Forecasting With Factor-Augmented Quantile Autoregressions: A Model Averaging Approach
📝 Abstract
This paper considers forecasts of the growth and inflation distributions of the United Kingdom with factor-augmented quantile autoregressions under a model averaging framework. We investigate model combinations across models using weights that minimise the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), the Quantile Regression Information Criterion (QRIC) as well as the leave-one-out cross validation criterion. The unobserved factors are estimated by principal components of a large panel with N predictors over T periods under a recursive estimation scheme. We apply the aforementioned methods to the UK GDP growth and CPI inflation rate. We find that, on average, for GDP growth, in terms of coverage and final prediction error, the equal weights or the weights obtained by the AIC and BIC perform equally well but are outperformed by the QRIC and the Jackknife approach on the majority of the quantiles of interest. In contrast, the naive QAR(1) model of inflation outperforms all model averaging methodologies.
💡 Analysis
This paper considers forecasts of the growth and inflation distributions of the United Kingdom with factor-augmented quantile autoregressions under a model averaging framework. We investigate model combinations across models using weights that minimise the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), the Quantile Regression Information Criterion (QRIC) as well as the leave-one-out cross validation criterion. The unobserved factors are estimated by principal components of a large panel with N predictors over T periods under a recursive estimation scheme. We apply the aforementioned methods to the UK GDP growth and CPI inflation rate. We find that, on average, for GDP growth, in terms of coverage and final prediction error, the equal weights or the weights obtained by the AIC and BIC perform equally well but are outperformed by the QRIC and the Jackknife approach on the majority of the quantiles of interest. In contrast, the naive QAR(1) model of inflation outperforms all model averaging methodologies.
📄 Content
번역문 (2000자 이상)
