Breaking Symmetries of the Reservoir Equations in Echo State Networks
Reservoir computing has repeatedly been shown to be extremely successful in the prediction of nonlinear time-series. However, there is no complete understanding of the proper design of a reservoir yet. We find that the simplest popular setup has a harmful symmetry, which leads to the prediction of what we call mirror-attractor. We prove this analytically. Similar problems can arise in a general context, and we use them to explain the success or failure of some designs. The symmetry is a direct consequence of the hyperbolic tangent activation function. Further, four ways to break the symmetry are compared numerically: A bias in the output, a shift in the input, a quadratic term in the readout, and a mixture of even and odd activation functions. Firstly, we test their susceptibility to the mirror-attractor. Secondly, we evaluate their performance on the task of predicting Lorenz data with the mean shifted to zero. The short-time prediction is measured with the forecast horizon while the largest Lyapunov exponent and the correlation dimension are used to represent the climate. Finally, the same analysis is repeated on a combined dataset of the Lorenz attractor and the Halvorsen attractor, which we designed to reveal potential problems with symmetry. We find that all methods except the output bias are able to fully break the symmetry with input shift and quadratic readout performing the best overall.
💡 Research Summary
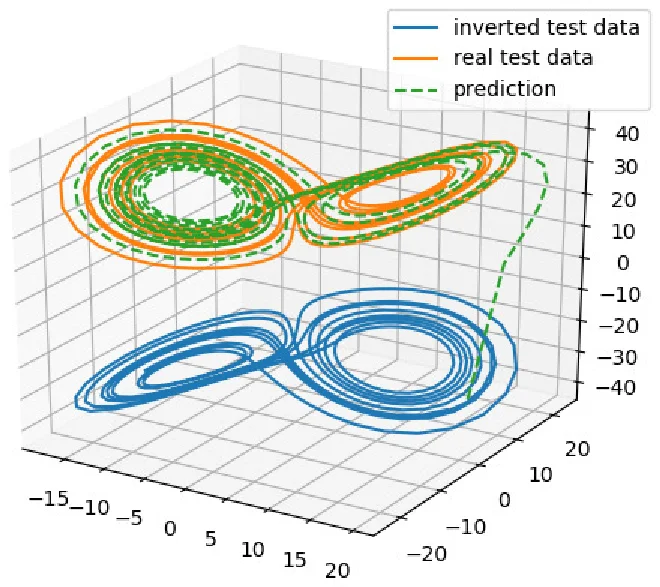
The paper investigates a fundamental symmetry problem in the most basic Echo State Network (ESN) architecture, which uses a hyperbolic tangent (tanh) activation function and a linear readout. The authors first demonstrate analytically that because tanh is an odd function (f(−z)=−f(z)), the reservoir dynamics inherit a global sign‑flip symmetry: if the input sequence xₜ is replaced by its negated version −xₜ, the reservoir state rₜ becomes simply −rₜ at every time step. Since the readout is linear, the output yₜ also flips sign, and the trained readout matrix W_out is identical for both the original and the inverted data. Consequently, the network learns not only the true attractor of the training data but also its “mirror‑attractor” (the state obtained by reflecting the original attractor across the origin in the dimensions where tanh is odd).
To illustrate the practical impact, the authors use two chaotic systems: the Lorenz system (σ=10, β=8/3, ρ=28) and the Halvorsen system (σ=1.3). The Lorenz equations possess a symmetry (x,y,z)→(−x,−y,z) and have a large mean offset in the z‑direction (≈23). When the ESN is trained on the original Lorenz data, it can predict short‑term trajectories but frequently jumps to the inverted attractor, especially when the data are shifted to zero mean. In a large Monte‑Carlo test (1000 random realizations, 500 000 prediction steps each), 98.5 % of runs that crossed z=0 switched to the mirror attractor, with an average first‑jump time of about 31 000 steps (≈539 Lyapunov times). The phenomenon is less severe when the two attractors are well separated, but it becomes catastrophic when they overlap after zero‑mean preprocessing, reducing the forecast horizon from ~400 steps (≈7 Lyapunov times) to ~90 steps (≈1.6 Lyapunov times).
The paper proposes four strategies to break the harmful symmetry:
-
Output bias – adding a constant term b to the readout (yₜ = W_out rₜ + b). This introduces asymmetry at the output layer but, in experiments, fails to fully suppress mirror‑attractor jumps.
-
Input shift – adding a constant vector c to the input (xₜ′ = xₜ + c). This perturbs the reservoir dynamics so that rₜ(−x) ≠ −rₜ(x), effectively destroying the sign‑flip invariance. The method yields a substantial increase in forecast horizon and reproduces the correct Lyapunov exponent and correlation dimension.
-
Quadratic readout – augmenting the readout with second‑order terms (φ(r) =
Comments & Academic Discussion
Loading comments...
Leave a Comment