Incremental Transfer Learning in Two-pass Information Bottleneck based Speaker Diarization System for Meetings
The two-pass information bottleneck (TPIB) based speaker diarization system operates independently on different conversational recordings. TPIB system does not consider previously learned speaker discriminative information while diarizing new convers…
Authors: Nauman Dawalatabad, Srikanth Madikeri, C Ch
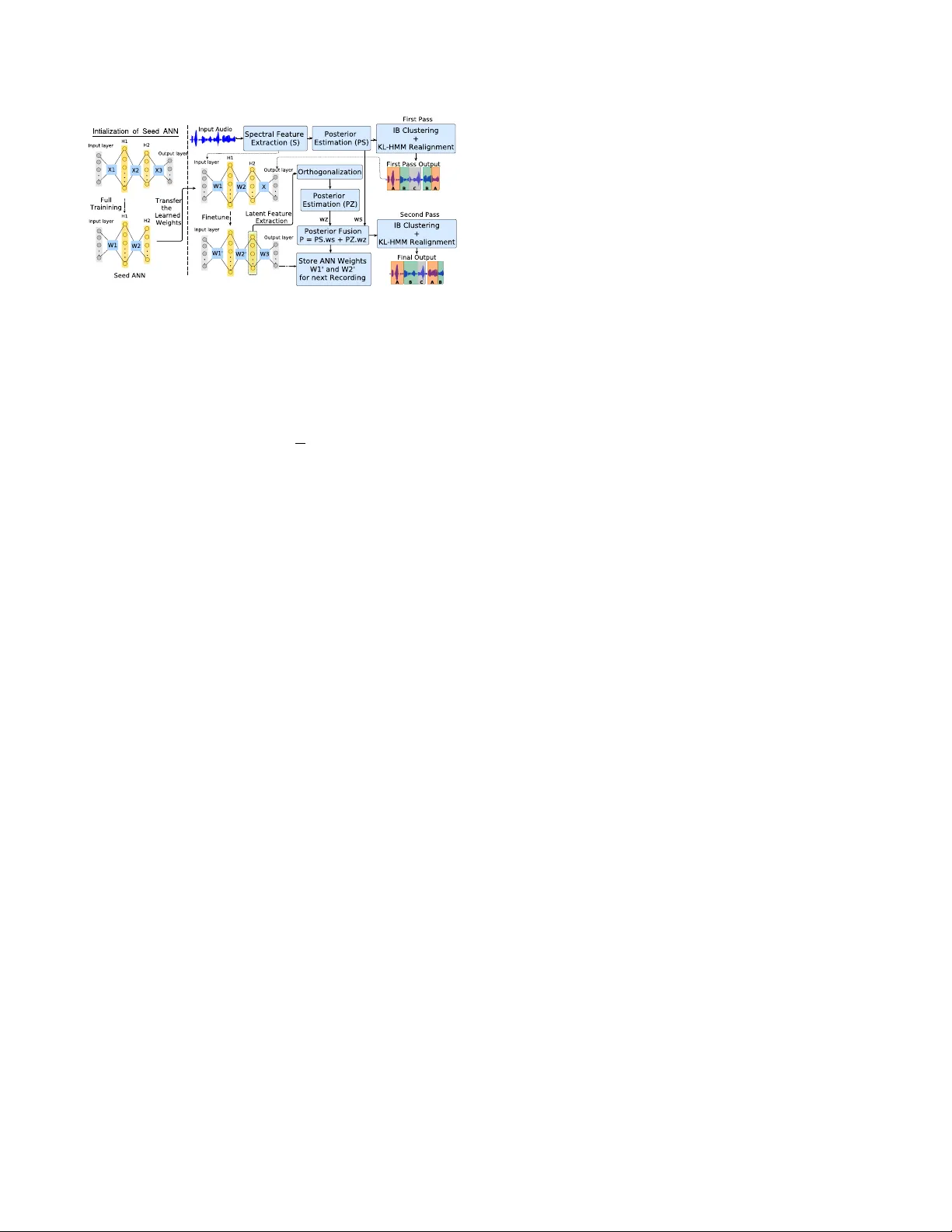
INCREMENT AL TRANSFER LEARNING IN TWO-P ASS INFORMA TION BO TTLENECK B ASED SPEAKER DIARIZA TION SYSTEM FOR MEETINGS Nauman Dawalatabad 1 , Srikanth Madikeri 2 , C Chandra Sekhar 1 , Hema A Murthy 1 1 Indian Institute of T echnology Madras, India 2 Idiap Research Institute, Martigny , Switzerland ABSTRA CT The two-pass information bottleneck (TPIB) based speaker diarization system operates independently on different con- versational recordings. TPIB system does not consider pre- viously learned speaker discriminati ve information while di- arizing new conv ersations. Hence, the real time factor (R TF) of TPIB system is high o wing to the training time required for the artificial neural network (ANN). This paper attempts to improve the R TF of the TPIB system using an incremental transfer learning approach where the parameters learned by the ANN from other con versations are updated using current con versation rather than learning parameters from scratch. This reduces the R TF significantly . The effecti veness of the proposed approach compared to the baseline IB and the TPIB systems is demonstrated on standard NIST and AMI con- versational meeting datasets. W ith a minor de gradation in performance, the proposed system shows a significant im- prov ement of 33.07% and 24.45% in R TF with respect to TPIB system on the NIST R T -04Eval and AMI-1 datasets, respectiv ely . Index T erms — Speaker diarization, transfer learning, in- formation bottleneck 1. INTRODUCTION Speaker diarization systems determine “who spoke when?” in a con versational recording [1, 2]. Diarization has applications in telephone con versations, meetings, broadcast news, and TV shows. Diarizing con versational meetings is challeng- ing o wing to the dynamic nature of speaker switching. The diarization output is often used as a front-end in speech ap- plications like automatic speech recognition [3] and speaker linking in a large corpus [4, 5]. Agglomerativ e hierarchical clustering is the most used approach for diarization, where short segments of speech are clustered in a bottom-up manner . Speaker diarization systems based on hidden Markov model/ Gaussian mixture model (HMM/GMM) [6] and information bottleneck (IB) approach [7] are the most popular . Real T ime Factor (R TF) is defined as the ratio of the time taken by an algorithm to the duration of the input. IB based diarization systems are significantly fast and are suitable for real time applications [7, 8]. T o enable better speaker dis- crimination, there has been numerous efforts in finding the deep neural network (DNN) based speaker discriminativ e em- beddings [9 – 15]. Different network architectures and/or loss functions are used to obtain speaker discriminati ve represen- tations. Howev er , in all cases, the DNN needs to be trained on huge amounts of labeled/unlabelled data. The two-pass IB based speaker diarization (TPIB) [16] system is a recently proposed unsupervised approach that does not use an y sepa- rate training data to learn speaker discriminati ve characteris- tics. In this approach, the speak er discriminating features are automatically learned from the current conv ersational record- ing to be diarized. Although the error rates reported by TPIB