Application of Seq2Seq Models on Code Correction
We apply various seq2seq models on programming language correction tasks on Juliet Test Suite for C/C++ and Java of Software Assurance Reference Datasets(SARD), and achieve 75%(for C/C++) and 56%(for Java) repair rates on these tasks. We introduce Pyramid Encoder in these seq2seq models, which largely increases the computational efficiency and memory efficiency, while remain similar repair rate to their non-pyramid counterparts. We successfully carry out error type classification task on ITC benchmark examples (with only 685 code instances) using transfer learning with models pre-trained on Juliet Test Suite, pointing out a novel way of processing small programing language datasets.
💡 Research Summary
The paper investigates the application of sequence‑to‑sequence (seq2seq) neural architectures to the problem of programming language correction (PLC), a task traditionally dominated by rule‑based static analysis tools. Leveraging the large, synthetically generated Juliet Test Suite from the Software Assurance Reference Datasets (SARD), the authors train and evaluate both recurrent (multi‑layer bidirectional GRU) and Transformer‑based seq2seq models on C/C++ and Java code snippets that contain logical or resource‑management bugs rather than simple syntax errors.
A central contribution is the introduction of a “Pyramid Encoder” that sits between successive encoder layers. At each level the encoder halves the sequence length by merging adjacent hidden states through a linear projection followed by a tanh activation. This design mimics a convolution‑like down‑sampling without explicit filters, dramatically reducing the number of tokens processed in higher layers. The authors argue that code instances are typically much longer than natural‑language sentences (hundreds of tokens versus a few dozen), so such compression is essential for feasible training on commodity GPUs.
Data preprocessing includes dead‑code removal, elimination of unrealistic branch‑flip examples, and systematic renaming of function identifiers to curb vocabulary size to roughly 1,000 tokens. After these steps, the C/C++ corpus contains 31,082 “bad‑good” pairs and the Java corpus 23,015 pairs, split 80/10/10 for training, validation, and testing.
The models are evaluated using a “repair rate” metric: the proportion of test instances for which the model’s output matches a known correct version. Two variants are reported: 1‑candidate repair rate (beam width = 1, representing fully automated correction) and 5‑candidate repair rate (beam width = 5, representing a suggestion list for a human). For C/C++, the best GRU‑based model with Bahdanau attention achieves 75.76 % repair with a single candidate and 94.19 % with five candidates. The Transformer model reaches 74.26 % and 95.60 % respectively. For Java, repair rates are lower (≈55 % for a single candidate, ≈84 % for five candidates), reflecting the increased difficulty of the language and the smaller dataset.
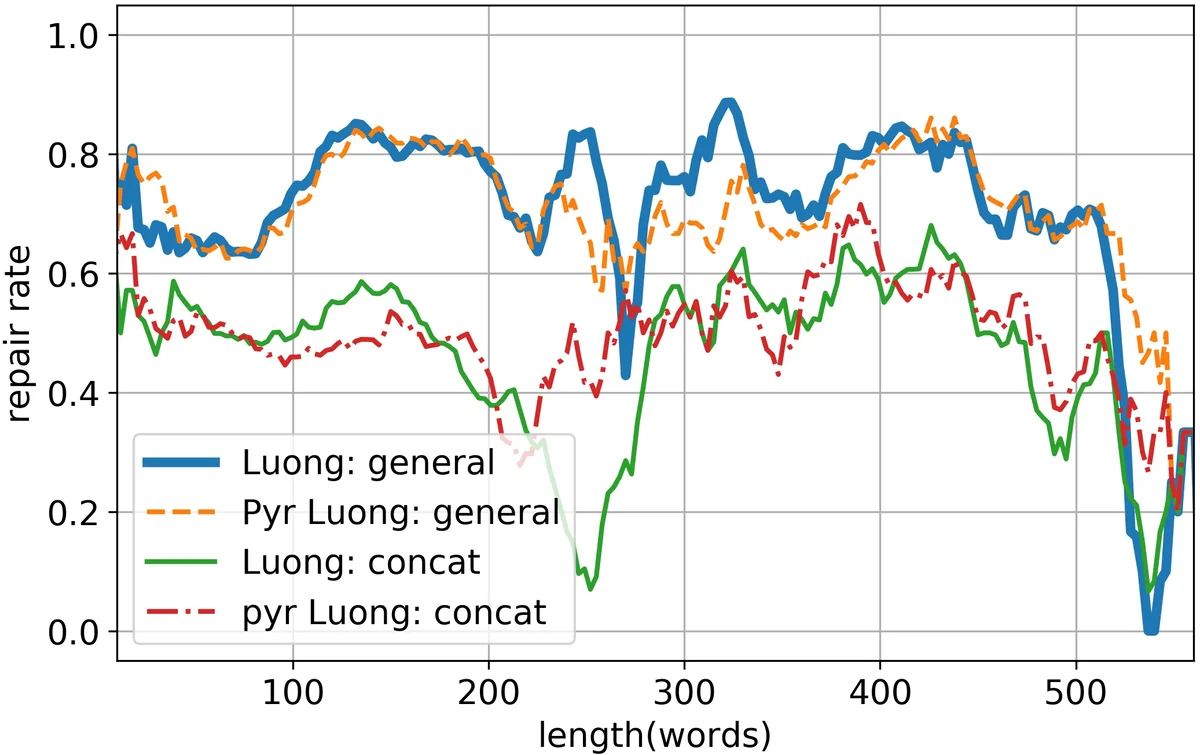
When the Pyramid Encoder is applied, most configurations retain comparable repair rates, sometimes even improving the 5‑candidate metric by up to 1.8 %. The only notable exception is Luong’s local attention, which suffers a substantial drop because the down‑sampled encoder outputs provide a blurry attention focus. Training speed benefits are substantial: the Pyramid Encoder reduces per‑batch processing time by 50 %–130 % and cuts memory consumption by up to 600 %, while requiring a similar number of epochs to converge.
A transfer‑learning experiment further demonstrates the utility of large synthetic corpora. Models pre‑trained on Juliet are fine‑tuned on the much smaller ITC benchmark (685 code snippets) for error‑type classification. The fine‑tuned models outperform those trained from scratch, indicating that knowledge learned from massive automatically generated code can be transferred to realistic, limited‑size datasets.
In summary, the paper makes three key contributions: (1) it shows that seq2seq models can achieve high repair rates (≥70 % with a single candidate, ≥90 % with five candidates) on realistic code‑correction tasks; (2) it proposes the Pyramid Encoder, which dramatically improves computational and memory efficiency without sacrificing accuracy for most attention mechanisms; and (3) it validates a transfer‑learning pipeline that leverages large synthetic code bases to boost performance on small, real‑world datasets. The work opens avenues for future research, such as integrating the Pyramid Encoder with newer long‑sequence Transformers (e.g., Longformer, Performer), extending experiments to additional programming languages, and deploying the approach in real‑time IDE assistance tools.
Comments & Academic Discussion
Loading comments...
Leave a Comment