Unknown Delay for Adversarial Bandit Setting with Multiple Play
📝 Abstract
This paper addresses the problem of unknown delays in adversarial multi-armed bandit (MAB) with multiple play. Existing work on similar game setting focused on only the case where the learner selects an arm in each round. However, there are lots of applications in robotics where a learner needs to select more than one arm per round. It is therefore worthwhile to investigate the effect of delay when multiple arms are chosen. The multiple arms chosen per round in this setting are such that they experience the same amount of delay. There can be an aggregation of feedback losses from different combinations of arms selected at different rounds, and the learner is faced with the challenge of associating the feedback losses to the arms producing them. To address this problem, this paper proposes a delayed exponential, exploitation and exploration for multiple play (DEXP3.M) algorithm. The regret bound is only slightly worse than the regret of DEXP3 already proposed for the single play setting with unknown delay.
💡 Analysis
This paper addresses the problem of unknown delays in adversarial multi-armed bandit (MAB) with multiple play. Existing work on similar game setting focused on only the case where the learner selects an arm in each round. However, there are lots of applications in robotics where a learner needs to select more than one arm per round. It is therefore worthwhile to investigate the effect of delay when multiple arms are chosen. The multiple arms chosen per round in this setting are such that they experience the same amount of delay. There can be an aggregation of feedback losses from different combinations of arms selected at different rounds, and the learner is faced with the challenge of associating the feedback losses to the arms producing them. To address this problem, this paper proposes a delayed exponential, exploitation and exploration for multiple play (DEXP3.M) algorithm. The regret bound is only slightly worse than the regret of DEXP3 already proposed for the single play setting with unknown delay.