system are better than the IB system, the R TF is high mainly due to the increased time for training the artificial neural net- work (ANN). In this paper , we attempt to impro ve the R TF of the TPIB system. All the unsupervised methods (including the TPIB system) operate independently on different audio recordings under consideration. The information learned during diariz- ing one recording can be used to improve the diarization on another recording. The system should remember the pre vi- ous speaker discriminating kno wledge, learn new information and then transfer this information incrementally for diarizing other audio recordings. This “Remember–Learn–T ransfer” approach is the natural way for humans. W e propose to use transfer learning across recordings in an incremental fashion to learn speaker discriminating features continuously . The paper is organized as follows. Section 2 briefly ex- plains the IB and TPIB systems. In Section 3 we describe the proposed system. Section 4 presents the results of all systems on different datasets. Finally , Section 5 concludes the paper . 2. INFORMA TION BO TLLENECK B ASED SYSTEMS This section briefly describes the IB and TPIB systems. 2.1. Baseline Information Bottleneck System In agglomerati ve information bottleneck algorithm [7], short segments X of speech are clustered in a bottom-up manner . A GMM is modeled using X where the GMM components are denoted by Y , and represent relev ant information. The IB T o appear in Pr oc. ICASSP 2019, May 12-17, 2019, Brighton, UK. c IEEE 2019 Fig. 1 : Bloc k diagram of the pr oposed system (TPIB-ITL). based approach clusters the set of segments X into a set of clusters C such that most of the rele vant information about Y is captured. The objectiv e function F is gi ven by F = I( Y , C ) − 1 β I( C , X ) (1) where I( · ) denotes the mutual information and β is a La- grange multiplier . The normalized mutual information (NMI) [7] is used as a criterion for terminating the clustering process. 2.2. T wo-pass IB based Diarization System T wo-pass IB (TPIB) based speaker diarization system [16] consists of 2 passes of the IB diarization as giv en below . - F irst pass : In the first pass, standard IB based diarization is performed followed by Kullback-Leibler hidden Marko v model (KL-HMM) based realignment [17]. - ANN T raining, F eature Extraction and Orthogonalization : ANN initialized with random weights is trained on the output boundary labels and the spectral features obtained in the first pass. Latent features are extracted from the penultimate layer of the trained ANN. Principal component analysis (PCA) is then applied to whiten the features. - Second pass : The latent features are used along with the spectral features in the second pass of IB clustering which is then followed by a KL-HMM based realignment. 3. TPIB WITH INCREMENT AL TRANSFER LEARNING T ransfer learning is the improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned [18]. In TPIB system, the ANN learns the parameters from scratch for each conv ersation indepen- dent of the other . It is the primary bottleneck in terms of run time. W e attempt to solve this problem by retaining the knowledge learned by the model from other audio recordings. New discriminativ e information from the current recording is used to learn more speaker discriminati ve features. As shown in Fig. 1, the following steps are in volved in the proposed TPIB system with incremental transfer learning (TPIB-ITL). - Step 0 - T raining seedANN: A seedAN N is trained from the first audio to be diarized by the system. W e first perform IB based diarization follo wed by KL-HMM based realign- ment to get the relati ve speaker