aschern at SemEval-2020 Task 11: It Takes Three to Tango: RoBERTa, CRF, and Transfer Learning
💡 Research Summary
The paper presents a comprehensive system for SemEval‑2020 Task 11, which focuses on detecting propaganda techniques in news articles. The task is split into two subtasks: Span Identification (SI), which requires locating the textual spans that contain propaganda, and Technique Classification (TC), which assigns one or more propaganda technique labels to each identified span. The authors build their solutions around the RoBERTa‑large pre‑trained language model, augmenting it with a linear‑chain Conditional Random Field (CRF) for the SI subtask, and with additional span‑level features and transfer learning for the TC subtask. They also devise extensive rule‑based post‑processing steps and combine multiple models through ensembling.
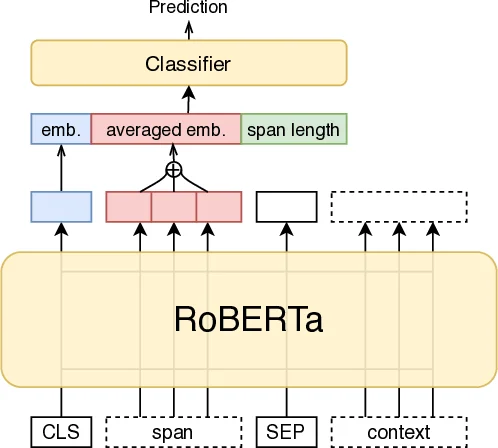
For SI, the authors first convert the gold span annotations into a BIO tagging scheme (B‑PROP, I‑PROP, O). A RoBERTa‑large model is fine‑tuned to predict these tags token‑wise. Since RoBERTa treats each token independently, the authors add a CRF layer on top of the RoBERTa logits to model label transitions, ensuring that illegal sequences such as O → I‑PROP are penalized. Because RoBERTa uses byte‑pair encoding, only tokens that start a word are fed to the CRF, effectively ignoring sub‑word continuation tokens (e.g., “##ed”). After decoding the CRF output into spans, two post‑processing operations are applied: (1) spans are trimmed or extended so that both boundaries are alphanumeric characters, correcting tokenization errors; (2) surrounding quotation marks are added when present, as propaganda often appears inside quotes. To improve robustness, two identical architectures are trained with different random seeds; at inference time their predictions are merged, overlapping spans being unified into a superspan. This ensemble reduces variance across runs.
For TC, the problem is multi‑label but the training data contain very few multi‑label instances. The authors therefore transform each multi‑label example into multiple single‑label copies, training a standard multi‑class classifier. The input format is “
Comments & Academic Discussion
Loading comments...
Leave a Comment