Stochastic parameterization with VARX processes
💡 Research Summary
This paper introduces a data‑driven stochastic parameterization framework for multiscale dynamical systems, focusing on the well‑known Lorenz‑96 (L96) testbed. The authors propose to model the unresolved small‑scale feedback term by a Vector Autoregressive process with eXogenous variables (VARX). The VARX model is written as
(e_b^n = a_0 + \sum_{i=1}^p A_i e_b^{n-i} + D x^n + \Sigma \xi^n,)
where (e_b^n) represents the stochastic approximation of the small‑scale forcing, (x^n) is the resolved large‑scale state, (A_i) are endogenous drift matrices, (D) is the exogenous drift matrix, (\Sigma) is the noise covariance, and (\xi^n) is a standard Gaussian white noise vector. All matrices have dimension (K \times K), with (K) the number of spatial grid points of the large‑scale field.
A central contribution is the systematic reduction of the number of free parameters. By imposing sparsity patterns—most prominently diagonal structures—on the drift matrices (A_i), (D) and on the covariance (\Sigma), the total number of parameters grows only linearly with (K) (or quadratically when a dense covariance is used). This makes the approach feasible for high‑dimensional geophysical models where (K) can be of order (10^5) or larger.
Parameter estimation is performed by weighted least squares on a training dataset ((X,B)) obtained from a fully resolved L96 simulation. The regression step has computational complexity (\mathcal{O}(K^2 N)) (with (N) the number of samples), and the covariance is estimated either as a scalar multiple of the identity ((\Sigma_D = \sigma I)) or as a full sample covariance matrix ((\Sigma_L)), the latter requiring a Cholesky decomposition of size (\mathcal{O}(K^3)). The authors verify a posteriori that the estimated VARX models satisfy the VAR stability condition (all eigenvalues of the companion matrix lie inside the unit circle).
Two L96 configurations are examined. The first uses standard forcing (F=10) and coupling, yielding a unimodal invariant distribution for the large‑scale variables. The second employs non‑standard parameters (e.g., reduced forcing) that generate a trimodal distribution, representing a much more challenging test case. For the unimodal case, a VARX(30) model with diagonal covariance ((\Sigma_D)) reproduces the mean, autocorrelation, spatial correlation, and probability density function of the reference model with high fidelity. For the trimodal case, the diagonal covariance is insufficient; only a VARX(30) model with a dense covariance ((\Sigma_L)) captures the multiple peaks and the transitions between them, demonstrating the importance of cross‑grid covariances for complex multimodal dynamics.
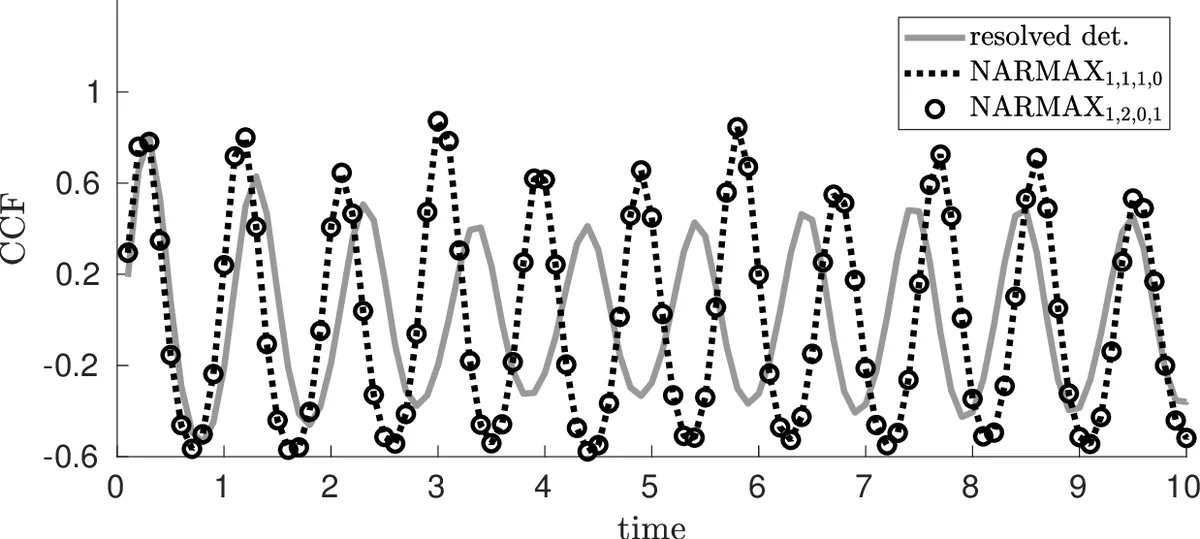
The paper also benchmarks the proposed VARX approach against three alternative stochastic parameterizations: (i) white noise (WN), which adds an unconditioned stochastic term; (ii) independent AR(1) processes applied separately at each grid point; and (iii) NARMAX models previously used in the literature. Across a suite of statistical diagnostics (mean, variance, lag‑1 autocorrelation, spatial correlation, and full PDFs), the VARX models consistently outperform the simpler schemes. The inclusion of the exogenous matrix (D) allows the stochastic term to depend explicitly on the current large‑scale state, a feature absent in the AR(1) and NARMAX baselines.
Computational cost analysis shows that training is cheap (single least‑squares solve) and that online integration cost is dominated by matrix‑vector products. With diagonal drift and noise matrices the cost scales linearly with (K); with banded drift matrices it scales as (K) times the bandwidth; with a dense covariance the cost becomes (\mathcal{O}(K^2)), which may become a bottleneck for very large systems. The authors note that designing statistically consistent sparse approximations of the covariance for large (K) is an open research direction.
In conclusion, the study demonstrates that VARX‑based stochastic parameterizations can accurately reproduce both simple and highly non‑Gaussian statistics of multiscale systems while keeping the number of estimated parameters manageable. Diagonal covariance suffices for unimodal regimes, whereas dense covariance is required for multimodal regimes. Future work is suggested on enforcing stability constraints during estimation, developing efficient sparse covariance structures, and applying the methodology to realistic climate‑ocean models.
Comments & Academic Discussion
Loading comments...
Leave a Comment