labels. W e intialize all layers’ weights ( X 1 , X 2 , and X 3 ) of seedAN N using Xavier intial- ization technique as described by Glorot and Bengio in [19]. The obtained speaker labels and the spectral features are used to train the seedAN N . This seedAN N is used for the sub- sequent recordings to be diarized. It is important to note that no separate data is used for training the seedAN N . - Step 1 - First pass: In the first pass, we perform IB based diarization that is followed by KL-HMM based realignment. - Step 2 - Transf er of knowledge and fine-tuning: Unlik e random initialization of ANN weights in TPIB, we initialize the parameters of the current ANN with the parameters of the seedAN N . Howe ver , the number of speaker labels in the first-pass output of the current recording can be different from the number of output neurons in the seedAN N . T o handle this mismatch, the parameters W 1 and W 2 (as shown in Fig. 1) are initialized from the seedAN N . The final layer weights alone are initialized using Xavier initialization ( X ). After initialization, fine-tuning of the ANN is performed for a small number of epochs. Fine-tuning is performed using the first pass output labels and the spectral features of the current recording to be diarized. The fine-tuned ANN weights ( W 1 0 and W 2 0 ) are stored as AN N ∗ . - Step 3 - Latent F eature Extraction and Orthogonalization: Once the ANN is fine-tuned for the current recording, the out- put of the penultimate layer is used as the latent feature (LF) representation. The output features are subjected to PCA for orthogonalization. - Step 4 - P osterior Merging: The latent space features (LSF) are merged with the spectral features [7] as, P ( y | f s t , f z t ) = P ( y | f s t ) .w s + P ( y | f z t ) .w z (2) where f s t and f z t are feature vectors at time t from spectral fea- ture stream s and latent feature stream z , respectively . Here, w s and w z are the weights assigned to the feature streams s and z respecti vely , such that w s + w z = 1. - Step 5 - Second pass: Finally , the second pass of IB clus- tering is performed on P ( y | f s t , f z t ) which is followed by KL- HMM based realignment. This is the final diarization output. For ev ery ne w recording, the parameters of the ANN is initialized with the AN N ∗ . Notice that AN N ∗ gets updated after ev ery fine-tuning step ( Step 2 ) for each recording. 3.1. Remember-Lear n-T ransfer The neural network primarily learns to discriminate between speakers in a recording. The characteristics can therefore be similar across the recordings. The discrimination learned by the ANN on one con versational recording can be useful for training an ANN on another recording. This is missing in the TPIB framework where the already learned speaker dis- criminativ e information is nev er utilized for training any fu- 2 T able 1 : AMI meeting datasets. AMI-1 ES2008c, ES2013a, ES2013c, ES2014d, ES2015a, IS1001c, IS1007a, IS1008c, IS1008d, IS1009c AMI-2 ES2010b, ES2013b, ES2014c, ES2015b, ES2015c, IS1004b, IS1006c, IS1007c, IS1008a, IS1009d ture model. Transfer learning enables the new model to start learning from a better point than starting from random initial- ization, which ultimately leads to faster con ver gence. The fine-tuning of ANN is essential for the current record- ing as we are interested in discriminating the speakers in that recording. Moreov er , this also helps to get rid of problems of unseen speakers (or classes). The fine-tuning is performed on ev ery new recording, which can lead to additional speak er discriminativ e information. Hence, the ANN model gets bet- ter at discrimination as it continuously learns from pre viously diarized con versations. 