A review on Neural Turing Machine
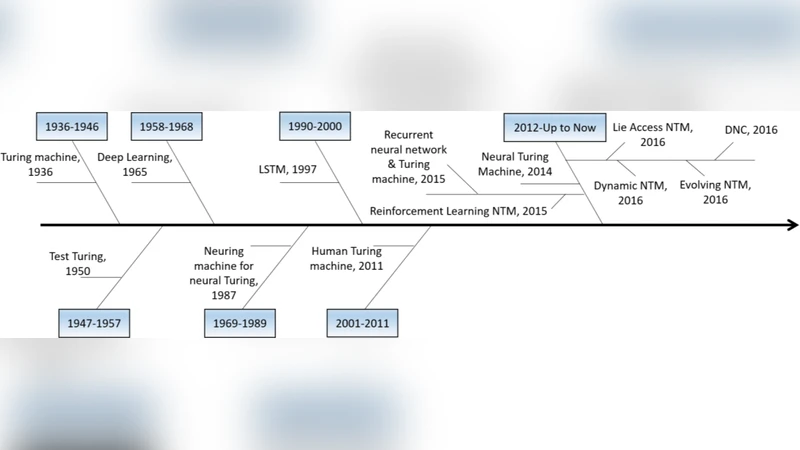
One of the major objectives of Artificial Intelligence is to design learning algorithms that are executed on a general purposes computational machines such as human brain. Neural Turing Machine (NTM) is a step towards realizing such a computational machine. The attempt is made here to run a systematic review on Neural Turing Machine. First, the mind-map and taxonomy of machine learning, neural networks, and Turing machine are introduced. Next, NTM is inspected in terms of concepts, structure, variety of versions, implemented tasks, comparisons, etc. Finally, the paper discusses on issues and ends up with several future works.
💡 Research Summary
This paper presents a systematic review of Neural Turing Machines (NTMs), positioning them as a pivotal step toward building general‑purpose computational agents that resemble the human brain. The authors begin by mapping the relationships among machine learning, neural networks, and the classical Turing machine, illustrating how NTMs integrate the differentiable learning capabilities of neural networks with the external, addressable memory of a Turing machine. The core architecture is dissected into four components: a controller (typically an LSTM or GRU), a memory matrix, read/write heads, and a differentiable addressing mechanism. Two addressing strategies are highlighted—content‑based addressing, which uses cosine similarity between the controller output and memory slots, and location‑based addressing, which shifts focus along the memory tape. By blending these strategies, NTMs can emulate data structures such as stacks, queues, and linked lists while remaining fully trainable via back‑propagation.
The review then surveys major NTM variants. The Differentiable Neural Computer (DNC) augments the original model with a memory allocation and usage graph, enabling more complex graph‑structured reasoning. Memory‑Augmented Neural Networks (MANNs) introduce meta‑controllers that regulate read/write frequency, improving training stability. Compressed‑Memory NTMs address the problem of limited memory capacity by learning to encode salient information into a smaller footprint. Each variant is evaluated against the shortcomings of the baseline NTM—namely, scalability of memory, instability during training, and difficulty handling long‑range dependencies.
Experimental tasks commonly used to benchmark NTMs are described in detail. In the copy task, NTMs learn to reproduce an input sequence after a delay, achieving high accuracy with fewer epochs than vanilla LSTMs. The associative recall task tests the ability to store key‑value pairs and retrieve the correct value given a key, showcasing the strength of content‑based addressing. Sorting tasks require the model to output a sorted version of a random numeric sequence, demonstrating that NTMs can implicitly learn algorithmic operations such as comparison and swapping. Graph traversal and navigation tasks further illustrate the capacity for algorithmic reasoning. Across these tasks, NTMs consistently outperform traditional recurrent models but suffer from increased computational cost and memory consumption as the memory matrix grows.
A comparative analysis with attention‑based Transformers is provided. While Transformers excel at parallel processing and global context via self‑attention, they lack an explicit external memory, making it difficult to model step‑by‑step algorithmic processes. NTMs, by contrast, maintain a persistent memory that can be read and written across time steps, offering a more natural substrate for procedural reasoning. However, the sequential nature of NTM operations hampers parallelism, and the differentiable addressing mechanism introduces optimization challenges not present in pure attention models.
The authors identify three primary challenges that currently limit NTM adoption: (1) memory scaling—addressing complexity grows quadratically with memory size; (2) addressing precision—soft attention can become overly diffuse, reducing effective read/write resolution; and (3) training stability—performance is highly sensitive to initialization, learning‑rate schedules, and gradient clipping. To address these issues, the paper proposes several future research directions: hierarchical memory architectures that partition memory into coarse‑grained and fine‑grained levels; integration of reinforcement learning to learn adaptive memory management policies; development of specialized hardware accelerators (e.g., ASICs or FPGA designs) that co‑locate memory and compute for low‑latency access; and hybrid discrete‑continuous addressing schemes that combine the robustness of hard selection with the differentiability of soft attention.
In conclusion, the review synthesizes the state‑of‑the‑art in NTM research, highlighting both the promise of external, differentiable memory for algorithmic reasoning and the practical hurdles that must be overcome. By outlining a clear set of technical challenges and prospective solutions, the paper provides a roadmap for researchers aiming to advance NTMs toward truly general‑purpose artificial intelligence systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment