Big Data Is not just a New Type, but a New Paradigm
This paper is a first draft of the introduction to the special issue on volunteered geographic information published in Computers, Environment and Urban Systems (2015, 53, 1-122). In this short paper, I put georeferenced big data (hereafter, big data) such as tweets locations in comparison with small data such as census data in terms of data characteristics, and further argued that big data differs fundamentally from small data in terms of data analytics, both geometrially and statistically. I would like to thank my colleague Dr. Jean-Claude Thill, who expanded the draft towards a broader scope.
💡 Research Summary
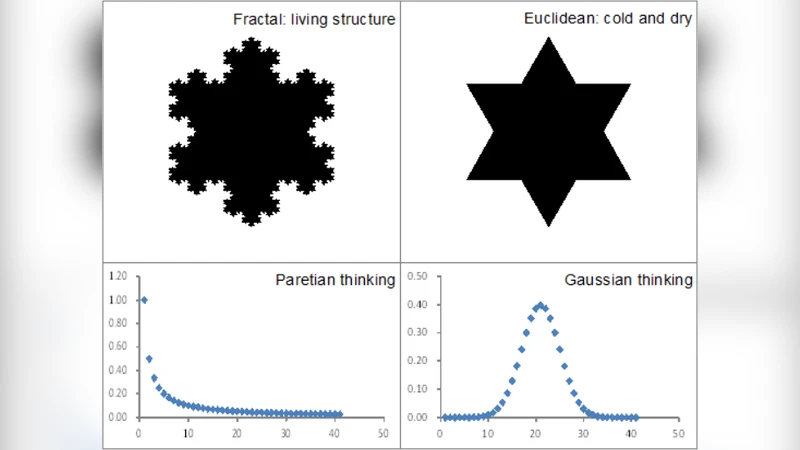
The paper, originally drafted as an introduction to a special issue on volunteered geographic information (VGI) in Computers, Environment and Urban Systems (2015), argues that georeferenced big data—exemplified by Twitter location streams—constitutes not merely a new data type but an entirely new analytical paradigm when compared with traditional “small” data such as census statistics. The author begins by outlining the five‑V framework (Volume, Velocity, Variety, Veracity, Granularity) that distinguishes big data from small data. While census data are aggregated at administrative units, updated on multi‑year cycles, and generally conform to Gaussian assumptions, Twitter data are generated in real time at the level of individual GPS points, exhibit heavy‑tailed, non‑Gaussian distributions, and are inherently noisy and non‑representative due to voluntary participation.
The core of the analysis focuses on two dimensions of methodological shift: geometric representation and statistical inference. Geometrically, small data are handled through polygon‑based aggregation, yielding average densities or growth rates for predefined zones. In contrast, big data form a dense point cloud that invites kernel density estimation, spatial clustering (e.g., DBSCAN), and flow‑based analyses that can capture fine‑grained, transient phenomena such as sudden crowd movements or emergent hotspots. This shift demands extensions to conventional GIS architectures, including streaming spatial databases, real‑time visualization pipelines, and hybrid raster‑vector models.
Statistically, the paper demonstrates that the central‑limit‑theorem‑driven inferential toolbox (means, standard deviations, t‑tests) is ill‑suited for big data. The prevalence of power‑law and other heavy‑tail distributions means that extreme values dominate system behavior, requiring alternative metrics such as scaling exponents, fractal dimensions, and tail‑risk measures. Consequently, the author advocates for Bayesian hierarchical models, spatial econometrics that accommodate heteroskedasticity, and machine‑learning approaches (deep neural networks, random forests) that can learn complex, non‑linear spatio‑temporal patterns without strict distributional assumptions.
A comparative case study of New York City and Seoul illustrates these points. When a large public protest occurs, Twitter‑derived point densities spike within minutes, revealing precise routes and congregation points. The same event is invisible in census‑derived density maps, which only reflect long‑term residential patterns. This example underscores the transition from explanatory, policy‑oriented analysis (typical of small data) to predictive, real‑time decision support (enabled by big data).
The paper also addresses practical challenges: privacy and ethical concerns surrounding location traces, the need for robust noise‑filtering and data‑quality assessment, and the computational demands of processing billions of records, which call for cloud‑based, distributed processing frameworks (e.g., Spark, Hadoop). It calls for a re‑education of GIS professionals to master these new tools and for interdisciplinary collaboration between computer scientists, urban planners, and social scientists.
In conclusion, the author posits that big data reshapes every stage of the geographic information workflow—from acquisition and storage to analysis and policy application—thereby establishing a new paradigm. Future research directions include hybrid models that fuse VGI with traditional datasets, multi‑scale analytical frameworks that reconcile point‑level dynamics with aggregated statistics, and the integration of big‑data‑driven decision models into urban governance. The acknowledgment credits Dr. Jean‑Claude Thill for expanding the draft’s scope.
Comments & Academic Discussion
Loading comments...
Leave a Comment