4. EXPERIMENT AL SETUP AND RESUL TS This section explains the datasets, experimental setup and re- sults obtained. 4.1. Dataset, Featur es and Evaluation Measure Experiments are performed on standard NIST -R T (R T -04Dev , R T -04Eval, R T -05Eval) [20] datasets and on the subsets of Augmented Multi-Party Interaction (AMI) corpus [21]. The list of meeting IDs from AMI datasets recorded at Idiap (IS) and Edinbur gh (ES) is giv en in T able 1. These are the same AMI meetings selected randomly in [16] for e valuation. The number of speakers in the NIST dataset ranges from 3 to 8 whereas there are four speakers in each of the AMI record- ings. Most recordings have a different set of speakers. R T - 04Dev was used as the development dataset and remaining datasets were used for the testing purpose. Mel frequency cepstral coef ficients (MFCC) of 19 dimen- sions e xtracted with 10 ms shift from 26 filterbanks are used as input spectral features. Diarization error rate (DER) is the sum of missed speech (MS), false alarm (F A) and speaker er - ror rate (SER). The MS and F A depend on errors in speech activity detection whereas the SER is due to the speak er mis- match. As the focus of the paper is primarily on cluster- ing, speech/non-speech hypotheses were obtained from the ground truth and SER is used as the ev aluation metric. As the proposed system does not use any separate training data (la- belled/unlabelled) to obtain speaker discriminativ e features, we compare the performance of the proposed system to the baseline IB and the TPIB systems. W e kept a forgi veness collar of 0.25 sec and included ov erlapped speech in our e val- uations. 4.2. Models and Experimental Setup A multi-layer feed-forward neural network (MLFFNN) with 2 hidden layers was used for both TPIB and TPIB-ITL sys- T able 2 : Speaker Error Rate (SER) on dif ferent systems are mentioned. The feature fusing weights are mentioned in parentheses. A vg. denotes the a verage SER over all fusing weights combination. Best SER on both systems for each dataset is indicated in bold font. System Feature(s) Dev . Set T est Sets R T -04Dev R T -04Eval R T -05Eval AMI-1 AMI-2 IB MFCC 15.1 13.5 16.4 17.9 23.5 TPIB LSF 15.1 11.6 14.2 17.5 21.3 MFCC+LSF (0.8, 0.2) 13.1 12.5 16.6 16.4 22.7 MFCC+LSF (A vg.) 14.9 12.6 15.3 17.8 22.4 Proposed System TPIB-ITL LSF 15.5 12.5 15.1 17.5 22 MFCC+LSF (0.1, 0.9) 15.2 12.2 15 18 21.2 MFCC+LSF (A vg.) 15.8 12.5 15.4 17.8 21.9 TPIB-ITL (Dev .) LSF 15.5 12.9 14.8 17.5 22.1 MFCC+LSF (0.1, 0.9) 15.2 12.5 15 17.5 22 MFCC+LSF (A vg.) 15.8 13.3 15.6 17.8 22.5 tems. The first layer has 30 neurons with tanh acti vation function and the second layer has 16 neurons with linear func- tion. W e use T ensorFlow’ s implementation of stochastic gra- dient descent with cross-entropy loss function to train/fine- tune the ANN models. All the weights were initialized using Xa vier initializa- tion. The early stopping criterion based on cross-entropy er - ror was set to achiev e the best results on the de velopment set in terms of both, SER and R TF . This implementation of TPIB system gav e lower R TF for TPIB than that reported in [16]. The results reported in T able 2 for TPIB-ITL are when the system is ex ecuted in the standard chronological order of the meeting Ids within the dataset. The sequence of the datasets used is also the same as shown (left to right) in T able 2. This standard sequence is maintained just for reproducibility of the results. Ho wever , similar trends were observed when the TPIB-ITL system was run on 10 different random permuta- tions of the meeting sequences with dif ferent recording for seedAN N . As we will show