Revealing Secrets in SPARQL Session Level
📝 Abstract
Based on Semantic Web technologies, knowledge graphs help users to discover information of interest by using live SPARQL services. Answer-seekers often examine intermediate results iteratively and modify SPARQL queries repeatedly in a search session. In this context, understanding user behaviors is critical for effective intention prediction and query optimization. However, these behaviors have not yet been researched systematically at the SPARQL session level. This paper reveals secrets of session-level user search behaviors by conducting a comprehensive investigation over massive real-world SPARQL query logs. In particular, we thoroughly assess query changes made by users w.r.t. structural and data-driven features of SPARQL queries. To illustrate the potentiality of our findings, we employ an application example of how to use our findings, which might be valuable to devise efficient SPARQL caching, auto-completion, query suggestion, approximation, and relaxation techniques in the future.
💡 Analysis
Based on Semantic Web technologies, knowledge graphs help users to discover information of interest by using live SPARQL services. Answer-seekers often examine intermediate results iteratively and modify SPARQL queries repeatedly in a search session. In this context, understanding user behaviors is critical for effective intention prediction and query optimization. However, these behaviors have not yet been researched systematically at the SPARQL session level. This paper reveals secrets of session-level user search behaviors by conducting a comprehensive investigation over massive real-world SPARQL query logs. In particular, we thoroughly assess query changes made by users w.r.t. structural and data-driven features of SPARQL queries. To illustrate the potentiality of our findings, we employ an application example of how to use our findings, which might be valuable to devise efficient SPARQL caching, auto-completion, query suggestion, approximation, and relaxation techniques in the future.
📄 Content
시맨틱 웹(Semantic Web) 기술을 기반으로 하는 지식 그래프는 실시간 SPARQL 서비스와 결합되어 사용자가 관심 있는 정보를 손쉽게 발견하도록 돕는다. 이러한 환경에서 답을 찾고자 하는 이용자들은 하나의 검색 세션 안에서 중간 결과를 반복적으로 검토하고, 필요에 따라 SPARQL 쿼리를 여러 차례 수정·재작성한다. 즉, 사용자는 초기 질의에 대한 응답을 확인한 뒤, 얻어진 결과가 기대와 다르거나 추가적인 정보를 탐색하고자 할 때, 기존 질의를 구조적으로 바꾸거나 바인딩 값을 조정하는 식으로 탐색 과정을 진행한다. 이러한 탐색 과정은 단순히 한 번의 질의 실행으로 끝나는 것이 아니라, 사용자가 목표로 하는 정보를 정확히 얻을 때까지 여러 단계에 걸쳐 반복되는 ‘질의‑결과‑수정’ 루프를 형성한다.
이러한 맥락에서 사용자의 행동 양식을 정밀하게 이해하는 일은 두 가지 측면에서 매우 중요한 의미를 가진다. 첫째, 사용자가 현재 어떤 의도를 가지고 있는지를 예측함으로써, 시스템이 적절한 시점에 적합한 질의 보조 기능(예: 자동 완성, 질의 제안, 질의 완화 등)을 제공할 수 있다. 둘째, 사용자가 수행하는 일련의 질의 변형 패턴을 파악하면, 백엔드에서 쿼리 실행 계획을 사전에 최적화하거나, 자주 사용되는 질의 조각을 캐시해 두는 등 효율적인 자원 관리 전략을 수립할 수 있다.
그럼에도 불구하고, 지금까지 이러한 사용자 행동에 대한 연구는 주로 개별 질의 수준에서 이루어졌으며, 세션 전체에 걸친 연속적인 질의 변형과 그에 수반되는 구조적·데이터 기반 특성 변화를 체계적으로 분석한 사례는 거의 찾아볼 수 없다. 즉, “사용자는 한 세션 안에서 어떻게 질의를 바꾸는가?”라는 근본적인 질문에 대한 답은 아직 학계와 산업계 모두에게 미해결 과제로 남아 있다.