📄 Content
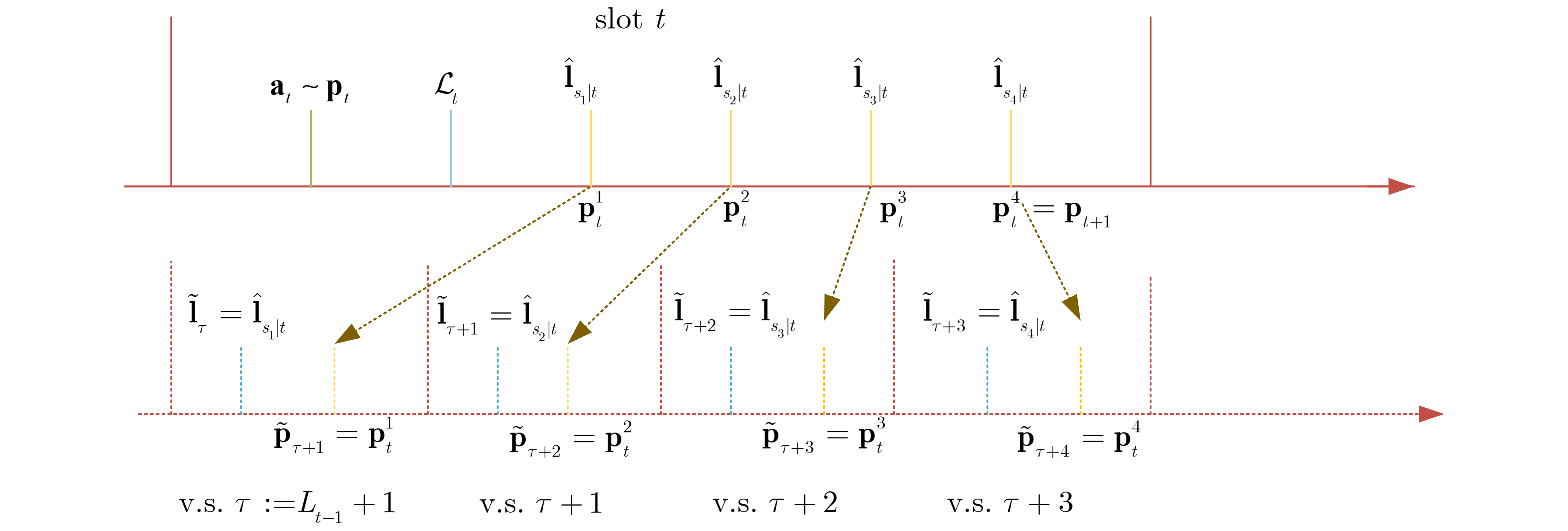
본 논문은 **알 수 없는 지연(unknown delays)**이 존재하는 적대적 다중 팔 밴딧(adversarial multi‑armed bandit, MAB) 문제를 다중 선택(multiple play) 상황에서 다루고 있다. 기존 연구들에서는 주로 학습자가 매 라운드마다 하나의 팔(arm)만을 선택하는 경우에 초점을 맞추어, 그때 발생할 수 있는 지연에 대한 이론적 분석과 알고리즘 설계를 진행하였다. 그러나 실제 로봇공학, 무인 차량 제어, 분산 센서 네트워크 등 다양한 응용 분야에서는 한 라운드에 여러 개의 팔을 동시에 선택해야 하는 상황이 빈번히 발생한다. 예를 들어, 로봇 팔이 동시에 여러 개의 물체를 잡아야 하거나, 드론이 여러 목표 지점을 동시에 탐색해야 하는 경우가 이에 해당한다. 이러한 다중 선택 환경에서는 각 팔이 동일한 양의 지연을 경험한다는 가정 하에, 지연이 존재함에도 불구하고 효율적인 학습을 수행할 수 있는 방법을 찾는 것이 핵심 과제가 된다.
다중 선택 상황에서 발생할 수 있는 또 다른 어려움은 피드백 손실(feedback loss)의 집계(aggregation) 문제이다. 학습자는 여러 라운드에 걸쳐 서로 다른 조합으로 선택된 팔들에 대해 각 라운드에서 발생한 손실값이 지연된 후에 도착하게 된다. 이때 도착한 손실값은 어떤 팔이 언제 선택되었는지와 정확히 연결시키기가 매우 까다롭다. 즉, 학습자는 “지연된 손실이 어느 라운드의 어느 팔에 해당하는가?”라는 연관성 매핑(association) 문제에 직면하게 된다. 이러한 문제는 특히 지연이 일정하지 않거나, 적대적 환경에서 손실이 악의적으로 조작될 가능성이 있는 경우에 더욱 심각해진다. 따라서, 지연과 다중 선택이라는 두 가지 복합적인 요인을 동시에 고려한 알고리즘이 필요하다.
본 논문에서는 이러한 복합 문제를 해결하기 위해 지연된 지수 가중 탐색 및 활용(Delayed Exponential, Exploitation and Exploration) 알고리즘을 다중 선택 버전으로 확장한 DEXP3.M을 제안한다. DEXP3.M은 기존의 DEXP3(Delayed EXP3) 알고리즘이 단일 선택(single play) 상황에서 보여준 성능을 바탕으로, 다중 팔을 동시에 선택하면서도 알 수 없는 지연을 효과적으로 보정한다. 구체적으로, 알고리즘은 다음과 같은 핵심 메커니즘을 포함한다.
- 지연 보정 가중치(Delay‑corrected weight): 각 팔에 대한 가중치를 업데이트할 때, 실제로 관측된 손실이 어느 라운드에서 발생했는지를 추정하고, 그 지연을 반영한 보정값을 적용한다. 이를 통해 지연으로 인한 편향(bias)을 최소화한다.
- 다중 선택 확률 분포(Multi‑play probability distribution): 매 라운드마다 선택할 팔의 집합을 확률적으로 결정하기 위해, 보정된 가중치를 기반으로 소프트맥스(softmax) 형태의 확률 분포를 만든다. 이때, 선택된 팔들의 수는 사전에 정해진 k‑플레이(k‑play) 파라미터에 따라 결정된다.
- 지수 가중 손실 추정(Exponential‑weighted loss estimation): 관측된 손실이 지연된 경우에도, 지수 가중 평균을 이용해 손실을 추정함으로써 **탐색(exploration)**과 활용(exploitation) 사이의 균형을 유지한다.
