A Survey of Resource Management for Processing-in-Memory and Near-Memory Processing Architectures
Due to amount of data involved in emerging deep learning and big data applications, operations related to data movement have quickly become the bottleneck. Data-centric computing (DCC), as enabled by processing-in-memory (PIM) and near-memory processing (NMP) paradigms, aims to accelerate these types of applications by moving the computation closer to the data. Over the past few years, researchers have proposed various memory architectures that enable DCC systems, such as logic layers in 3D stacked memories or charge sharing based bitwise operations in DRAM. However, application-specific memory access patterns, power and thermal concerns, memory technology limitations, and inconsistent performance gains complicate the offloading of computation in DCC systems. Therefore, designing intelligent resource management techniques for computation offloading is vital for leveraging the potential offered by this new paradigm. In this article, we survey the major trends in managing PIM and NMP-based DCC systems and provide a review of the landscape of resource management techniques employed by system designers for such systems. Additionally, we discuss the future challenges and opportunities in DCC management.
💡 Research Summary
The surveyed paper provides a comprehensive overview of resource‑management techniques for data‑centric computing (DCC) systems built on processing‑in‑memory (PIM) and near‑memory processing (NMP) architectures. It begins by motivating the need for DCC: modern deep‑learning and big‑data workloads generate massive data volumes, making data movement between CPU and memory the dominant performance and energy bottleneck. By moving computation closer to the data, PIM and NMP aim to alleviate this problem, but their adoption is complicated by heterogeneous memory technologies, thermal and power constraints, and irregular performance gains across applications.
The authors categorize existing memory‑centric architectures into three main families: (1) Logic‑in‑Memory (e.g., 3‑D‑stacked DRAM/HBM with a dedicated logic layer), (2) Charge‑Sharing Bitwise operations that exploit intrinsic DRAM cell physics for bulk bitwise functions, and (3) Near‑Memory Processors that sit on the memory side but retain a conventional processor core. Each family offers a distinct trade‑off between computational expressiveness, area overhead, and impact on memory reliability.
Given these diverse substrates, the paper argues that intelligent resource management is essential. It proposes a four‑dimensional taxonomy of management techniques:
-
Placement (Computation Offloading Decision) – Determines which kernels should execute on PIM/NMP versus the host CPU. Placement models incorporate data‑dependency graphs, memory‑bandwidth requirements, and the specific instruction set supported by the in‑memory logic (e.g., bitwise vs. integer arithmetic). Recent works formulate this as a mixed‑integer linear program that minimizes a weighted sum of latency, energy, and thermal cost.
-
Scheduling (Temporal Coordination) – Addresses contention for shared memory banks, internal interconnects, and the limited bandwidth of NMP accelerators. Bank‑level dynamic schedulers, priority‑based queues, and predictive pre‑scheduling are discussed. The authors highlight that naïve FIFO scheduling can cause severe bank conflicts, while more sophisticated schemes can improve throughput by 20‑40 % for memory‑bound kernels.
-
Data Mapping (Spatial Layout Optimization) – Reorganizes data structures to align with the physical organization of the memory substrate. Techniques include pre‑computing row‑column transposes so that subsequent operations access contiguous DRAM rows, bit‑slice mapping for bulk bitwise operations, and selective data replication to reduce cross‑bank traffic. The paper shows that optimal data mapping can reduce memory‑access latency by up to 30 % and improve energy efficiency by a similar margin.
-
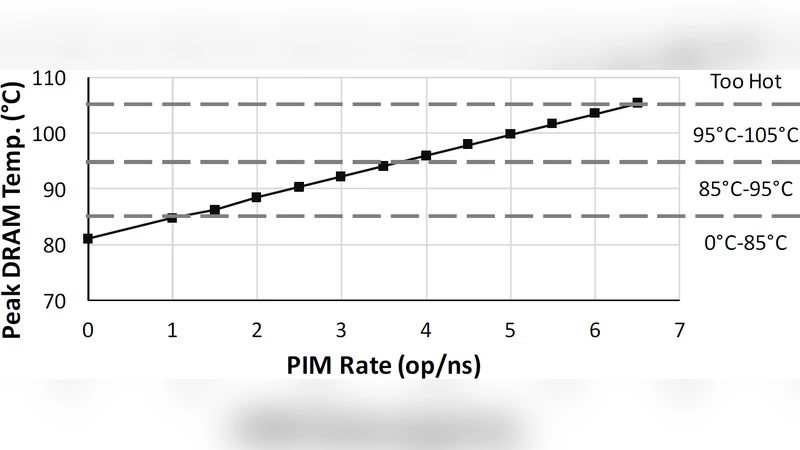
Thermal‑Power‑Reliability Management – Recognizes that in‑memory logic introduces additional heat, which can accelerate DRAM refresh cycles, increase error rates, and shorten cell lifetime. The survey covers dynamic voltage‑frequency scaling (DVFS) guided by on‑die temperature sensors, thermal‑aware task migration (moving hot kernels to cooler memory regions), and error‑correction strategies that combine ECC with selective retry. Experimental results from recent silicon prototypes demonstrate that such management can keep temperature rise below 10 °C while preserving a 30 % energy reduction.
A recurring theme is cross‑layer co‑design. Hardware architects must expose memory‑level characteristics (e.g., bank topology, thermal sensors) to the operating system and runtime, which in turn must provide APIs for placement, scheduling, and data‑mapping decisions. The authors evaluate several co‑design frameworks using cycle‑accurate simulators, silicon prototypes, and a suite of benchmarks (CNN inference, graph analytics, database joins). Across these workloads, the best‑case configurations achieve 1.8‑3.2× speedup and 30‑45 % energy savings compared with CPU‑only execution, while maintaining thermal limits.
The paper also contrasts policy‑driven (analytical optimization) and learning‑driven (reinforcement learning, neural‑network‑based schedulers) approaches. Policy‑driven methods provide predictable performance but struggle with highly dynamic workloads; learning‑driven methods adapt to runtime variations but incur training overhead and stability concerns. The authors suggest a hybrid framework that uses analytical policies as a baseline and refines them with lightweight online learning.
Future research directions identified include: (i) multi‑tenant resource isolation and fairness in shared PIM/NMP clouds, (ii) integration of non‑volatile memories (e.g., MRAM, ReRAM) to enable persistent in‑memory computation, (iii) standardization of programming models and compiler support (e.g., extensions to OpenMP, SYCL), and (iv) hardware‑assisted learning mechanisms to reduce the cost of adaptive schedulers.
In conclusion, the survey underscores that effective resource management—spanning placement, scheduling, data layout, and thermal‑reliability control—is the linchpin for realizing the promised performance and energy benefits of PIM and NMP architectures. By systematically addressing these challenges, the community can move DCC from research prototypes toward mainstream, production‑grade systems.