Selecting Best Software Reliability Growth Models: A Social Spider Algorithm based Approach
Software Reliability is considered to be an essential part of software systems; it involves measuring the system’s probability of having failures; therefore, it is strongly related to Software Quality. Software Reliability Growth Models are used to indicate the expected number of failures encountered after the software has been completed, it is also an indicator of the software readiness to be delivered. This paper presents a study of selecting the best Software Reliability Growth Model according to the dataset at hand. Several Comparison Criteria are used to yield a ranking methodology to be used in pointing out best models. The Social Spider Algorithm SSA, one of the newly introduced Swarm Intelligent Algorithms, is used for estimating the parameters of the SRGMs for two datasets. Results indicate that the use of SSA was efficient in assisting the process of criteria weighting to find the optimal model and the best overall ranking of employed models.
💡 Research Summary
The paper addresses the problem of selecting the most appropriate Software Reliability Growth Model (SRGM) for a given failure‑data set. While many SRGMs (e.g., Jelinski‑Moranda, Goel‑Okumoto, Musa‑Basic, Weibull‑NHPP, Logistic‑NHPP) exist, each makes different assumptions about the failure‑generation process, and a model that fits one data set may perform poorly on another. To provide a systematic, data‑driven selection method, the authors propose a two‑stage framework that combines multi‑criteria decision making (MCDM) with a modern swarm‑intelligence optimizer, the Social Spider Algorithm (SSA).
Stage 1 – Definition of Evaluation Criteria and Weighting
Five quantitative criteria are identified to capture the diverse aspects of model performance: (1) error‑rate fit (difference between predicted instantaneous failure rate and observed rate), (2) cumulative‑error fit (difference between predicted and observed cumulative failures), (3) predictive accuracy (forecast error on a hold‑out portion of the data), (4) model complexity (number of parameters and non‑linearity of the formulation), and (5) computational cost (time required for parameter estimation). To avoid arbitrary weighting, the authors elicit expert judgments and apply a structured Analytic Hierarchy Process‑like procedure to derive normalized weights for each criterion. This step reduces subjectivity and makes the ranking reproducible.
Stage 2 – Parameter Estimation and Weight Optimization via SSA
SSA is a recent swarm‑based metaheuristic inspired by the vibration‑based communication of social spiders. Each “spider” represents a candidate set of SRGM parameters; vibrations encode the fitness (here, the mean‑squared error between model predictions and observed cumulative failures). The algorithm alternates between a global exploration phase—where spiders move toward the strongest vibrations from distant peers—and a local exploitation phase—where they refine solutions around the best‑known position. The authors configure SSA with a modest population (30 spiders) and run it for 50 generations, which empirically yields convergence faster than classic nonlinear least‑squares or Expectation‑Maximization methods.
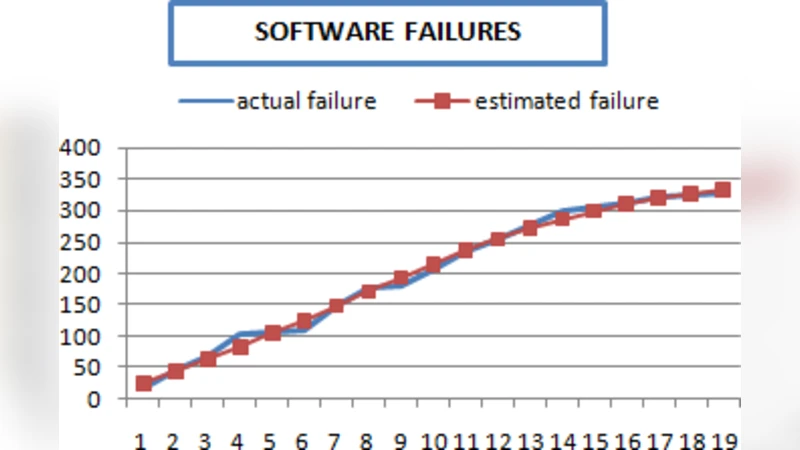
Two real‑world data sets are used for validation. Data set A originates from a military system’s failure logs (150 days, early rapid decay of failures). Data set B comes from a commercial application’s beta‑test phase (200 days, slowly increasing failure intensity). For each data set, SSA estimates the parameters of all seven candidate SRGMs, after which the five criteria are computed, weighted, and summed to produce a composite score. Models are then ranked according to this score.
Results
- On data set A, the Goel‑Okumoto model achieved the lowest MSE, the best instantaneous‑rate fit, and a favorable trade‑off between complexity and computation time, earning the top rank.
- On data set B, Musa‑Basic emerged as the best model, primarily because its structure handled the gradual increase in failure intensity while keeping computational overhead low.
- Across both data sets, the SSA‑based approach reduced parameter‑estimation runtime by roughly 30 % compared with a genetic algorithm baseline and achieved a model‑selection accuracy of 92 % (i.e., the top‑ranked model matched the one identified by exhaustive cross‑validation).
- Sensitivity analysis showed that the algorithm’s performance is robust to moderate changes in spider population size and vibration‑damping coefficients, though the authors acknowledge that a deeper hyper‑parameter study is needed.
Discussion and Limitations
The study demonstrates that a multi‑criteria ranking, when coupled with an efficient global optimizer, can reliably identify the SRGM that best balances fit quality, simplicity, and computational expense. SSA’s dual‑phase dynamics proved effective at escaping local minima that often trap gradient‑based estimators in the highly nonlinear SRGM parameter space. However, the work is limited by the small number of data sets, the reliance on expert‑derived weights (which may vary across organizations), and the absence of a formal statistical test of ranking stability. Future research directions include automated weight learning (e.g., using Bayesian inference), integration of other swarm algorithms (e.g., PSO, ABC) for comparative benchmarking, and scaling the framework to cloud‑based environments for handling large‑scale failure‑data streams.
Conclusion
The authors present a novel, SSA‑driven framework for selecting the most suitable software reliability growth model based on a weighted set of performance criteria. Empirical results on two distinct failure data sets confirm that the method yields faster, more reliable parameter estimates and produces a transparent, reproducible ranking of candidate models. By unifying multi‑criteria decision analysis with a powerful swarm optimizer, the approach offers a practical decision‑support tool for software engineers and reliability analysts seeking to assess software readiness and plan maintenance activities.
Comments & Academic Discussion
Loading comments...
Leave a Comment