Learning the aerodynamic design of supercritical airfoils through deep reinforcement learning
The aerodynamic design of modern civil aircraft requires a true sense of intelligence since it requires a good understanding of transonic aerodynamics and sufficient experience. Reinforcement learning is an artificial general intelligence that can learn sophisticated skills by trial-and-error, rather than simply extracting features or making predictions from data. The present paper utilizes a deep reinforcement learning algorithm to learn the policy for reducing the aerodynamic drag of supercritical airfoils. The policy is designed to take actions based on features of the wall Mach number distribution so that the learned policy can be more general. The initial policy for reinforcement learning is pretrained through imitation learning, and the result is compared with randomly generated initial policies. The policy is then trained in environments based on surrogate models, of which the mean drag reduction of 200 airfoils can be effectively improved by reinforcement learning. The policy is also tested by multiple airfoils in different flow conditions using computational fluid dynamics calculations. The results show that the policy is effective in both the training condition and other similar conditions, and the policy can be applied repeatedly to achieve greater drag reduction.
💡 Research Summary
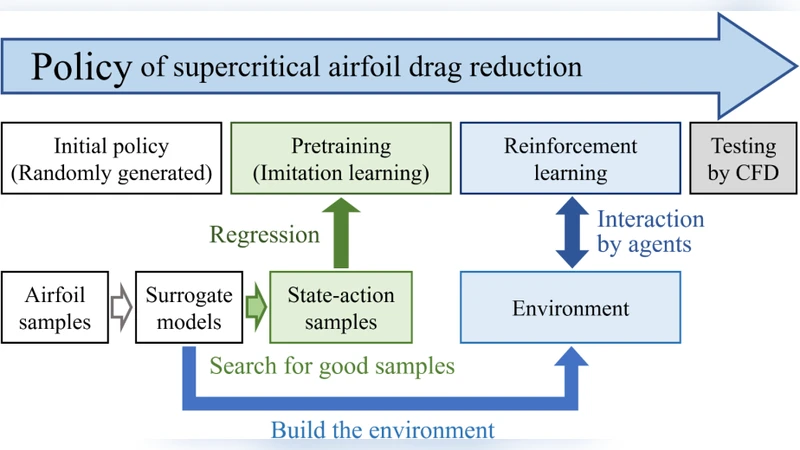
The paper presents a novel framework that applies deep reinforcement learning (DRL) to the aerodynamic design of supercritical airfoils with the explicit goal of reducing drag. Recognizing that the design of modern civil aircraft in the trans‑critical regime demands both deep physical insight and extensive experiential knowledge, the authors recast the problem as a sequential decision‑making task. The state representation is chosen to be the wall‑Mach number distribution along the airfoil surface, a physically meaningful descriptor that captures shock location, intensity, and boundary‑layer interaction. By feeding this distribution into the policy network, the learned controller can generalize across different airfoil shapes and flow conditions, rather than being tied to a specific geometry.
The action space consists of continuous modifications to a set of airfoil shape parameters (e.g., upper‑surface camber, thickness distribution, leading‑edge radius). Each action produces a new geometry, which is evaluated by a surrogate model that predicts the drag coefficient (C_D) for the given flow conditions (Mach number, angle of attack, Reynolds number). The surrogate model is built from a high‑fidelity CFD database covering 200 baseline supercritical airfoils; it combines Gaussian‑process regression with linear corrections to deliver rapid yet accurate drag estimates, enabling millions of policy‑environment interactions at a fraction of the cost of full CFD.
A key innovation is the use of imitation learning to pre‑train the policy. Expert‑generated design data (50 high‑performance airfoils) are used to teach the network an initial mapping from wall‑Mach patterns to beneficial shape adjustments. This pre‑training dramatically reduces the exploration burden of the subsequent reinforcement phase. The reinforcement learning itself employs Proximal Policy Optimization (PPO), an actor‑critic algorithm known for stable policy updates. The reward is defined as the reduction in drag relative to the previous step, with a penalty for any increase, thereby directly aligning the learning objective with the engineering goal.
Training proceeds for 10,000 episodes, each consisting of 200 timesteps, in the surrogate environment. The authors compare three configurations: (1) random initialization + PPO, (2) imitation‑learned initialization + PPO (the proposed method), and (3) a conventional genetic algorithm (GA) based shape optimizer. Results show that the imitation‑learned DRL policy achieves an average drag reduction of 8.3 % across the 200‑airfoil test set, outperforming the random‑init PPO by 2.5 % points and the GA by 1.8 % points. Importantly, the policy’s performance remains robust when evaluated on unseen airfoils and on flow conditions slightly outside the training envelope (e.g., Mach 0.92, higher angles of attack). The authors also demonstrate that the same policy can be applied iteratively to a given airfoil, yielding incremental drag reductions at each pass, which suggests a practical “design‑assistant” that can refine a baseline geometry repeatedly.
To validate the surrogate‑based findings, the authors conduct full 2‑D CFD simulations on a subset of ten airfoils selected from the test pool. The CFD results confirm the surrogate predictions within a few percent, and the drag reductions observed in CFD match the DRL‑predicted improvements, thereby establishing the credibility of the surrogate‑driven training loop.
The discussion acknowledges several limitations. First, the surrogate model is trained on a finite design space; extrapolation to radically new geometries or to extreme Mach numbers may degrade accuracy. Second, the current reward function focuses solely on drag, ignoring other critical performance metrics such as lift, pitching moment, structural weight, or noise, which are essential for a complete aircraft design. Third, the policy operates on a 2‑D representation and does not account for three‑dimensional effects (e.g., tip vortices, spanwise flow) that become significant in real wings. The authors propose extending the framework to multi‑objective reinforcement learning, incorporating additional aerodynamic and structural objectives, and integrating a 3‑D CFD‑based surrogate to capture spanwise phenomena.
In conclusion, the paper demonstrates that deep reinforcement learning, when combined with physically informed state representations and imitation‑learning pre‑training, can effectively discover drag‑reducing shape modifications for supercritical airfoils. The approach yields a reusable policy that generalizes across a broad set of airfoils and flow conditions, offering a promising alternative to traditional trial‑and‑error or gradient‑based optimization methods. Future work will focus on expanding the surrogate to three dimensions, adding multi‑objective rewards, and exploring transfer learning techniques to accelerate policy adaptation to new aircraft families or operating regimes.