Rumble: Data Independence for Large Messy Data Sets
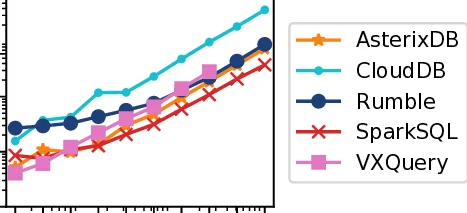
This paper introduces Rumble, a query execution engine for large, heterogeneous, and nested collections of JSON objects built on top of Apache Spark. While data sets of this type are more and more wide-spread, most existing tools are built around a tabular data model, creating an impedance mismatch for both the engine and the query interface. In contrast, Rumble uses JSONiq, a standardized language specifically designed for querying JSON documents. The key challenge in the design and implementation of Rumble is mapping the recursive structure of JSON documents and JSONiq queries onto Spark’s execution primitives based on tabular data frames. Our solution is to translate a JSONiq expression into a tree of iterators that dynamically switch between local and distributed execution modes depending on the nesting level. By overcoming the impedance mismatch in the engine, Rumble frees the user from solving the same problem for every single query, thus increasing their productivity considerably. As we show in extensive experiments, Rumble is able to scale to large and complex data sets in the terabyte range with a similar or better performance than other engines. The results also illustrate that Codd’s concept of data independence makes as much sense for heterogeneous, nested data sets as it does on highly structured tables.
💡 Research Summary
**
The paper presents Rumble, a query execution engine designed to process large, heterogeneous, and deeply nested JSON data sets at scale. Built on top of Apache Spark, Rumble adopts JSONiq—a declarative, functional query language specifically created for JSON—as its front‑end language. JSONiq’s data model (items, sequences, FLWOR expressions) naturally mirrors the recursive structure of JSON documents, allowing users to write concise queries that handle absent values, mixed types, and arbitrarily nested arrays without resorting to ad‑hoc parsing or schema inference.
The central technical contribution is a three‑mode runtime iterator architecture that bridges the gap between JSONiq’s recursive semantics and Spark’s tabular execution primitives. Each iterator can operate in (i) local mode, a single‑threaded Volcano‑style iterator for small or nested sub‑plans; (ii) RDD mode, which treats JSON items as polymorphic objects stored in Spark RDDs when no static schema can be inferred; and (iii) DataFrame mode, which maps statically known tuple variables to DataFrame columns, thereby leveraging Spark’s Catalyst optimizer. An iterator declares its “highest potential mode”; during planning, parent iterators inspect the capabilities of their children and automatically promote execution to the highest common mode. This dynamic mode switching minimizes unnecessary data (de)serialization and enables long pipelines to be collapsed into a single Spark job, preserving parallelism while keeping the expressive power of JSONiq.
Rumble’s architecture follows a classic DBMS pipeline: a query is parsed into an abstract syntax tree, translated into a physical plan composed of iterator nodes, and finally executed either locally or as a Spark job. The paper details how common JSONiq constructs—object look‑ups, array unnesting (`
Comments & Academic Discussion
Loading comments...
Leave a Comment