in the next section, the order of meetings does not influence the o verall performance of TPIB- ITL. As the system uses information from previous record- ings, an alternati ve e xperiment was also conducted. Here, the incremental transfer learning is performed only on dev elop- ment data. The parameters of the ANN for each test con ver- sation are then fine-tuned from the trained ANN independent of the other con versations. The trained ANN is used for all the test recordings independently . The SERs for this experiment is given in TPIB-ITL (De v .) (i.e., last ro w of T able 2). The number of fine-tuning epochs was set to 50 for both TPIB-ITL and TPIB-ITL (Dev .). W e use open source IB toolkit [22] in all the experiments. The v alues of NMI and β were set to 0.4 and 10, respectiv ely . All R TFs are calculated on 2.6 GHz CPU with 2 threads. The reported R TFs are calculated by averaging the R TFs across 10 independent runs. All the results reported in this paper are based on the best performing parameters tuned on the devel- opment dataset. 3 T able 3 : The R TF on dif ferent systems for different datasets are mentioned. Impr . denotes the relati ve improvement in R TF with respect to TPIB system. The observed de viation in R TFs is between 0.002–0.004 on NIST datasets and 0.003– 0.007 on AMI datasets. Sys/Dataset R T -04Dev R T -04Eval R T -05Eval AMI-1 AMI-2 IB 0.070 0.081 0.086 0.241 0.304 TPIB 0.248 0.257 0.254 0.642 0.740 TPIB-ITL 0.175 0.172 0.180 0.485 0.605 Impr . (%) 29.44 33.07 29.13 24.45 18.24 4.3. Results and Discussion The SERs for dif ferent approaches to diarization are gi ven in T able 2. It can be seen that both the proposed system (TPIB- ITL) and the TPIB system outperform the baseline IB system in most cases. The SERs of TPIB and TPIB-ITL systems are comparable. The TPIB-ITL system sho wed an absolute improv ement of 2.3% with respect to the baseline IB sys- tem on AMI-2 dataset. Though the best feature combination tuned on development set gi ves better SER than the IB sys- tem, we observed that it may not always sho w improvement ov er LSF . This happens when the extracted LSF itself is bet- ter at speaker discrimination than the combination. Hence to check the ov erall behaviour of the system under different fea- ture fusing weights, we also pro vide the a veraged SER across all the feature fusing weights for each dataset. It gi ves a mea- sure of robustness of the system to the feature fusing weights. It can be seen from T able 2 that the a verage SER of the pro- posed system show absolute 1.6% improv ement on AMI-2 dataset. This is significant, as it is calculated ov er the a verage of all possible feature fusing weight combinations. It con- firms the robustness of the TPIB-ITL system to the feature fusing weight combinations. The SER on dev elopment data for TPIB-ITL is slightly higher than other systems. This is expected as the ANN has learned speaker discrimination from only a fe w recordings. Its performance is better on the test data, as incremental trans- fer learning happens. The improvement in SER can be ob- served on all test datasets. A verage SER (avg.) of 21.9% is observed for TPIB-ITL system on AMI-2 (last dataset in se- quence) whereas it is 22.4% for TPIB system. This confirms that the ANN model in TPIB-ITL gets better ov er time. T o ensure that the results are not biased towards order- ing of meetings, e xperiments were conducted for random per- mutations with random seedAN N . The overall trend in the result was observed to be similar . For e xample, the aver - age SER for TPIB-ITL ov er all the feature fusing weights on each dataset for one of the random permutations of the meeting sequence