A Convolutional LSTM based Residual Network for Deepfake Video Detection
💡 Research Summary
The paper addresses the pressing need for a deepfake video detector that can generalize across multiple manipulation techniques and exploit temporal cues inherent in video data. The authors propose CLRNet, a Convolutional LSTM‑based Residual Network, which processes a short sequence of consecutive frames (five frames per sample) rather than isolated images. By employing ConvLSTM cells, the model retains spatial dimensions while learning temporal dependencies through convolutional gate operations, thereby capturing subtle inter‑frame inconsistencies such as sudden brightness shifts, contrast changes, or minor facial part deformations that are characteristic of deepfake videos but absent in pristine footage.
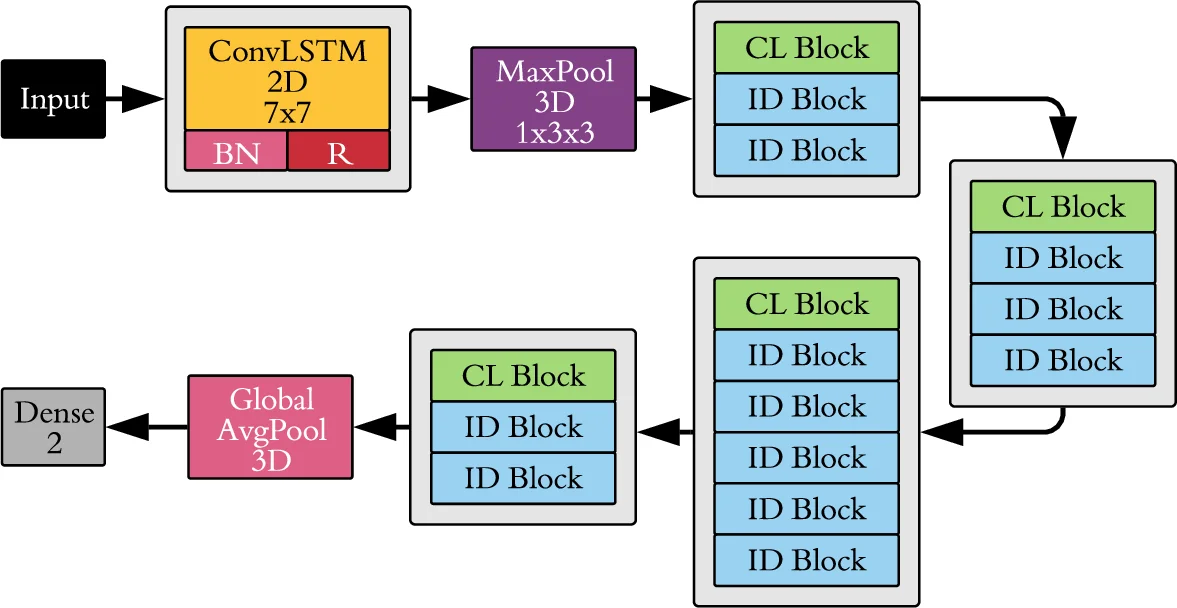
CLRNet’s architecture mirrors the residual design of ResNet but replaces standard convolutional layers with two custom blocks: the CL block (ConvLSTM → Dropout → BatchNorm → ReLU) and the ID block (identical to CL but with a direct shortcut connection). Each block produces two outputs; one passes through an addition operation, and the other undergoes batch normalization and ReLU before feeding the next block. This residual wiring mitigates vanishing gradients and enables deeper networks to be trained effectively on video sequences.
The experimental pipeline uses the FaceForensics++ suite (Pristine, DeepFake, FaceSwap, Face2Face, NeuralTextures) plus the DeepFakeDetection (DFD) dataset. For each video, 16 samples are extracted, each containing five consecutive frames. Faces are detected and aligned with MTCNN, cropped, and resized to 240 × 240 pixels. Data augmentation (brightness, channel shift, zoom, rotation, horizontal flip) expands the training distribution. The authors allocate 750 videos per class for training, 125 for validation, and 125 for testing; DFD uses a reduced subset due to its larger size.
A central contribution is the systematic evaluation of three few‑shot transfer learning strategies: (1) single‑source → single‑target, (2) multi‑source → single‑target, and (3) single‑source → multi‑target. In each case, the model is pre‑trained on a large source domain and then fine‑tuned on as few as ten real and ten fake videos from the target domain. This approach reflects realistic scenarios where newly emerging deepfake methods lack extensive labeled data.
Results demonstrate that CLRNet outperforms five recent state‑of‑the‑art detectors (including Xception, MesoNet, Two‑Stream, ForensicsTransfer, and others) on both in‑domain and cross‑domain tests. On average, CLRNet achieves a 3–5 percentage‑point gain in accuracy over baselines when evaluated on the same dataset. More importantly, its cross‑domain performance degrades far less than competing methods, confirming the efficacy of the temporal modeling and transfer learning scheme. Visualizations of frame‑difference maps illustrate that deepfake videos exhibit pronounced inter‑frame artifacts, which the ConvLSTM layers successfully learn to discriminate.
The paper also discusses limitations: ConvLSTM incurs higher computational and memory costs compared to standard CNNs, potentially hindering real‑time deployment; the fixed five‑frame window may not capture longer‑range temporal patterns; and the evaluation is confined to face‑centric, heavily compressed videos, leaving open questions about robustness to diverse content, varying compression levels, and background motion. Future work is suggested in three directions: (i) designing lightweight ConvLSTM variants or hybrid attention mechanisms to reduce overhead, (ii) supporting variable‑length sequences or hierarchical temporal modeling, and (iii) integrating multimodal cues (audio, textual metadata) for a more comprehensive deepfake detection framework.
In summary, the authors present a well‑motivated, technically sound architecture that leverages spatio‑temporal modeling and few‑shot transfer learning to achieve superior generalization across deepfake generation methods, marking a notable advance in video forensics.
Comments & Academic Discussion
Loading comments...
Leave a Comment