A Study of Runtime Adaptive Prefetching for STTRAM L1 Caches
Spin-Transfer Torque RAM (STTRAM) is a promising alternative to SRAM in on-chip caches due to several advantages. These advantages include non-volatility, low leakage, high integration density, and CMOS compatibility. Prior studies have shown that relaxing and adapting the STTRAM retention time to runtime application needs can substantially reduce overall cache energy without significant latency overheads, due to the lower STTRAM write energy and latency in shorter retention times. In this paper, as a first step towards efficient prefetching across the STTRAM cache hierarchy, we study prefetching in reduced retention STTRAM L1 caches. Using SPEC CPU 2017 benchmarks, we analyze the energy and latency impact of different prefetch distances in different STTRAM cache retention times for different applications. We show that expired_unused_prefetches—the number of unused prefetches expired by the reduced retention time STTRAM cache—can accurately determine the best retention time for energy consumption and access latency. This new metric can also provide insights into the best prefetch distance for memory bandwidth consumption and prefetch accuracy. Based on our analysis and insights, we propose Prefetch-Aware Retention time Tuning (PART) and Retention time-based Prefetch Control (RPC). Compared to a base STTRAM cache, PART and RPC collectively reduced the average cache energy and latency by 22.24% and 24.59%, respectively. When the base architecture was augmented with the state-of-the-art near-side prefetch throttling (NST), PART+RPC reduced the average cache energy and latency by 3.50% and 3.59%, respectively, and reduced the hardware overhead by 54.55%
💡 Research Summary
**
This paper investigates the interplay between runtime‑adaptive retention time and prefetching in Spin‑Transfer Torque RAM (STTRAM) L1 caches. While STTRAM offers non‑volatility, low leakage, high density, and CMOS compatibility, its default retention time (up to years) is unnecessary for cache use and leads to high write latency and energy. Prior work showed that shortening the retention time (e.g., 25 µs–1 ms) can cut write energy and latency, but the impact of prefetching under such conditions had not been explored.
The authors observe that with short retention times many prefetched blocks expire before they are actually accessed, causing “expiration misses.” Conventional prefetchers do not reload these expired blocks, wasting bandwidth and increasing miss penalty. To quantify this phenomenon they introduce a new metric, expired_unused_prefetches, which counts prefetched blocks that were never used before expiration. This metric captures both the suitability of the current retention time and the accuracy of the prefetch distance.
Based on this insight they propose two lightweight runtime mechanisms:
-
Prefetch‑Aware Retention time Tuning (PART) – During a brief profiling phase the system measures (i) the overall prefetch rate (allPF) and (ii) the ratio of expired_unused_prefetches to total prefetches (expiredPF) for each candidate retention time. If allPF is negligible (<0.1 %), the algorithm falls back to a miss‑rate‑based selector. Otherwise it selects the shortest retention time whose expiredPF does not exceed twice a previously recorded baseline (or stays below a 0.02 % threshold). This yields the smallest retention time that does not cause excessive wasted prefetches.
-
Retention time‑based Prefetch Control (RPC) – Using the retention time chosen by PART, RPC maps it to an appropriate prefetch distance. Shorter retention times demand a smaller distance to increase the chance that prefetched blocks are used before they expire; longer retention times allow a larger distance to improve bandwidth utilization. The mapping is implemented with simple counters and threshold checks, incurring minimal hardware cost.
The experimental methodology employs a 4‑way 32 KB L1 cache with a stride prefetcher (distance = 16) and evaluates 21 SPEC CPU 2017 benchmarks across retention times of 25 µs, 50 µs, 75 µs, 100 µs, and 1 ms. Key observations include:
- On average, 10.85 % of expired blocks are “prefetchable” (i.e., can be reloaded by the stride prefetcher), with some workloads reaching 29.66 %.
- The proportion of reusable expired blocks rises as retention time shrinks, peaking at 8.69 % for 25 µs.