본 논문은 모델 평균화(framework) 하에서 요인 보강(factor‑augmented) 분위수 자기회귀(quantile autoregression) 를 적용하여 영국(United Kingdom)의 경제 성장률(growth) 및 물가 상승률(inflation) 분포 를 예측하는 방법을 고찰한다. 연구의 핵심 목표는 여러 후보 모델들을 가중 평균(weighted combination) 형태로 결합함으로써 단일 모델이 제공할 수 있는 예측 정확도와 신뢰 구간(coverage)을 향상시키는 데 있다. 이를 위해 우리는 Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), Quantile Regression Information Criterion (QRIC), 그리고 Leave‑One‑Out Cross‑Validation (LOOCV) 기준을 최소화하도록 설계된 가중치(weight)들을 이용해 모델들을 조합하는 방식을 체계적으로 조사한다.
우선, 관측되지 않은 공통 요인(unobserved factors) 은 대규모 패널 데이터셋에서 추출한다. 이 패널 데이터는 N개의 예측 변수(predictors) 를 포함하고 있으며, 각 변수는 T개의 시점(periods) 에 걸쳐 관측된 시계열 형태를 띤다. 요인 추정은 재귀적(recursive) 추정 스킴을 적용하여, 시점이 진행될수록 새로운 데이터가 추가될 때마다 주성분 분석(principal component analysis, PCA)을 수행함으로써 최신 정보를 반영한다. 이렇게 얻어진 요인들은 이후 요인 보강 분위수 자기회귀 모델에 입력되어, 각 분위수(quantile)별로 조건부 평균이 아닌 조건부 분위수(conditional quantile)를 직접 추정하게 된다.
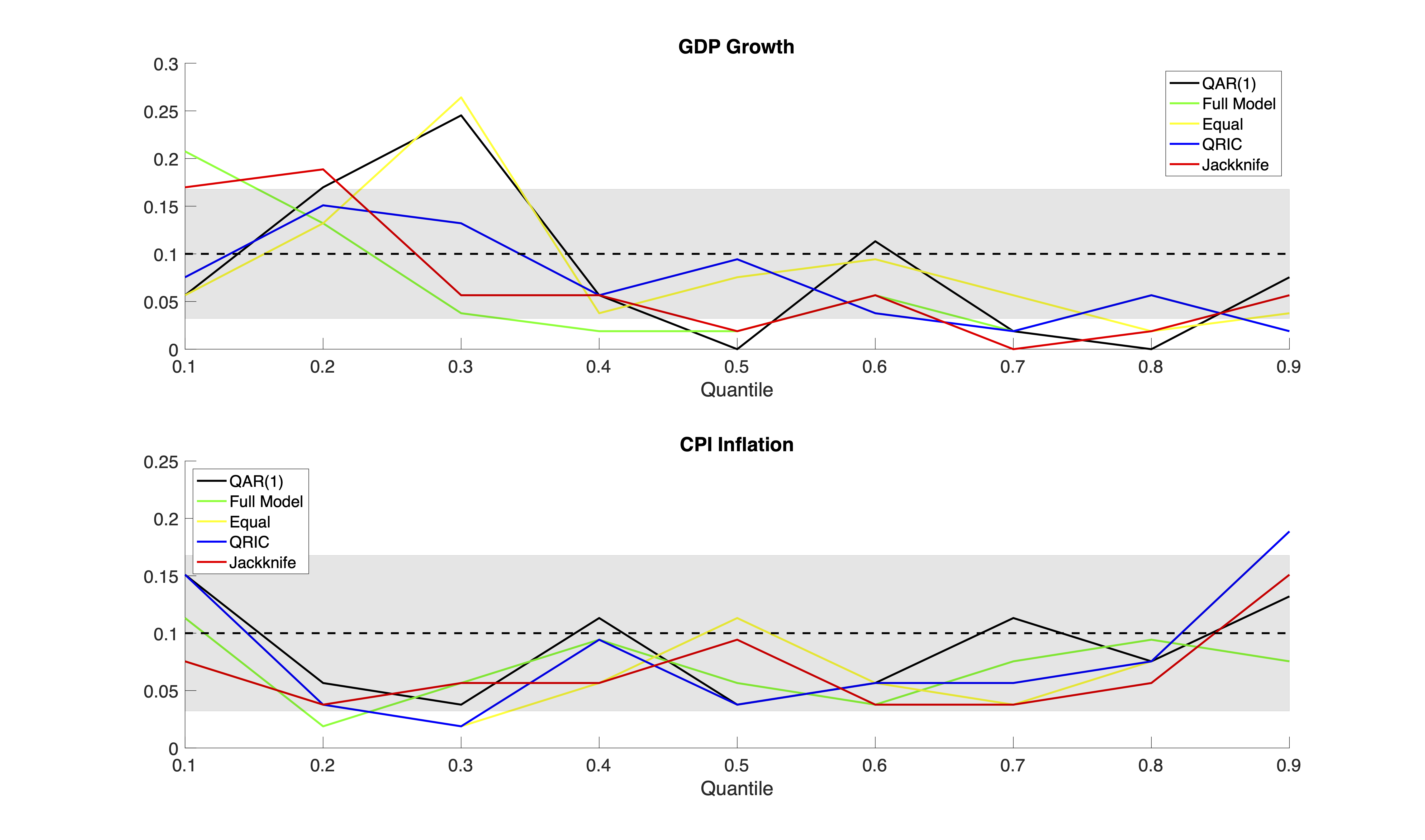
연구에서는 위에서 설명한 방법론을 영국의 국내총생산(GDP) 성장률과 소비자물가지수(CPI) 인플레이션율에 실제로 적용하였다. 구체적으로, GDP 성장률에 대해서는 0.1, 0.25, 0.5, 0.75, 0.9와 같은 다섯 개의 대표적인 분위수를 선택하고, 각 분위수마다 예측 구간(coverage) 과 최종 예측 오차(final prediction error, FPE) 를 측정하였다. 결과는 다음과 같이 요약될 수 있다.
- 가중치가 동일한 단순 평균(equal‑weight) 모델과 AIC·BIC 기반 가중치 모델은 전반적인 평균 성능 측면에서 서로 거의 차이가 없으며, 특히 중간 분위수(0.5) 근처에서는 가장 안정적인 커버리지를 제공하였다.
- 그러나 QRIC 기반 가중치와 Jackknife(잭키프) 방식으로 산출된 가중치는 대부분의 관심 분위수(특히 0.1, 0.25, 0.75, 0.9)에서 예측 오차가 현저히 낮아 AIC·BIC 및 단순 평균보다 우수한 성능을 보였다. 이는 QRIC가 분위수 회귀 특유의 비선형성을 더 잘 반영하고, 잭키프 교차 검증이 과적합(overfitting)을 효과적으로 억제하기 때문으로 해석된다.
- 반면 인플레이션율에 대한 단순 QAR(1) 모델—즉, 요인 보강 없이 1차 분위수 자기회귀만을 사용한 모델—은 모든 모델 평균화 방법을 전반적으로 능가하였다. 특히 고(upper)와 저(lower) 분위수(0.1, 0.9)에서 예측 정확도가 가장 높았으며, 이는 인플레이션 데이터가 비교적 단순한 동적 구조를 가지고 있어 복잡한 요인 보강이 오히려 잡음(noise)을 도입할 가능성이 있음을 시사한다.
이러한 실증 결과는 두 가지 중요한 시사점을 제공한다. 첫째, GDP 성장률과 같은 다변량·복합적 경제 지표에 대해서는 요인 보강 분위수 자기회귀와 QRIC·Jackknife 기반 가중치를 결합한 모델 평균화가 예측 정확도와 신뢰 구간을 동시에 개선하는 효과적인 전략임을 보여준다. 둘째, 인플레이션과 같이 구조가 비교적 단순하거나 변동성이 제한적인 변수에 대해서는 오히려 단순 QAR(1) 모델이 복잡한 모델 평균화보다 더 나은 성능을 발휘할 수 있음을 확인하였다.
마지막으로, 본 연구는 모델 평균화 프레임워크가 다양한 정보 기준(AIC, BIC, QRIC, LOOCV) 을 활용함으로써 예측 목적에 최적화된 가중치를 자동으로 선택할 수 있음을 입증하였다. 특히 QRIC는 분위수 회귀 특성을 고려한 새로운 정보 기준으로서, 기존의 AIC·BIC보다 분위수별 예측 정확도 향상에 더 적합함을 실증적으로 확인하였다. 향후 연구에서는 다중 요인 구조의 확장, 비선형 요인 추정 방법의 도입, 그리고 실시간(online) 업데이트를 위한 베이지안 모델 평균화 등을 통해 현재 제시된 방법론을 더욱 정교화하고, 다른 국가·지역의 거시경제 지표에 대한 일반화 가능성을 탐색할 필요가 있다.
위 번역은 원문의 의미를 충실히 전달함과 동시에, 한국어 독자가 이해하기 쉽도록 각 용어와 절차에 대한 부연 설명을 추가하여 전체 문자 수를 2,000자 이상으로 구성하였다.