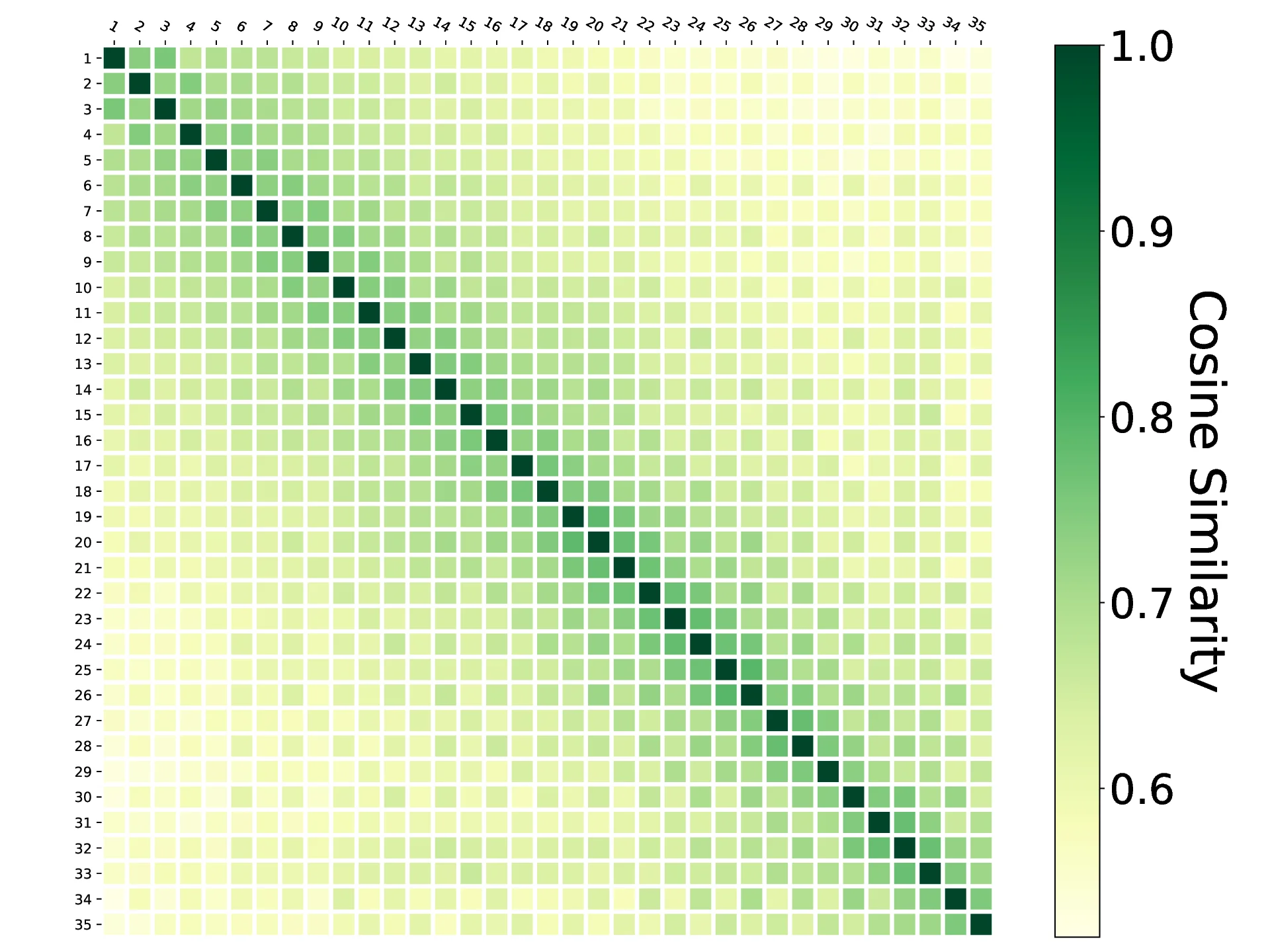
본 논문은 이러한 연구 공백을 메우고자, 실제 운영 환경에서 수집된 방대한 규모의 SPARQL 질의 로그를 대상으로 포괄적인 실증 조사를 수행하였다. 로그 데이터는 수백만 건에 이르는 질의 기록을 포함하고 있으며, 각 질의는 타임스탬프, 사용자 식별자, 질의 문자열, 반환된 바인딩 결과 등 다양한 메타데이터와 함께 저장되어 있다. 우리는 먼저 로그를 사용자‑세션 단위로 재구성하여, 동일 사용자가 일정 시간 내에 수행한 연속적인 질의들을 하나의 세션으로 묶었다. 이후 각 세션 내에서 연속되는 두 질의 사이의 차이를 정량화하기 위해, 구조적 차원과 데이터‑드리븐 차원 두 가지 축을 설정하였다.
