GrateTile: Efficient Sparse Tensor Tiling for CNN Processing
💡 Research Summary
The paper introduces GrateTile, a novel storage scheme designed to efficiently handle sparse feature maps in modern convolutional neural network (CNN) accelerators. The authors begin by highlighting that, as CNN architectures evolve, the proportion of power consumed by DRAM feature‑map reads has risen dramatically—accounting for more than half of the total power in recent networks—while the relative cost of MAC operations has declined. This shift makes memory bandwidth the dominant bottleneck, especially because accelerators increasingly rely on on‑chip SRAM to reduce accesses but still must fetch large volumes of feature data from DRAM.
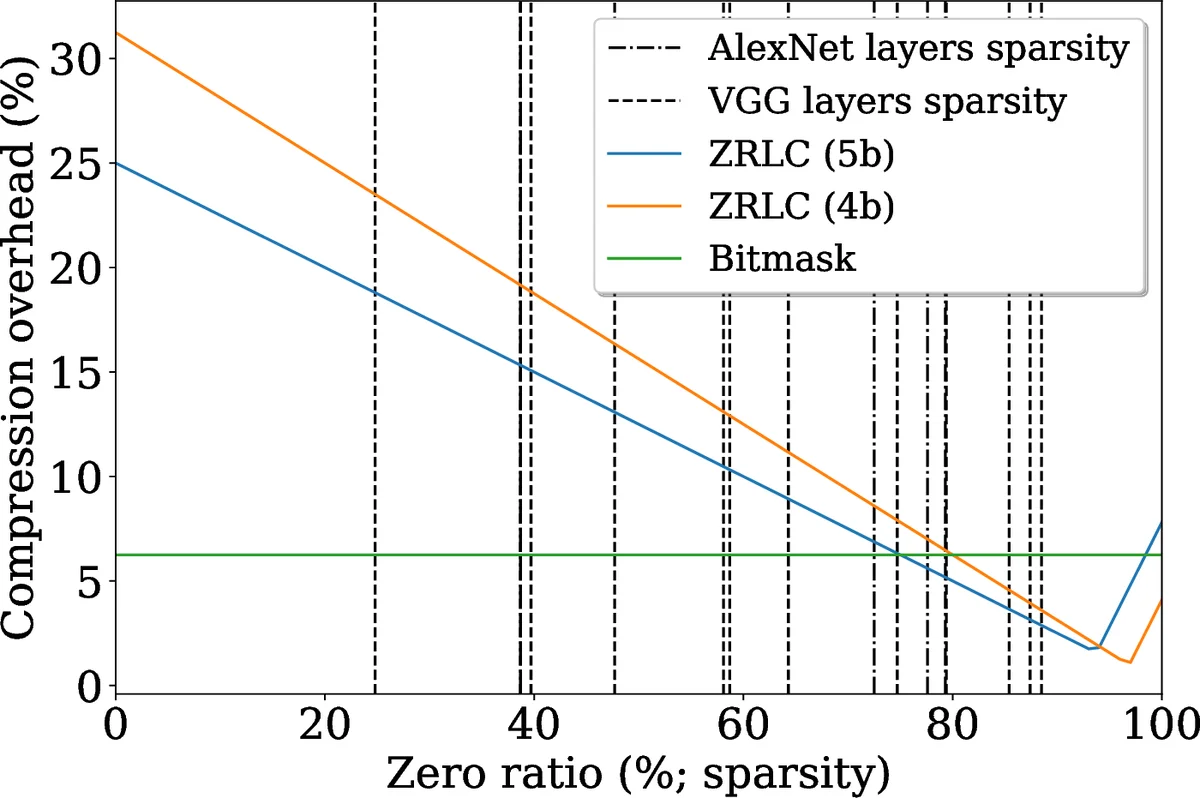
Existing compression techniques (e.g., bit‑mask, zero‑run‑length coding) can reduce the raw size of feature maps, yet they are typically applied to uniformly divided tensors. Uniform division creates a trade‑off: large subtensors waste bandwidth by over‑fetching data outside the required tile, whereas small subtensors cause severe fragmentation and large pointer/index overheads. The authors illustrate this dilemma with figures showing both extremes.
GrateTile resolves the dilemma by partitioning the feature map into uneven subtensors whose sizes are aligned with the access pattern of tiled CNN processing. The key insight is that the boundaries of the input windows required for each output tile form arithmetic progressions determined by kernel size (k), stride (s), dilation (d), and output tile dimensions (t_h × t_w). By taking the union of the left and right boundary sets modulo the tile stride (st_w), a small set of division points G is obtained. For example, with a 3×3 kernel, stride = 2, and an 8‑wide output tile, G = {1, 7} (mod 8) yields two spatial partitions of size 2 and 6, producing four possible subtensor shapes (6×6, 2×6, 6×2, 2×2). Any required input window can then be assembled from a minimal combination of these subtensors, guaranteeing that no partially compressed block is ever fetched.
The compression itself can use any existing algorithm (bit‑mask, ZRLC, etc.) applied independently to each subtensor. Because subtensors are stored at aligned addresses, the memory controller can issue burst reads without fragmentation. The only additional information needed is a compact metadata structure: a 28‑bit pointer to the start of each uniform 8×8×8 block plus a per‑subtensor size field (up to 20 bits for the most demanding kernel sizes). This results in 48 bits of metadata per 512 words of feature data—just 0.6 % overhead—well within DRAM capacity and negligible for on‑chip SRAM.
The authors evaluate GrateTile using SCALE‑sim on a 16×16 systolic array across a suite of popular networks (AlexNet, VGG‑16, ResNet‑18/50, VDSR, etc.). Compared with four uniform division baselines (8×8×8, 4×4×8, 2×2×8, 1×1×8), GrateTile consistently achieves the highest bandwidth savings, averaging a 55 % reduction in DRAM reads. Depending on the underlying compression ratio, additional gains of 6 %–27 % over the best uniform baseline are observed. The method is validated on two hardware platforms—a GPU‑style large tile configuration and an ASIC‑style small tile configuration (Eyeriss)—showing that the benefits are architecture‑agnostic.
From a hardware perspective, integrating GrateTile requires only modest modifications: the address generation unit must incorporate the modular division logic to compute the appropriate subtensor offsets, and a small metadata fetch unit is added to retrieve the size fields. No changes to the core compute array or the main data path are needed, making GrateTile a drop‑in enhancement for existing designs.
In summary, GrateTile offers a practical, low‑overhead approach to exploit dynamic sparsity in CNN feature maps. By aligning uneven subtensor boundaries with the tiled processing pattern, it eliminates both over‑fetch and fragmentation, achieves substantial DRAM bandwidth savings, and incurs minimal metadata overhead. This work paves the way for more power‑efficient CNN accelerators as memory bandwidth continues to lag behind compute capabilities.
Comments & Academic Discussion
Loading comments...
Leave a Comment