dif ferent from the sequence shown in T a- ble 2 is R T -04Dev=15.5, R T -04Eval=12.6, R T -05Eval=14.9, AMI-1=17.7, AMI-2=22.2. This confirms that the sequence of recordings does not influence the overall performance of the proposed system. The results where the training of ANN is used incremen- (a) R T -05Eval Dataset (b) AMI-2 Dataset Fig. 2 : R TFs of individual modules for all systems. tally in TPIB-ITL using only dev elopment data is gi ven in TPIB-ITL(Dev .) (last row of the T able 2). The system out- performs the baseline IB system and is comparable to TPIB system. Notice that the system does not use any labeled in- formation from the de velopment dataset (R T -04Dev). More- ov er, it should also be noted that the R T -04Dev is a very small dataset comprising of only 8 meeting recordings. A significant improvement in R TF is obtained ov er the TPIB system. It can be seen from T able 3 that the best case improv ement of 33.07% in R TF is observed on R T -04Eval dataset for TPIB-ITL system. The R TFs for all NIST -R T datasets are in a similar range. As the meeting duration in AMI datasets is longer than that in NIST -R T datasets, the R TF of the IB system itself is more for AMI datasets. Neverthe- less, we observe improvements in R TF of 24.45% and 18.24% for AMI-1 and AMI-2 datasets, respecti vely . Though TPIB- ITL system seems inherently sequential, it can be easily run in parallel on different batches of recordings. The IB sys- tem showed an av erage (over all datasets) error of 2.2 in es- timating a correct number of speakers, whereas the TPIB and TPIB-ITL showed a similar a verage error of 1.15 speakers. Fig. 2 sho ws module-wise R TF for all the systems on tw o datasets; NIST R T -05Eval and AMI-2. Other respectiv e NIST and AMI datasets also show a similar trend. As the orthogo- nalization step takes negligible time, we do not report it. From Fig. 2, it can be seen that considerable time is consumed in the ANN model training stage which is reduced significantly by TPIB-ITL system on both NIST and AMI datasets. 5. CONCLUSION The proposed TPIB-ITL system uses “Remember-Learn- T ransfer” principle to incrementally learn speaker discrimi- nativ e characteristics. The ANN model gets better at speaker discrimination over time e ven with a small number of fine- tuning epochs. With a minor de gradation in performance, the proposed system show a significant impro vement of 33.07% and 24.45% in R TF on R T -04Eval and AMI-1 datasets over TPIB system, respectiv ely . Since the proposed system fol- lows the TPIB framework, it also inherits the advantages of the TPIB framework, i.e., (i) No separate training data is needed, and (ii) It incorporates recording-specific speaker discriminativ e features during the diarization process. 4 6. REFERENCES [1] Xavier Anguera Miro, Simon Bozonnet, Nicholas Evans, Corrine Fredouille, Gerald Friedland, and Ori- ols V inyals, “Speaker Diarization: A Revie w of Recent Research, ” IEEE T ransactions on Audio, Speech, and Language Processing , vol. 20, no. 2, pp. 356–370, 2012. [2] Sue E. T ranter and Douglas Reynolds, “An Overvie w of Automatic Speaker Diarization Systems, ” IEEE T rans- actions on Audio, Speech, and Language Pr ocessing , vol. 14, no. 5, pp. 1557–1565, 2006. [3] Dimitrios Dimitriadis and Petr Fousek, “De veloping On-Line Speaker Diarization System, ” in Pr oceedings of INTERSPEECH , 2017, pp. 2739–2743. [4] Douglas E Sturim and W illiam M Campbell, “Speaker Linking and Applications Using Non-Parametric Hash- ing Methods., ” in Pr oceedings of INTERSPEECH , 2016, pp. 2170–2174. [5] Marc Ferras, Srikanth Madikeri, and Herv ´ e Bourlard, “Speaker Diarization and Linking of Meeting