Machine Learning on sWeighted Data
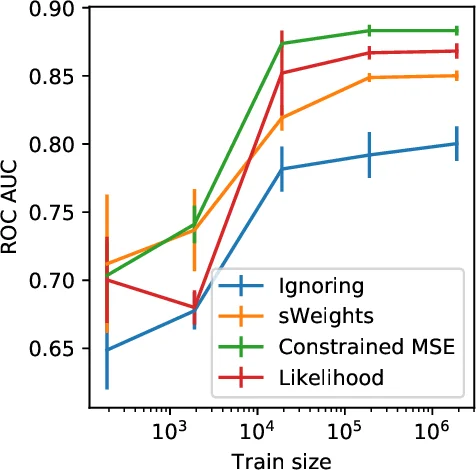
Data analysis in high energy physics has to deal with data samples produced from different sources. One of the most widely used ways to unfold their contributions is the sPlot technique. It uses the results of a maximum likelihood fit to assign weights to events. Some weights produced by sPlot are by design negative. Negative weights make it difficult to apply machine learning methods. The loss function becomes unbounded. This leads to divergent neural network training. In this paper we propose a mathematically rigorous way to transform the weights obtained by sPlot into class probabilities conditioned on observables, thus enabling to apply any machine learning algorithm out-of-the-box.
💡 Research Summary
The paper addresses a practical obstacle in applying modern machine learning techniques to high‑energy‑physics (HEP) data that have been processed with the sPlot method. sPlot assigns an event‑by‑event weight w_i derived from a maximum‑likelihood fit to discriminative variables (typically an invariant mass). By construction these sWeights can be negative, which is harmless for simple histogramming but creates a severe problem for loss functions that assume non‑negative sample weights. In particular, the standard cross‑entropy loss L₁ = Σ_i
Comments & Academic Discussion
Loading comments...
Leave a Comment