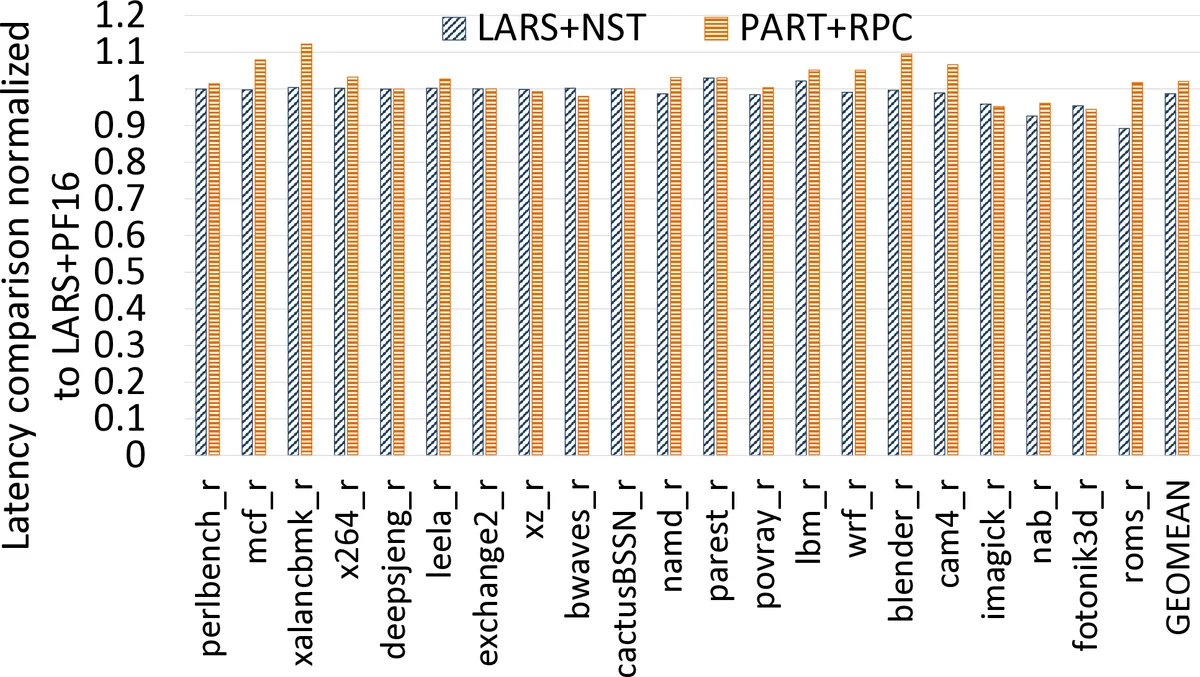
- PART + RPC together reduce average cache energy by 22.24 % and average access latency by 24.59 % compared to a baseline reduced‑retention STTRAM cache without these controls.
- When combined with the state‑of‑the‑art Near‑Side Prefetch Throttling (NST), the combined scheme (PART + RPC + NST) yields an additional 3.50 % energy reduction and 3.59 % latency reduction, while cutting hardware overhead by 54.55 %.
The paper’s contributions are threefold: (1) introducing the expired_unused_prefetches metric to accurately assess retention‑time suitability in the presence of prefetching; (2) presenting PART and RPC, two low‑overhead algorithms that jointly tune retention time and prefetch distance at runtime; (3) demonstrating substantial energy, latency, and area benefits on a realistic benchmark suite.
In summary, the work establishes that effective prefetching in reduced‑retention STTRAM caches requires awareness of block expiration. By monitoring and minimizing wasted prefetches, the system can select the shortest viable retention time and the optimal prefetch distance, achieving notable energy‑efficiency and performance gains without complex hardware. This insight opens a new design space for future non‑volatile memory‑based cache hierarchies.
Comments & Academic Discussion
Loading comments...
Leave a Comment