Data, ” IEEE/A CM T ransactions on A udio, Speech & Language Pr ocessing , vol. 24, no. 11, pp. 1935–1945, 2016. [6] Jitendra Ajmera and Charles W ooters, “A Ro- bust Speaker Clustering Algorithm, ” in IEEE Auto- matic Speech Recognition and Understanding W orkshop (ASR U) , 2003, pp. 411–416. [7] Deepu V ijayasenan, F abio V alente, and Herv e Bourlard, “An Information Theoretic Approach to Speaker Di- arization of Meeting Data, ” IEEE T ransactions on Au- dio, Speech, and Language Pr ocessing , vol. 17, no. 7, pp. 1382–1393, 2009. [8] Srikanth Madikeri, David Imseng, and Herv ´ e Bourlard, “Improving Real T ime Factor of Infor- mation Bottleneck-based Speaker Diarization System, ” , no. Idiap-RR-18-2015, 2015. [9] Sree H. Y ella, Andreas Stolcke, and Malcolm Slane y , “ Artificial Neural Network Features for Speaker Di- arization, ” in IEEE Spoken Languag e T echnology W ork- shop (SLT) , 2014, pp. 402–406. [10] Ga ¨ el Le Lan, Delphine Charlet, Anthony Larcher, and Sylvain Meignier , “A T riplet Ranking-based Neural Network for Speaker Diarization and Linking, ” in Pro- ceedings of INTERSPEECH , 2017, pp. 3572–3576. [11] Herv ´ e Bredin, “T ristounet: T riplet loss for speaker turn embedding, ” IEEE International Conference on Acous- tics, Speech and Signal Pr ocessing (ICASSP) , pp. 5430– 5434, 2017. [12] Daniel Garcia-Romero, David Snyder , Gregory Sell, Daniel Pov ey , and Alan McCree, “Speaker Diarization using Deep Neural Network Embeddings, ” in IEEE In- ternational Confer ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 2017, pp. 4930–4934. [13] Quan W ang, Carlton Do wney , Li W an, Philip Andrew Mansfield, and Ignacio Lopz Moreno, “Speaker Diariza- tion with LSTM, ” IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , pp. 5239–5243, 2018. [14] David Snyder , Daniel Garcia-Romero, Gregory Sell, Daniel Povey , and Sanjeev Khudanpur , “X-V ectors: Ro- bust DNN Embeddings for Speaker Recognition, ” IEEE International Confer ence on Acoustics, Speech and Sig- nal Pr ocessing (ICASSP) , pp. 5329–5333, 2018. [15] Arindam Jati and P anayiotis Georgiou, “Neural Predic- tiv e Coding using Con volutional Neural Networks to- wards Unsupervised Learning of Speaker Characteris- tics, ” ArXiv e-prints , Feb . 2018. [16] Nauman Daw alatabad, Srikanth Madikeri, C. Chandra Sekhar , and Hema A. Murthy , “T wo-Pass IB Based Speaker Diarization System Using Meeting-Specific ANN Based Features, ” in Pr oceedings of INTER- SPEECH , 2016, pp. 2199–2203. [17] Deepu V ijayasenan, F abio V alente, and Herv ´ e Bourlard, “KL Realignment for Speaker Diarization with Multiple Feature Streams, ” in Pr oceedings of INTERSPEECH , Sept 2009, pp. 1059–1062. [18] Emilio Soria Oliv as et al., Handbook Of Resear ch On Machine Learning Applications and T r ends: Algo- rithms, Methods and T echniques - 2 V olumes , Infor - mation Science Reference - Imprint of: IGI Publishing, Hershey , P A, 2009. [19] Xavier Glorot and Y oshua Bengio, “Understanding the difficulty of training deep feedforward neural networks, ” in Pr oceedings of the Thirteenth International Confer - ence on Artificial Intelligence and Statistics , 2010, pp. 249–256. [20] “The NIST Rich T ranscription, ” https://www .nist.gov/itl. [21] Jean Carletta et al., “The AMI Meeting Corpus: A Pre- announcement, ” in Pr oceedings of the Second Interna- tional Confer ence on Machine Learning for Multimodal Interaction , 2006, MLMI’05, pp. 28–39. [22] Deepu V ijayasenan and Fabio V alente, “DiarTk: An Open Source T oolkit for Research in Multistream Speaker Diarization and its Application to Meetings Recordings, ” in Pr oceedings of INTERSPEECH , 2012. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment