Adaptive Hierarchical Hyper-gradient Descent
In this study, we investigate learning rate adaption at different levels based on the hyper-gradient descent framework and propose a method that adaptively learns the optimizer parameters by combining multiple levels of learning rates with hierarchical structures. Meanwhile, we show the relationship between regularizing over-parameterized learning rates and building combinations of adaptive learning rates at different levels. The experiments on several network architectures, including feed-forward networks, LeNet-5 and ResNet-18/34, show that the proposed multi-level adaptive approach can outperform baseline adaptive methods in a variety of circumstances.
💡 Research Summary
The paper tackles the problem of learning‑rate adaptation in deep neural network training by extending the hyper‑gradient descent (HD) framework beyond its usual scalar, global setting. The authors propose a hierarchical approach that learns separate learning‑rate parameters at four levels: global, layer‑wise, unit‑wise, and parameter‑wise. Each level’s learning rates are treated as distinct trainable variables (vectors or matrices) and are updated online via hyper‑gradients obtained through back‑propagation through the optimizer’s update rule.
To mitigate the explosion of hyper‑parameters that results from assigning a learning rate to every parameter, the authors introduce a suite of regularization terms. A layer‑wise regularizer penalizes the squared deviation of each layer’s learning rate from the global average, encouraging coherence across layers. A parameter‑wise regularizer further pulls individual parameter learning rates toward their parent layer’s rate and, optionally, toward the global rate. An additional temporal regularizer smooths learning‑rate changes across successive iterations. These regularizers are weighted by coefficients (λ_layer, λ_para_layer, λ_para, λ_ts) that can be tuned manually or via meta‑optimization.
The paper derives explicit gradient expressions for the full loss (model loss plus regularizers) with respect to each learning‑rate variable. Because the regularizers introduce dependence on the current step’s learning rates, the authors define “virtual” learning rates (̂α) that are computed without regularization, and then combine them with the regularization terms to obtain the actual updated rates (α*). This results in a simple weighted‑average update: α* = (1‑2βλ)·̂α + 2βλ·̂α_global, where β is the hyper‑learning‑rate for the learning‑rate parameters. The derivation shows that, under modest choices of β and λ (ensuring 0 < 2βλ < 1), the approximation is accurate and the update remains computationally cheap.
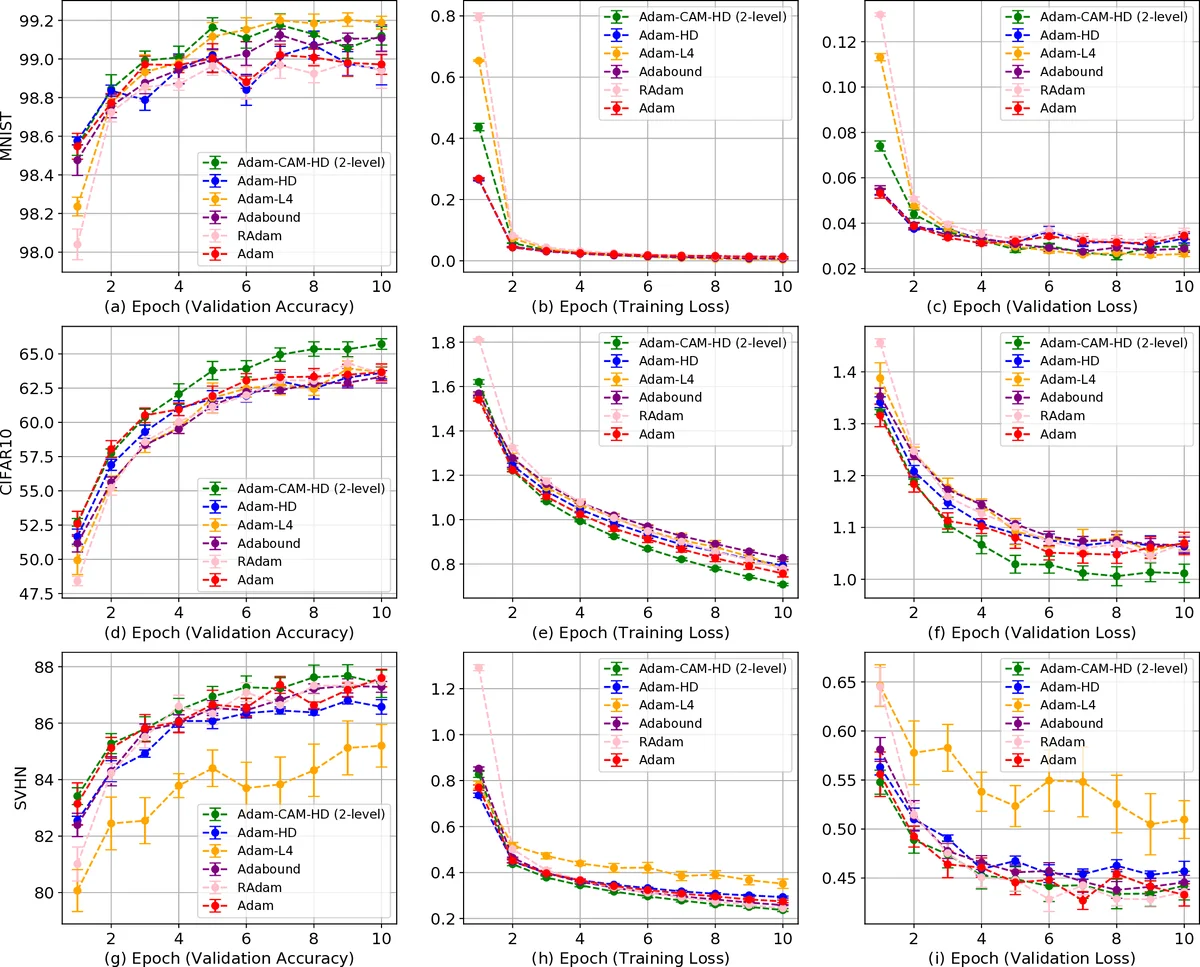
Experimental evaluation covers several architectures: a basic feed‑forward network, LeNet‑5 on MNIST, and ResNet‑18/34 on CIFAR‑10/100. Across all settings, the hierarchical adaptive optimizer outperforms standard adaptive methods such as Adam, RMSProp, and L4. Notably, in deep ResNets the method reduces over‑fitting, achieves faster early‑stage convergence, and yields 1–1.5 % higher top‑1 accuracy. Ablation studies demonstrate that the regularization coefficients effectively control the trade‑off between global stability and local flexibility: larger λ_layer forces layer rates to align closely with the global rate, while smaller values allow more per‑layer specialization.
The authors acknowledge limitations: the approach introduces additional hyper‑parameters (β, λ coefficients) that require tuning, and the hierarchical update equations are more complex than those of conventional optimizers. They suggest future work on meta‑learning these coefficients, exploring more efficient approximations, and scaling the method to very large models and datasets.
In summary, the paper presents a novel hierarchical hyper‑gradient descent algorithm that simultaneously learns multiple levels of adaptive learning rates while regularizing them to avoid over‑parameterization. The method demonstrates consistent gains in convergence speed and final performance across a range of network depths, offering a promising direction for more fine‑grained, data‑driven optimizer design.
Comments & Academic Discussion
Loading comments...
Leave a Comment