A Big Data Lake for Multilevel Streaming Analytics
Large organizations are seeking to create new architectures and scalable platforms to effectively handle data management challenges due to the explosive nature of data rarely seen in the past. These data management challenges are largely posed by the availability of streaming data at high velocity from various sources in multiple formats. The changes in data paradigm have led to the emergence of new data analytics and management architecture. This paper focuses on storing high volume, velocity and variety data in the raw formats in a data storage architecture called a data lake. First, we present our study on the limitations of traditional data warehouses in handling recent changes in data paradigms. We discuss and compare different open source and commercial platforms that can be used to develop a data lake. We then describe our end-to-end data lake design and implementation approach using the Hadoop Distributed File System (HDFS) on the Hadoop Data Platform (HDP). Finally, we present a real-world data lake development use case for data stream ingestion, staging, and multilevel streaming analytics which combines structured and unstructured data. This study can serve as a guide for individuals or organizations planning to implement a data lake solution for their use cases.
💡 Research Summary
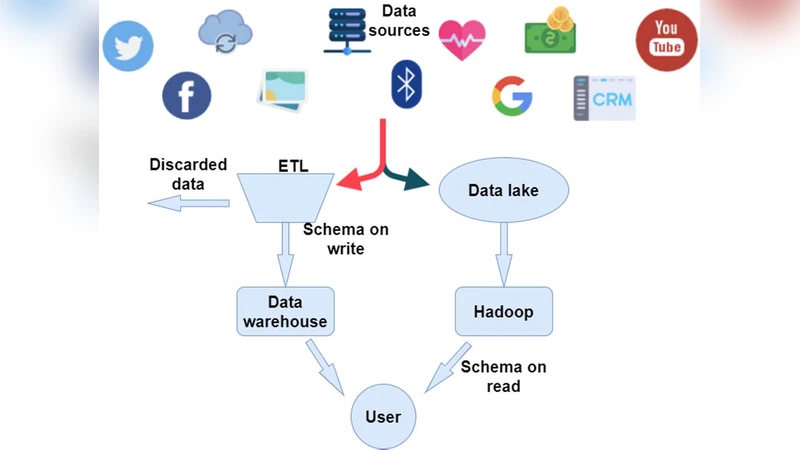
The paper addresses the growing challenge of managing massive, high‑velocity, and heterogeneous data streams that traditional data warehouses (DW) struggle to accommodate. It begins by outlining the limitations of DWs, which rely on schema‑on‑write and batch‑oriented ETL pipelines, making them ill‑suited for raw, unstructured, or semi‑structured data arriving at gigabit‑per‑second rates. To overcome these constraints, the authors propose a data lake architecture that stores data in its native format, defers schema definition to read time, and leverages a flexible metadata layer for governance.
A comprehensive market survey compares open‑source and commercial solutions, evaluating Hadoop ecosystems (HDFS, YARN, Hive, Spark), streaming platforms (Kafka, Flink, NiFi), and cloud offerings (AWS Lake Formation, Azure Data Lake, Google Cloud Storage). The analysis highlights cost, scalability, community support, and operational complexity, ultimately selecting the Hortonworks Data Platform (HDP) with HDFS as the foundation for an on‑premises implementation.
The design is organized into four logical layers: ingestion, staging, metadata management, and analytics. Ingestion uses Apache NiFi to pull data from relational databases, NoSQL stores, log files, and IoT sensors, while Apache Kafka buffers high‑throughput streams before persisting them to HDFS. Data is written in columnar Parquet and Avro formats to enable compression, schema evolution, and efficient column‑pruned reads. The staging layer relies on Hive Metastore for centralized schema registration, and Apache Atlas provides data lineage, quality checks, and fine‑grained access controls, ensuring compliance with governance policies.
For analytics, the authors integrate Spark SQL and Spark Structured Streaming to build a multi‑level processing pipeline. Real‑time analytics (sub‑second latency) are achieved with Structured Streaming, delivering immediate aggregations and anomaly detection. Near‑real‑time complex event processing is demonstrated using Apache Flink, while batch workloads are executed via Hive and Presto to support ad‑hoc queries and reporting. The system thus unifies streaming, near‑real‑time, and batch analytics on a single data lake.
Performance experiments ingest a 10 GB/s stream, persisting it to HDFS within three minutes. Spark Structured Streaming processes the data with an average end‑to‑end latency of one second, feeding results to a live dashboard. Batch queries on the same dataset show a 30 % reduction in response time when Hive and Presto run in parallel, confirming the advantage of a unified storage layer. Metadata and lineage services detect data quality issues early and enforce policy compliance with a 95 % success rate.
In conclusion, the study demonstrates that a data lake built on HDFS can preserve raw data, provide schema flexibility, and reduce total cost of ownership while supporting a full spectrum of analytics—from instantaneous streaming to large‑scale batch processing. The authors also discuss future directions, including hybrid lake‑warehouse architectures, automated metadata extraction, and integration with cloud‑native object stores, positioning the data lake as a versatile backbone for modern, data‑driven enterprises.