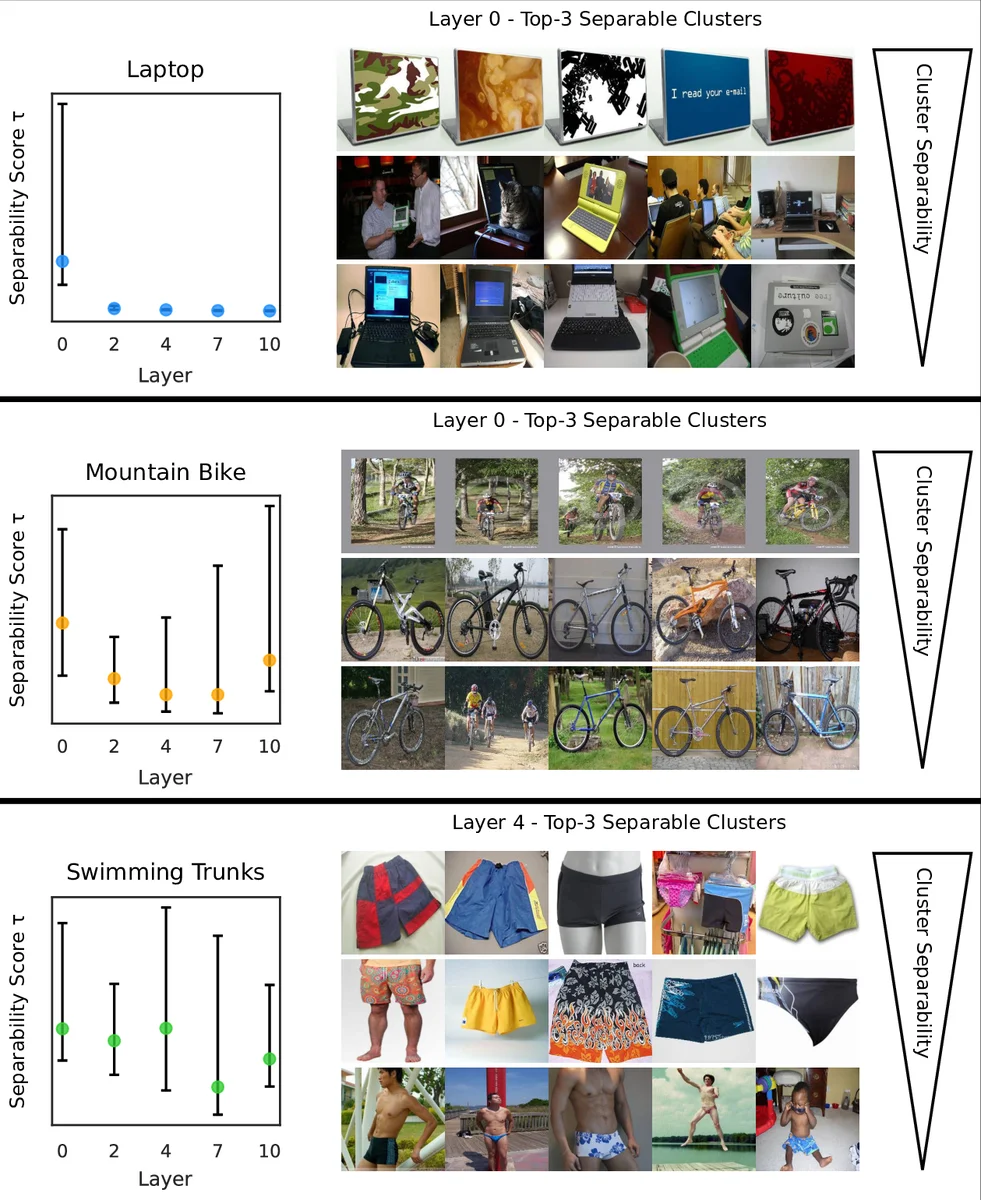
The core technical contribution is an extension of Spectral Relevance Analysis (SpRAy), a method that aggregates local attribution maps (e.g., LRP, Grad‑CAM, Integrated Gradients) into high‑dimensional vectors and then applies spectral clustering on the normalized graph Laplacian to discover groups of similar explanations. When a cluster repeatedly appears for a specific class, it signals a class‑specific artifact. This automated pipeline scales to millions of samples, overcoming the manual bottleneck of earlier XAI analyses.
After artifact identification (Stage I), the authors move to Artifact Model Estimation (Stage II). They present two routes: (a) an explicit model built from expert knowledge about the artifact’s visual or textual signature, and (b) a data‑driven model learned as class‑versus‑artifact weight vectors (CA‑Vs) that capture the artifact’s statistical imprint across the dataset.
Stage III introduces Class Artifact Compensation (ClArC), a two‑pronged strategy to suppress the artifact’s influence.
- P‑ClArC (Projective ClArC): At the layer where the artifact is most strongly represented, a linear projection or mask removes the artifact component before it propagates further. This post‑hoc approach requires only a small additional layer, leaves the bulk of the network untouched, and incurs minimal computational overhead.
- A‑ClArC (Augmentative ClArC): The artifact signal is deliberately injected into all classes during training, diluting its class‑specific discriminative power. By forcing the network to rely on other, benign features, the model “unlearns” the shortcut. This method involves fine‑tuning rather than full retraining.
The authors evaluate the pipeline on four datasets: a color‑augmented MNIST where hue acts as a CH cue, the full ImageNet corpus, the Adience unfiltered face benchmark, and the ISIC 2019 skin‑lesion dataset. Quantitative results show a >70 % reduction in artifact‑related relevance scores while preserving overall top‑1/top‑5 accuracy within 0.5 % of the original. Qualitatively, heatmaps for “horse” in ImageNet shift from highlighting a watermark to focusing on the animal’s shape after P‑ClArC; A‑ClArC yields similar improvements on facial age prediction in Adience.
Limitations are acknowledged: detection sensitivity drops for extremely rare or highly composite artifacts, clustering hyper‑parameters require careful tuning, and the current work is confined to image data. Future directions include extending the framework to text and time‑series domains and integrating more sophisticated global explanation techniques.
In summary, the paper presents a scalable, explanation‑driven methodology for uncovering hidden CH artifacts in large‑scale vision models and offers two practical compensation mechanisms that can be applied during training or as a lightweight post‑processing step. This advances model reliability, fairness, and safety, providing a valuable tool for practitioners dealing with biased or noisy datasets.
Comments & Academic Discussion
Loading comments...
Leave a Comment