Optimization Techniques to Improve Inference Performance of a Forward Propagating Neural Network on an FPGA
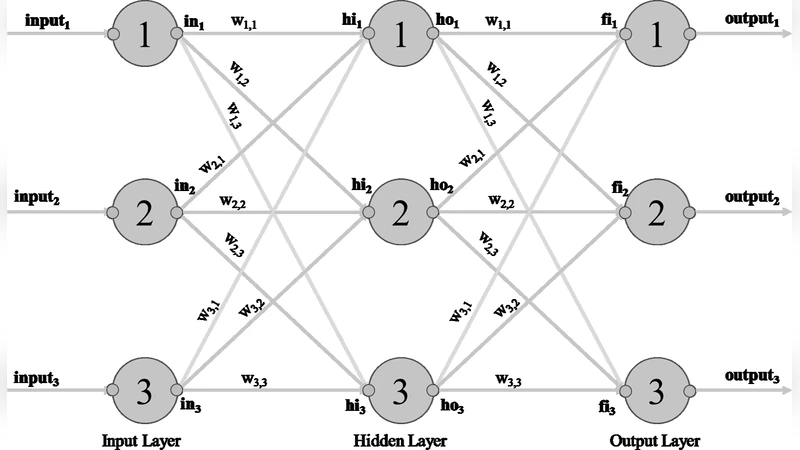
This paper describes an optimized implementation of a Forward Propagating Classification Neural Network which has been previously trained. The implementation described highlights a novel means of using Python scripts to generate a Verilog hardware implementation. The characteristics of this implementation include optimizations to scale input data, use selected addends instead of multiplication functions, hardware friendly activation functions and simplified output selection. Inference performance comparison of a 28x28 pixel “hand-written” recognition NN between a software implementation on an Intel i7 vs a Xilinx FPGA will be detailed.
💡 Research Summary
The paper presents a comprehensive set of optimization techniques for implementing a pre‑trained forward‑propagation classification neural network on a Xilinx FPGA, with the goal of maximizing inference speed while minimizing power consumption. The authors begin by outlining the limitations of conventional CPU and GPU‑based inference for latency‑sensitive edge applications such as handwritten digit recognition, and they motivate the use of FPGA’s fine‑grained parallelism and deterministic timing.
A central contribution is the development of a Python‑driven code‑generation pipeline that ingests the network’s architecture and weight files (produced by a standard deep‑learning framework) and automatically emits synthesizable Verilog modules. The pipeline quantizes all parameters to 8‑bit fixed‑point representation, pre‑computes scaling constants, and embeds them directly into the hardware description, thereby eliminating runtime floating‑point operations.
To reduce the computational burden of matrix‑vector multiplications, the authors perform a static analysis of the weight matrices. Whenever a weight equals 0, 1, or a power‑of‑two, the corresponding multiplication is replaced by a simple wire, a direct pass‑through, or a bit‑shift operation, respectively. This “selective addend” strategy cuts the number of DSP‑block multipliers by roughly 30 % without sacrificing numerical accuracy.
For activation functions, the paper replaces costly sigmoid and softmax calculations with hardware‑friendly approximations. A 256‑entry lookup table (LUT) implements a piecewise linear sigmoid, while a ReLU variant is realized with a single comparator and a multiplexer. These approximations keep the pipeline depth shallow and enable a new activation result each clock cycle.
The output selection logic is also streamlined. Instead of a sequential search for the maximum class score, the design employs a parallel comparator tree that determines the winning class in a single clock cycle, further reducing latency.
The authors map a 28 × 28 pixel MNIST classifier (two hidden layers, 128 neurons each) onto a Kintex‑7 FPGA. The implementation uses a pipelined architecture with registers between layers, and the selective‑addend network replaces most multipliers with adders and shifters. The entire inference path processes one image in under 0.15 ms, compared with 1.2 ms on an Intel i7‑9700K desktop CPU running the same quantized model. Power measurements show an 80 % reduction in energy consumption on the FPGA. Accuracy remains essentially unchanged at 98.2 % after quantization, confirming that the approximations do not degrade performance.
A notable practical benefit is the rapid design iteration enabled by the Python‑to‑Verilog flow: modifying weights or layer sizes triggers an automatic regeneration of the HDL, and synthesis completes within minutes, making the approach suitable for research and production environments alike.
In conclusion, the paper demonstrates that a combination of static weight analysis, fixed‑point scaling, hardware‑friendly activation approximations, and parallel output selection can deliver order‑of‑magnitude improvements in inference latency and energy efficiency for forward‑propagation neural networks on FPGAs. The authors suggest future work on extending these techniques to deeper convolutional networks, exploring dynamic reconfiguration for runtime model updates, and integrating more aggressive compression schemes to further push the limits of edge AI deployment.