Towards Robust Deep Neural Networks for Affect and Depression Recognition from Speech
Intelligent monitoring systems and affective computing applications have emerged in recent years to enhance healthcare. Examples of these applications include assessment of affective states such as Major Depressive Disorder (MDD). MDD describes the constant expression of certain emotions: negative emotions (low Valence) and lack of interest (low Arousal). High-performing intelligent systems would enhance MDD diagnosis in its early stages. In this paper, we present a new deep neural network architecture, called EmoAudioNet, for emotion and depression recognition from speech. Deep EmoAudioNet learns from the time-frequency representation of the audio signal and the visual representation of its spectrum of frequencies. Our model shows very promising results in predicting affect and depression. It works similarly or outperforms the state-of-the-art methods according to several evaluation metrics on RECOLA and on DAIC-WOZ datasets in predicting arousal, valence, and depression. Code of EmoAudioNet is publicly available on GitHub: https://github.com/AliceOTHMANI/EmoAudioNet
💡 Research Summary
The paper introduces EmoAudioNet, a novel two‑stream deep neural network designed for speech‑based emotion and depression recognition. The authors argue that existing approaches either rely on handcrafted acoustic descriptors (e.g., prosodic, spectral, glottal features) combined with conventional classifiers, or they employ deep models that ingest a single type of representation (raw waveform, MFCCs, or spectrograms). Such methods miss the complementary information present in both the time‑frequency texture of a spectrogram and the compact, perceptually motivated MFCC features.
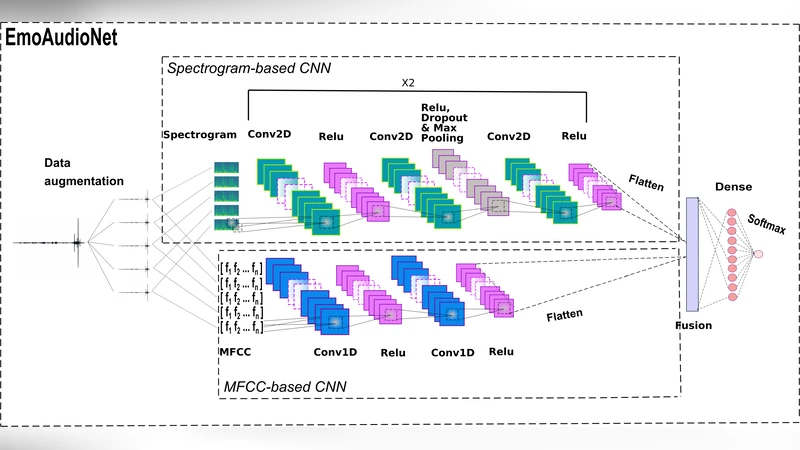
EmoAudioNet addresses this gap by simultaneously processing (1) a spectrogram‑based CNN and (2) an MFCC‑based CNN. For the spectrogram stream, the audio signal is segmented into 256 short frames, each transformed via a Fast Fourier Transform (FFT) with a Hamming window. The resulting magnitude spectra are assembled into a colour image (1900 × 1200 × 3) and resized to 224 × 224 × 3 before entering a shallow 2‑D CNN consisting of two identical blocks (Conv‑ReLU‑Conv‑ReLU‑Dropout‑MaxPool‑Conv‑ReLU). This branch outputs a 1152‑dimensional high‑level feature vector.
The MFCC stream first extracts 177‑dimensional cepstral coefficients from 2.5‑second frames (500 ms hop) using a Mel‑scale filterbank, DCT, and a Karhunen‑Loeve approximation. These coefficients are fed to a lightweight 1‑D CNN with two Conv‑ReLU layers, producing a 2816‑dimensional feature vector.
The two vectors are concatenated and passed through a fully‑connected layer with a softmax (or linear) output, depending on the task (binary depression classification, depression severity regression, or continuous arousal/valence prediction). Training is performed end‑to‑end with the Adam optimizer; cross‑entropy loss is used for classification, while a Concordance Correlation Coefficient (CCC) based loss is employed for continuous emotion regression.
To mitigate data scarcity and improve robustness, the authors apply two audio augmentation techniques: (i) additive noise (α = 0.01, 0.02, 0.03) and (ii) pitch shifting (−0.5, −2, −5 semitones). These augmentations increase the effective training set size and expose the model to varied acoustic conditions.
Experiments are conducted on two publicly available corpora. RECOLA (French, 23 speakers, 5‑minute recordings) provides continuous arousal and valence annotations; DAIC‑WOZ (English clinical interviews) supplies binary depression labels and PHQ‑9 severity scores. Evaluation metrics include Pearson’s Correlation Coefficient (PCC) for emotion, F1‑score for binary depression, and RMSE/MAE for severity regression.
Results show that EmoAudioNet outperforms or matches state‑of‑the‑art baselines. On RECOLA, the model achieves PCC ≈ 0.70 for arousal and ≈ 0.78 for valence, surpassing prior CNN‑LSTM and raw‑signal CNN approaches (which reported PCC around 0.44–0.69). On DAIC‑WOZ, EmoAudioNet reaches an F1‑score of ~0.86 for depression detection and reduces RMSE/MAE to 4.5/3.6 for PHQ‑9 regression, improving upon previous bests by roughly 10–20 %. Ablation studies confirm that the fusion of spectrogram and MFCC streams yields consistent gains over each stream alone, highlighting the complementary nature of visual texture and compact spectral descriptors.
The authors acknowledge limitations: spectrogram generation is memory‑intensive, hindering real‑time deployment; the datasets are limited to French and English, raising questions about cross‑lingual generalization; and the two‑stream architecture, while parameter‑efficient, still demands higher GPU memory due to parallel processing.
Future work is outlined as follows: (1) designing lightweight multimodal fusion modules to enable on‑device inference, (2) extending the framework to incorporate textual and visual cues for a truly multimodal affective system, (3) curating multilingual, culturally diverse speech corpora to test robustness, and (4) exploring streaming‑compatible architectures for continuous monitoring in clinical settings.
In summary, EmoAudioNet presents a compelling solution that jointly leverages time‑frequency visual patterns and MFCC‑based acoustic cues, delivering robust performance for both continuous emotion tracking and depression assessment from speech. Its open‑source implementation further encourages reproducibility and facilitates downstream research in affective computing and mental‑health technology.
Comments & Academic Discussion
Loading comments...
Leave a Comment