Parameter Estimation using Neural Networks in the Presence of Detector Effects
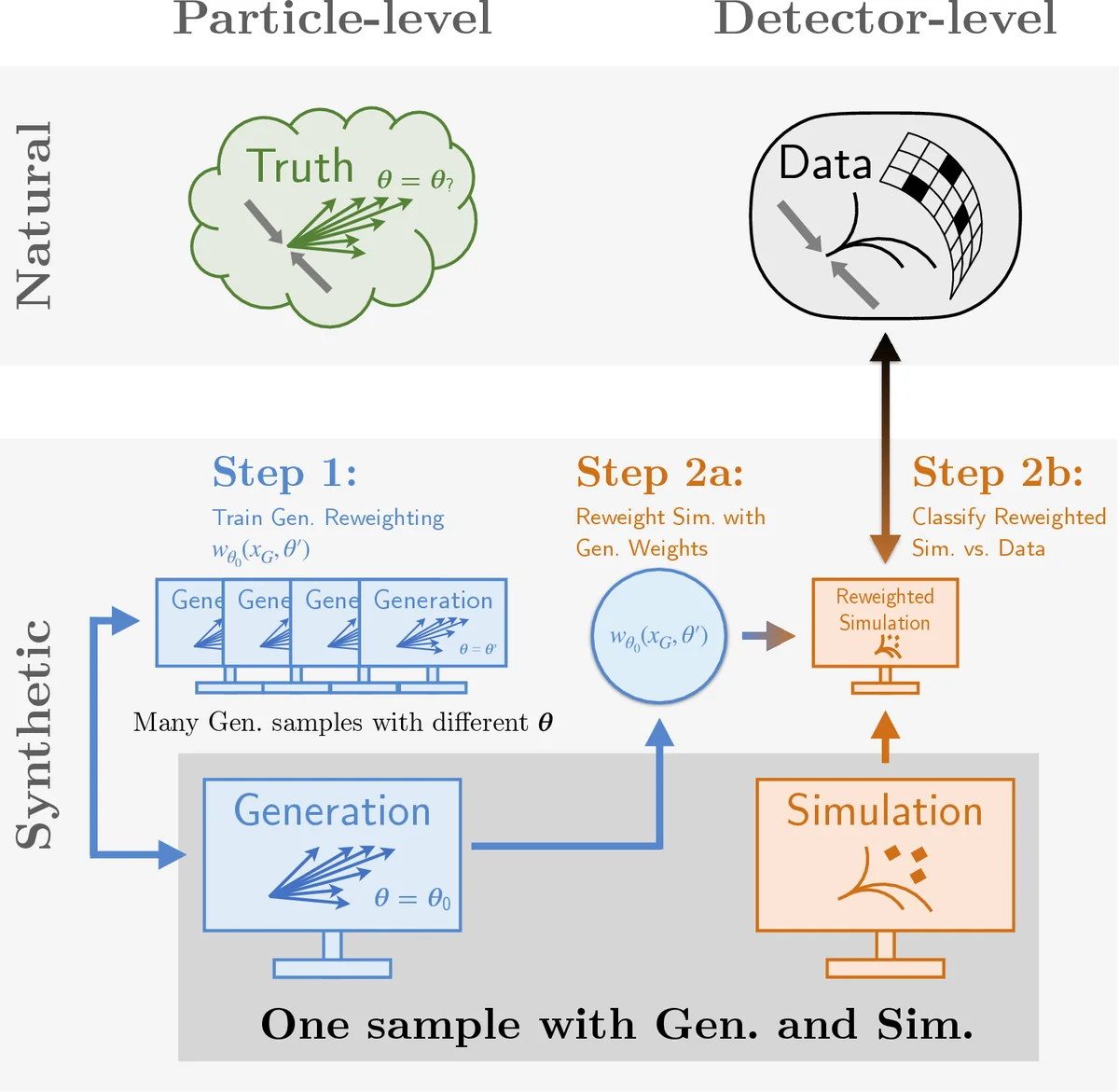
Histogram-based template fits are the main technique used for estimating parameters of high energy physics Monte Carlo generators. Parametrized neural network reweighting can be used to extend this fitting procedure to many dimensions and does not require binning. If the fit is to be performed using reconstructed data, then expensive detector simulations must be used for training the neural networks. We introduce a new two-level fitting approach that only requires one dataset with detector simulation and then a set of additional generation-level datasets without detector effects included. This Simulation-level fit based on Reweighting Generator-level events with Neural networks (SRGN) is demonstrated using simulated datasets for a variety of examples including a simple Gaussian random variable, parton shower tuning, and the top quark mass extraction.
