An In-Depth Analysis of the Slingshot Interconnect
The interconnect is one of the most critical components in large scale computing systems, and its impact on the performance of applications is going to increase with the system size. In this paper, we will describe Slingshot, an interconnection network for large scale computing systems. Slingshot is based on high-radix switches, which allow building exascale and hyperscale datacenters networks with at most three switch-to-switch hops. Moreover, Slingshot provides efficient adaptive routing and congestion control algorithms, and highly tunable traffic classes. Slingshot uses an optimized Ethernet protocol, which allows it to be interoperable with standard Ethernet devices while providing high performance to HPC applications. We analyze the extent to which Slingshot provides these features, evaluating it on microbenchmarks and on several applications from the datacenter and AI worlds, as well as on HPC applications. We find that applications running on Slingshot are less affected by congestion compared to previous generation networks.
💡 Research Summary
The paper presents an in‑depth evaluation of Slingshot, a next‑generation interconnect designed for exascale supercomputers, hyperscale data centers, and AI workloads. At its core is the ROSetta ASIC, a 64‑port switch delivering 200 Gb/s per direction (effectively 50 Gb/s per lane after forward error correction) built on a 16 nm TSMC process and consuming up to 250 W per chip. The switch is organized into 32 tiles, each handling two ports, with a hierarchical row‑bus and column‑crossbar architecture that limits packet traversal to a maximum of two internal hops (row then column). This design yields a measured switch latency of roughly 350 ns for RoCE traffic, with a tight distribution between 300 and 400 ns.
Slingshot adopts a Dragonfly topology. Each ROSetta switch connects to 16 compute nodes via short copper cables, while the remaining 48 ports are used for inter‑switch links. Within a group, switches are fully connected; groups are linked together with long optical fibers, resulting in a network diameter of three switch‑to‑switch hops. The authors demonstrate that node placement influences latency by at most 40 % for 8‑byte messages, and that for messages larger than 16 KB the latency difference across one‑hop, two‑hop, and three‑hop paths drops below 10 %. Bandwidth measurements show near‑line‑rate performance (≈ 97 Gb/s) for large messages, with only modest variation across different hop distances.
A key contribution is Slingshot’s adaptive routing. Before forwarding a packet, the source switch evaluates up to four candidate paths (both minimal and non‑minimal) and selects the one with the best combination of congestion and path length. Congestion is estimated from the depth of request queues at each output port; this information is disseminated across the chip via a ring and between neighboring switches via a four‑byte field in acknowledgment packets. While non‑minimal routes increase average hop count, the routing algorithm biases toward minimal paths to keep latency and link utilization low.
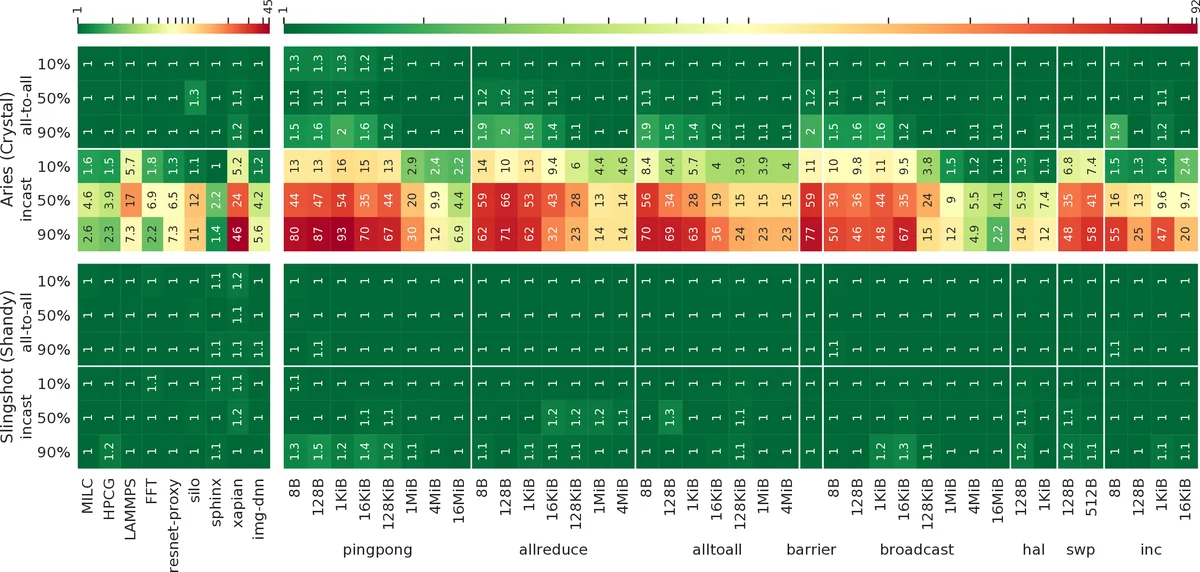
The congestion control subsystem distinguishes endpoint congestion (typically at the last hop) from intermediate congestion. Adaptive routing mitigates intermediate congestion, but endpoint congestion affects all paths. Slingshot combines request‑to‑transmit / grant‑to‑transmit flow control with end‑to‑end acknowledgments to adjust a congestion window, thereby limiting the impact of many‑to‑one traffic patterns that have historically caused severe performance degradation on other networks. In experiments using standard 100 Gb/s RoCE v2 NICs, Slingshot exhibited markedly lower tail latency and higher throughput than Cray’s previous Aries interconnect, despite not exploiting the full set of proprietary Ethernet extensions.
Interoperability with Ethernet is achieved by retaining standard MAC, PCS, and link‑layer reliability functions while adding a Slingshot‑specific protocol for switch‑to‑switch communication. This allows the network to connect to existing data‑center equipment without modification, yet still deliver HPC‑grade latency and low packet overhead. The authors note that their measurements do not fully leverage the specialized Ethernet features (e.g., link‑level reliability and congestion signaling) that would be available with a native Slingshot NIC.
Power considerations are briefly discussed: each 64‑port switch draws up to 250 W, which scales to several megawatts for a full exascale installation. While the paper demonstrates impressive performance, it does not provide a detailed analysis of total system power efficiency or cooling requirements, leaving these as open questions for future work.
In summary, Slingshot integrates high‑radix switching, a low‑diameter Dragonfly topology, adaptive routing, and congestion control into an Ethernet‑compatible fabric. The experimental results show that it delivers low latency (≈ 350 ns switch latency), high bandwidth (≈ 97 Gb/s), and robustness to network noise, outperforming the prior Aries architecture. The work positions Slingshot as a strong candidate for upcoming exascale and hyperscale deployments, while highlighting areas such as full Ethernet feature exploitation, power‑efficiency optimization, and large‑scale reliability testing that merit further investigation.
Comments & Academic Discussion
Loading comments...
Leave a Comment