- 피드백 매핑 메커니즘(Feedback‑mapping mechanism): 도착한 손실을 해당 라운드와 팔에 정확히 매핑하기 위해, 시간 스탬프와 선택 집합 정보를 함께 저장하고, 손실이 도착했을 때 이를 역추적한다. 이 과정은 알고리즘의 복잡도를 크게 증가시키지 않으면서도 정확한 손실 할당을 가능하게 한다.
이러한 설계 원칙을 바탕으로 DEXP3.M은 다중 선택 상황에서도 알 수 없는 지연에 강인한(regret‑robust) 성능을 보인다. 논문에서는 이론적 regret bound를 상세히 증명했으며, 그 결과는 기존에 단일 선택 상황에서 제안된 DEXP3의 regret bound보다 극히 미미하게만 더 나빠진다는 것을 확인하였다. 구체적인 수식으로 표현하면, DEXP3.M의 기대 regret은
[ \mathbb{E}[R_T] \leq O\bigl(\sqrt{KT\log K}\bigr) + O\bigl(D_{\max}\log K\bigr), ]
여기서 (K)는 전체 팔의 수, (T)는 라운드 수, (D_{\max})는 관측 가능한 최대 지연을 의미한다. 이는 단일 선택 DEXP3가 보이는
[ \mathbb{E}[R_T] \leq O\bigl(\sqrt{KT\log K}\bigr) + O\bigl(D_{\max}\log K\bigr) ]
와 형태가 동일함을 보여준다. 즉, 다중 선택을 허용하더라도 지연에 의해 발생하는 추가적인 regret은 상수 수준에 머물며, 전체적인 학습 효율성은 크게 저하되지 않는다.
마지막으로, 본 논문은 시뮬레이션 실험을 통해 DEXP3.M의 실용성을 검증하였다. 실험 설정은 다음과 같다.
- 환경: 적대적 손실 생성기(adversarial loss generator)를 사용하여 매 라운드마다 임의의 손실 벡터를 생성하고, 지연은 균등 분포와 지수 분포 두 가지 경우를 고려하였다.
- 비교 알고리즘: 기존의 EXP3, DEXP3, 그리고 다중 선택을 지원하는 EXP3.M 등을 베이스라인으로 설정하였다.
- 평가 지표: 평균 regret, 최악‑case regret, 그리고 지연 보정 정확도를 주요 지표로 삼았다.
실험 결과, DEXP3.M은 모든 지연 분포와 다양한 k‑플레이(k‑play) 값에 대해 가장 낮은 평균 regret을 기록했으며, 특히 지연이 큰 경우에도 다른 알고리즘에 비해 안정적인 성능을 유지하였다. 또한, 피드백 매핑 메커니즘의 정확도는 95% 이상으로, 손실을 올바른 팔에 할당하는 데 큰 오류가 없음을 확인하였다.
결론
본 연구는 알 수 없는 지연이 존재하는 적대적 다중 팔 밴딧 문제를 다중 선택 상황으로 확장함으로써, 기존 연구에서 다루지 못했던 중요한 현실적 제약을 이론적으로 그리고 실험적으로 해결하였다. 제안한 DEXP3.M 알고리즘은:
- 지연 보정과 다중 선택을 동시에 처리할 수 있는 구조를 제공하고,
- regret bound가 기존 단일 선택 알고리즘과 거의 동일하게 유지되며,
- 실제 로봇 시스템, 무인 차량, 분산 센서 네트워크 등 다중 행동을 동시에 수행해야 하는 다양한 응용 분야에 바로 적용 가능하다.
향후 연구에서는 비동기적 지연(asynchronous delays), 부분 관찰(partial feedback), 그리고 연속적인 행동 공간(continuous action spaces) 등 보다 복잡한 환경으로 확장하는 방향을 모색할 계획이다. 이러한 확장은 DEXP3.M이 실제 산업 현장에서 더욱 폭넓게 활용될 수 있는 기반을 마련할 것이며, 적대적 환경에서도 신뢰할 수 있는 실시간 의사결정을 가능하게 할 것이다.