Run-time reconfigurable multi-precision floating point multiplier design for high speed, low-power applications
Floating point multiplication is one of the crucial operations in many application domains such as image processing, signal processing etc. But every application requires different working features. Some need high precision, some need low power consumption, low latency etc. But IEEE-754 format is not really flexible for these specifications and also design is complex. Optimal run-time reconfigurable hardware implementations may need the use of custom floating-point formats that do not necessarily follow IEEE specified sizes. In this paper, we present a run-time-reconfigurable floating point multiplier implemented on FPGA with custom floating point format for different applications. This floating point multiplier can have 6 modes of operations depending on the accuracy or application requirement. With the use of optimal design with custom IPs (Intellectual Properties), a better implementation is done by truncating the inputs before multiplication. And a combination of Karatsuba algorithm and Urdhva-Tiryagbhyam algorithm (Vedic Mathematics) is used to implement unsigned binary multiplier. This further increases the efficiency of the multiplier.
💡 Research Summary
The paper presents a run‑time reconfigurable, multi‑precision floating‑point multiplier implemented on an FPGA, targeting high‑speed and low‑power applications. The authors argue that the IEEE‑754 standard, with its fixed exponent and mantissa widths, is too rigid for many domains where precision, power, and latency requirements vary widely. To address this, they propose a custom floating‑point format that can be dynamically reconfigured among six operating modes using three mode‑select bits embedded in the input word.
Architecture Overview
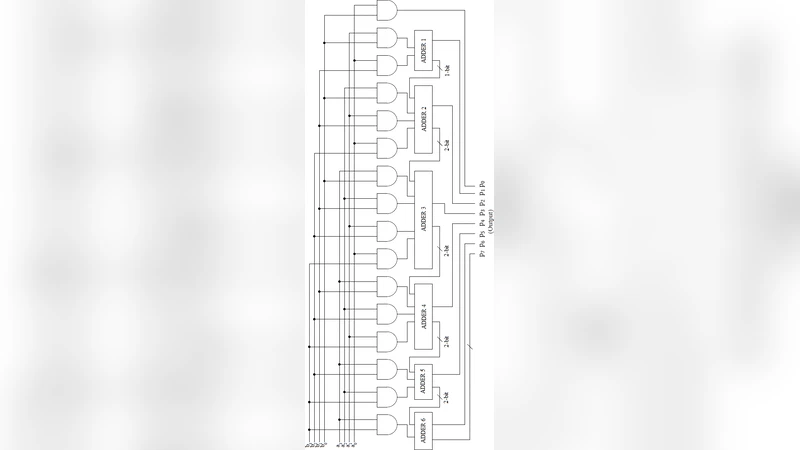
Each operand is 67 bits wide: the most‑significant three bits encode the mode (000‑101). Mode 0 is an “auto” mode that inspects the number of leading zeros in the mantissa and selects the smallest mantissa width that can represent the value without overflow. Modes 1‑4 correspond to custom mantissa widths of 8, 16, 23, and 36 bits respectively, while Mode 5 is a full double‑precision (53‑bit mantissa) implementation. By truncating the lower bits of the mantissa before multiplication, the design reduces the number of required partial products, thereby saving power and area.
Multiplication Core
The core of the design is an unsigned binary multiplier that combines two algorithms:
-
Urdhva‑Tiryagbhyam (Vedic) multiplication – used for small operand sizes (up to 8 bits). This algorithm generates partial products by a vertical‑and‑crosswise method, requiring only a few adders. The authors replace simple ripple‑carry adders with carry‑save adders (CSA) and carry‑select adders (CSLA) to minimise critical‑path delay.
-
Karatsuba divide‑and‑conquer multiplication – employed when the mantissa width exceeds the Vedic threshold. The operands are split into high and low halves, three sub‑multiplications are performed (high×high, low×low, and the cross term), and the result is recombined using the classic Karatsuba formula. This reduces the multiplication complexity from O(n²) to O(n^log₂3) and is especially beneficial for the 16‑, 23‑, 36‑, and 53‑bit cases.
A hardware selector monitors the current mode and automatically switches between the Vedic and Karatsuba datapaths, eliminating the need for separate multiplier instances.
Exponent and Sign Handling
The sign of the product is obtained by XOR‑ing the input sign bits. Exponents are added with the IEEE‑754 bias of 127 (or 1023 for double‑precision) and then corrected for overflow/underflow. After mantissa multiplication, a normalization step left‑shifts the result until the most‑significant ‘1’ occupies the hidden‑bit position; each shift increments the exponent accordingly.
Exception Management
Four special‑case output signals are generated: Zero, Infinity, NaN, and Denormal. The design follows the IEEE‑754 conventions for encoding these conditions, even though the internal mantissa width may differ from the standard.
Implementation and Results
The multiplier was described in Verilog and synthesized for a Xilinx Kintex‑7 device. Separate implementations were created for each precision mode, and the binary multiplier core (Karatsuba‑Vedic) was further optimised by substituting generic adders with CSAs and CSLAs. The authors claim reductions in LUT, register, and DSP utilization, as well as lower dynamic power consumption when operating in lower‑precision modes, while maintaining a comparable maximum clock frequency across modes. However, the paper does not provide concrete numerical data (e.g., resource counts, timing, power measurements) for each mode, making quantitative comparison with existing IEEE‑754‑based multipliers difficult.
Critical Assessment
The concept of run‑time reconfigurability via three mode‑select bits is elegant and offers a flexible trade‑off between precision and resource usage. The hybrid use of Vedic and Karatsuba algorithms is technically sound; each algorithm is applied where it is most efficient, and the automatic switching logic is a practical hardware solution. Nonetheless, several shortcomings limit the impact of the work:
- The “auto” mode’s leading‑zero count adds extra combinational logic that could increase latency, yet its impact is not measured.
- Truncating lower mantissa bits reduces hardware effort but introduces quantisation error; the paper lacks a discussion of error bounds or any compensation technique.
- Exception handling is described at a high level, but the interaction between custom formats and standard software libraries is not addressed, raising compatibility concerns.
- The experimental section omits detailed performance figures (e.g., throughput, latency, power per operation), preventing a clear assessment of the claimed speed‑power advantage.
- No comparison with state‑of‑the‑art IEEE‑754 multipliers (e.g., DSP48E1‑based designs) is presented.
Conclusion
The authors have introduced a promising architecture that can adapt its precision at run‑time, potentially saving power and area for applications that do not require full double‑precision accuracy. The hybrid Karatsuba‑Vedic multiplier core is a noteworthy contribution. Future work should provide rigorous quantitative evaluation, explore error‑analysis for truncated inputs, and demonstrate integration with standard floating‑point software stacks to validate the practicality of the proposed custom formats.
Comments & Academic Discussion
Loading comments...
Leave a Comment