💡 Research Summary
The paper introduces a novel two‑stage fitting framework called SRGN (Simulation‑level fit based on Reweighting Generator‑level events with Neural networks) designed to estimate parameters of high‑energy‑physics Monte Carlo generators while dramatically reducing the need for costly detector‑level simulations. Traditional template fits rely on binned histograms and require a separate detector‑level simulated sample for each point in parameter space, which becomes prohibitive when many parameters or high‑dimensional observables are involved.
SRGN separates the problem into (1) a generator‑level reweighting step and (2) a simulation‑level fitting step, each implemented with a binary classifier neural network. In the first step, a classifier f is trained on pairs of events generated at a reference parameter θ₀ and at a variety of other parameter values θ. Using the binary cross‑entropy loss, f(x,θ) approximates the likelihood ratio p(x|θ)/p(x|θ₀), which directly yields a continuous reweighting function w_θ₀(x_G,θ). Because this training uses only generator‑level data, an essentially unlimited number of parameter points can be explored without any detector simulation.
In the second step, a single detector‑level simulated dataset (generated at θ₀ and passed through a fast or full detector emulator) is reweighted event‑by‑event using w_θ₀. A second classifier g is then trained to distinguish the reweighted simulated events from the real (or unfolded) data. The goodness‑of‑fit is quantified by the area under the ROC curve (AUC); the optimal parameters θ* are those that minimize the AUC, i.e., make the classifier unable to tell the two samples apart. Since AUC is not differentiable, SRGN employs non‑gradient optimisation (e.g., Bayesian optimisation, evolutionary algorithms) to locate the minimum.
The authors provide a theoretical analysis showing that SRGN is unbiased when the generator‑level feature set X_G contains the full phase space Ω necessary to describe the detector response, i.e., when p(X_S|X_G,θ₀)=p(X_S|X_G,θ). Under this condition the reweighted simulation reproduces the true detector‑level distribution for the correct θ, guaranteeing θ* = θ_true. If important generator‑level variables are omitted, bias appears, which the authors demonstrate with controlled toy examples.
Three empirical studies illustrate the method.
- Gaussian toy model – With a one‑dimensional Gaussian generator variable and additive Gaussian smearing, the analytically known reweighting function matches the neural‑network‑learned one. Extending to a two‑dimensional generator space with non‑uniform smearing shows that using the full generator information yields perfect reweighting, whereas using only a subset fails.
- Parton‑shower tuning – High‑dimensional shower parameters (α_s, Λ_QCD, etc.) are tuned using SRGN. Compared to traditional histogram‑based tuning, SRGN achieves comparable or better parameter recovery while requiring only a single detector‑level simulation, thus saving orders of magnitude in CPU time.
- Top‑quark mass extraction – A realistic top‑mass measurement is performed with detector effects such as energy scale shifts and resolution smearing. SRGN recovers the top‑mass value with precision matching standard template fits, but the computational cost is reduced by roughly a factor of ten because only one full detector simulation is needed.
The paper also discusses practical considerations: the need for careful selection of generator‑level features to ensure the full phase‑space condition, the choice of non‑gradient optimisation algorithm for the AUC minimisation, and the impact of classifier capacity and training statistics on the stability of the reweighting function.
In summary, SRGN offers a powerful, scalable alternative to conventional template fitting. By leveraging neural‑network classifiers for both reweighting and goodness‑of‑fit evaluation, it enables unbiased parameter estimation in high‑dimensional spaces with dramatically fewer detector‑level simulations. This approach is poised to benefit large‑scale LHC analyses, future collider studies, and any domain where costly forward simulations limit the feasibility of exhaustive parameter scans.
Comments & Academic Discussion
Loading comments...
Leave a Comment