구조적 차원에서는 질의 트리의 깊이, 트리 노드의 종류(예: SELECT, ASK, CONSTRUCT, DESCRIBE), 트리패턴의 복잡도, 사용된 프리픽스와 네임스페이스, 그리고 필터 표현식의 유무와 복잡성 등을 측정하였다. 예를 들어, 사용자가 처음에 단순히 특정 클래스의 인스턴스를 조회하는 질의를 작성했다가, 이후에 그 인스턴스와 연결된 다른 관계를 탐색하기 위해 트리패턴에 새로운 삼중항을 추가하거나, OPTIONAL 절을 삽입하는 경우가 구조적 변형에 해당한다.
데이터‑드리븐 차원에서는 실제 질의 실행 결과에 기반한 변화를 분석하였다. 구체적으로는 반환된 바인딩 수, 바인딩된 변수의 종류와 개수, 결과 집합의 평균 크기, 그리고 질의 실행 시간 등을 고려하였다. 사용자가 초기 질의에서 얻은 결과가 너무 많아 과부하가 발생하거나, 반대로 너무 적어 의미 있는 정보를 얻지 못했을 때, 결과 집합을 제한하기 위해 LIMIT 절을 추가하거나, 특정 리터럴 값으로 FILTER를 강화하는 행동이 데이터‑드리븐 변형에 해당한다.
이러한 두 축을 종합적으로 평가함으로써, 우리는 사용자가 세션 내에서 수행하는 질의 변형이 주로 구조적 확장(새로운 패턴을 추가하거나 기존 패턴을 복잡하게 만드는 경우)와 데이터‑중심 축소(결과 집합을 제한하거나 필터를 강화하는 경우) 사이에서 교대로 나타난다는 사실을 발견하였다. 특히, 초기 질의가 매우 포괄적일수록 사용자는 이후 단계에서 보다 구체적인 필터링이나 제한을 가하는 경향이 강했으며, 반대로 초기 질의가 지나치게 제한적일 경우에는 추가적인 패턴을 삽입하거나 OPTIONAL 절을 활용해 정보를 보강하려는 행동이 두드러졌다.
우리의 연구 결과가 실제 시스템 설계에 어떻게 활용될 수 있는지를 보여주기 위해, 응용 사례를 하나 제시한다. 예를 들어, SPARQL 캐싱 메커니즘을 설계할 때, 사용자가 세션 초기에 수행한 질의와 그 이후에 발생하는 구조적 확장·데이터‑드리븐 축소 패턴을 사전에 예측하면, 캐시된 결과를 부분적으로 재사용하거나, 변형된 질의에 대해 빠르게 근사 결과를 제공할 수 있다. 또한, 자동 완성 기능에서는 사용자가 현재 입력 중인 질문의 구조적 위치(예: SELECT 절 내부, WHERE 절의 삼중항 추가 단계 등)를 실시간으로 파악하여, 가장 가능성이 높은 프리픽스·프로퍼티·리터럴을 제안함으로써 입력 부담을 크게 줄일 수 있다. 질의 제안 시스템은 세션 내에서 이전에 사용된 패턴과 유사한 패턴을 학습하여, 사용자가 아직 명시하지 않은 잠재적인 탐색 경로를 미리 제시할 수 있다. 마지막으로, 질의 근사화·완화 기법은 사용자가 반환된 결과가 너무 적거나 너무 많을 때, 자동으로 LIMIT을 조정하거나 OPTIONAL 절을 삽입·제거하는 방식으로 동작하도록 설계될 수 있다.
요약하면, 본 논문은 방대한 실세계 SPARQL 로그를 기반으로 세션 수준에서 나타나는 사용자 검색 행동의 숨겨진 규칙을 체계적으로 밝혀냈으며, 구조적·데이터‑드리븐 두 축을 동시에 고려한 정량적 분석을 통해 향후 효율적인 SPARQL 서비스 구현에 필요한 인사이트를 제공한다. 이러한 인사이트는 캐싱, 자동 완성, 질의 제안, 근사화 및 완화와 같은 다양한 응용 분야에서 실질적인 성능 향상과 사용자 경험 개선을 이끌어낼 수 있을 것으로 기대한다.