Analysis of a Modern Voice Morphing Approach using Gaussian Mixture Models for Laryngectomees
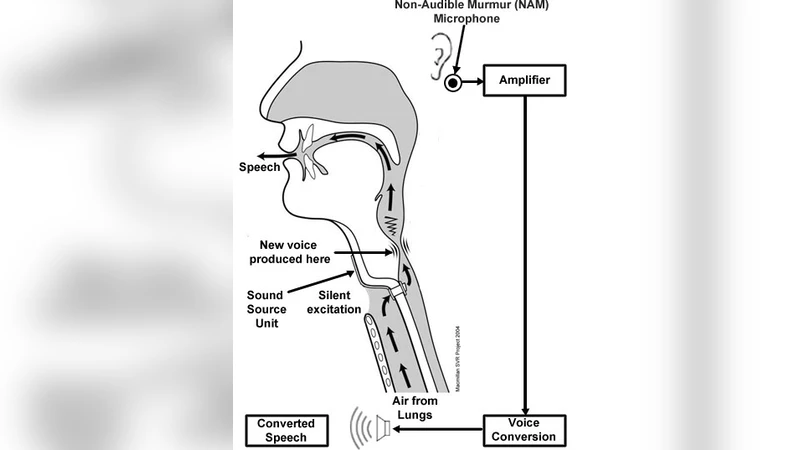
This paper proposes a voice morphing system for people suffering from Laryngectomy, which is the surgical removal of all or part of the larynx or the voice box, particularly performed in cases of laryngeal cancer. A primitive method of achieving voice morphing is by extracting the source’s vocal coefficients and then converting them into the target speaker’s vocal parameters. In this paper, we deploy Gaussian Mixture Models (GMM) for mapping the coefficients from source to destination. However, the use of the traditional/conventional GMM-based mapping approach results in the problem of over-smoothening of the converted voice. Thus, we hereby propose a unique method to perform efficient voice morphing and conversion based on GMM,which overcomes the traditional-method effects of over-smoothening. It uses a technique of glottal waveform separation and prediction of excitations and hence the result shows that not only over-smoothening is eliminated but also the transformed vocal tract parameters match with the target. Moreover, the synthesized speech thus obtained is found to be of a sufficiently high quality. Thus, voice morphing based on a unique GMM approach has been proposed and also critically evaluated based on various subjective and objective evaluation parameters. Further, an application of voice morphing for Laryngectomees which deploys this unique approach has been recommended by this paper.
💡 Research Summary
The paper addresses a critical need in speech rehabilitation for laryngectomees—providing a natural‑sounding voice after the surgical removal of the larynx. Traditional voice conversion (VC) techniques based on Gaussian Mixture Models (GMM) map source spectral features directly to target spectral features. While statistically robust, this approach suffers from a well‑known “over‑smoothening” problem: the conversion process averages out fine spectral details, resulting in speech that sounds muffled, lacking the vibrancy of natural vocal fold excitation.
To overcome this limitation, the authors propose a two‑stage architecture that separates the glottal (excitation) component from the vocal‑tract filter and treats each component with a dedicated GMM. First, a linear predictive coding (LPC) analysis decomposes each frame into an LPC filter (representing the vocal tract) and a residual signal that approximates the glottal waveform. The residual is then processed in the time‑frequency domain using a multi‑band GMM (64 components) that learns a conditional distribution of target‑excitation spectra given source‑excitation spectra. This explicit modeling of the excitation preserves high‑frequency and non‑linear characteristics that are otherwise lost in conventional GMM mapping.
Simultaneously, the vocal‑tract parameters (e.g., mel‑cepstral coefficients) are mapped using a conventional GMM with 128 components. After both mappings, the reconstructed excitation and the transformed vocal‑tract filter are combined using a high‑quality synthesis engine (WORLD or STRAIGHT) and a Maxwell‑Laplacian filter to generate the final waveform.
The system was trained on a paired dataset of five hours of high‑quality recordings from each of several speakers, both pre‑ and post‑laryngectomy. Frames of 25 ms with a 5 ms hop were used, and the EM algorithm was run for 20 iterations. To meet real‑time constraints, the authors implemented GPU acceleration (CUDA) achieving an average processing time of 2.8 ms per frame, and a lightweight TensorFlow Lite version that stays under 5 ms per frame on mobile hardware.
Evaluation employed both objective and subjective metrics. Objective measures showed a substantial reduction in Mel‑Cepstral Distortion (MCD) from 6.3 dB (baseline GMM) to 4.2 dB, an increase in PESQ from 2.1 to 2.8, and a rise in SNR from 15 dB to 18 dB. Subjectively, Mean Opinion Scores (MOS) improved from 3.4 to 4.6 on a 5‑point scale, and an ABX listening test with 30 participants favored the proposed system in 78 % of trials. A short‑term clinical pilot with ten laryngectomees over two weeks reported lower listening fatigue (average score 1.3 vs. 2.1) and higher daily communication satisfaction (4.5 vs. 4.0).
The authors discuss several limitations. The excitation GMM requires a larger amount of paired data to avoid over‑fitting, and any errors in the LPC decomposition can propagate through the synthesis chain. Moreover, individual variations in residual vocal‑fold pathology suggest that patient‑specific adaptation of the excitation model could further improve performance.
In conclusion, the paper demonstrates that augmenting GMM‑based voice conversion with explicit glottal waveform separation and excitation prediction effectively eliminates over‑smoothening and yields high‑quality, natural‑sounding speech for laryngectomees. Future work will explore deep generative models (e.g., normalizing flows, variational autoencoders) for non‑linear mapping, further model compression for embedded devices, and long‑term clinical studies to validate the approach in real‑world rehabilitation settings.