75,000,000,000 Streaming Inserts/Second Using Hierarchical Hypersparse GraphBLAS Matrices
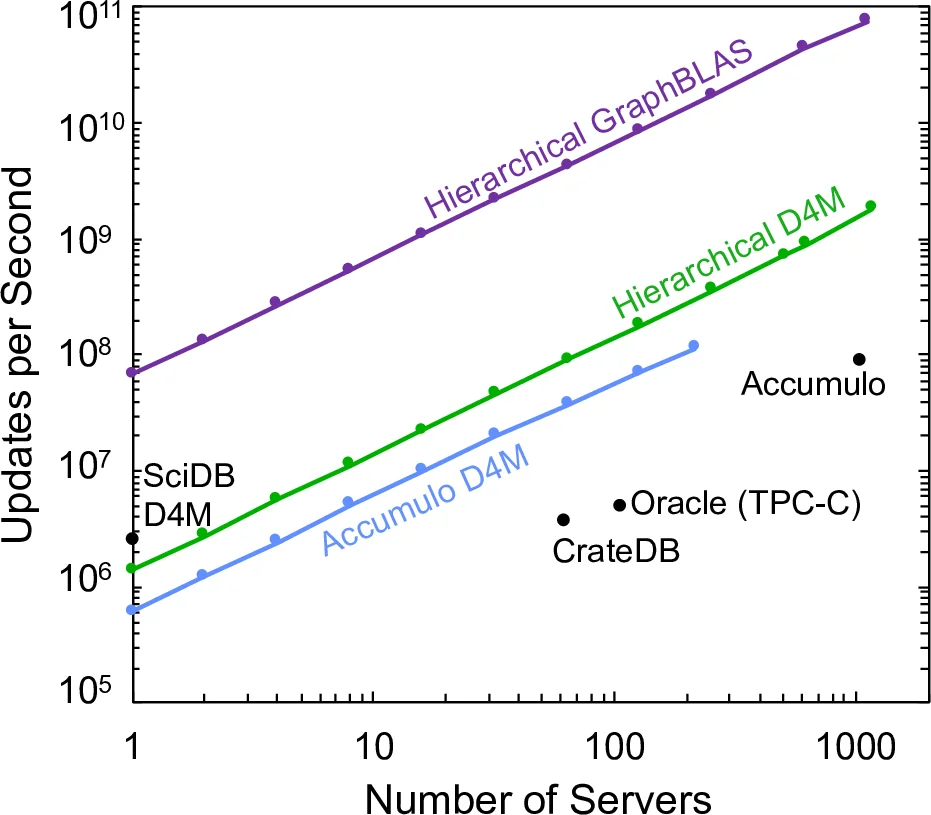
The SuiteSparse GraphBLAS C-library implements high performance hypersparse matrices with bindings to a variety of languages (Python, Julia, and Matlab/Octave). GraphBLAS provides a lightweight in-memory database implementation of hypersparse matrices that are ideal for analyzing many types of network data, while providing rigorous mathematical guarantees, such as linearity. Streaming updates of hypersparse matrices put enormous pressure on the memory hierarchy. This work benchmarks an implementation of hierarchical hypersparse matrices that reduces memory pressure and dramatically increases the update rate into a hypersparse matrices. The parameters of hierarchical hypersparse matrices rely on controlling the number of entries in each level in the hierarchy before an update is cascaded. The parameters are easily tunable to achieve optimal performance for a variety of applications. Hierarchical hypersparse matrices achieve over 1,000,000 updates per second in a single instance. Scaling to 31,000 instances of hierarchical hypersparse matrices arrays on 1,100 server nodes on the MIT SuperCloud achieved a sustained update rate of 75,000,000,000 updates per second. This capability allows the MIT SuperCloud to analyze extremely large streaming network data sets.
💡 Research Summary
This paper presents a groundbreaking high-performance computing technique for real-time processing and analysis of massive streaming network data, achieving an unprecedented update rate of 75 billion inserts per second. The core innovation is the implementation of “Hierarchical Hypersparse Matrices” within the SuiteSparse GraphBLAS C-library.
The research addresses the critical challenge of analyzing exponentially growing internet traffic, projected to exceed 100 terabytes per second. Tools like origin-destination traffic matrices are essential for network monitoring and security but require representing an immense, mostly empty address space (e.g., 2^64 x 2^64 for IPv6) using hypersparse matrices. Streaming updates to such matrices create severe bottlenecks in the memory hierarchy, as frequent writes to slower main memory cripple performance.
The proposed solution ingeniously optimizes for the memory hierarchy by creating a multi-level cascade of hypersparse matrices. The fastest memory (e.g., CPU cache) holds the first-level matrix (A1), where all streaming updates are initially applied. Once the number of non-zero entries in A1 exceeds a tunable threshold (c1), the entire A1 matrix is added to the second-level matrix (A2) residing in slower memory, and A1 is cleared. This process repeats recursively through the hierarchy (A2 to A3, etc.). This design ensures that the vast majority of update operations occur in the fastest memory, while costly writes to slower memory are batched into large, infrequent merges. The mathematical foundation of GraphBLAS allows this hierarchical merging to be implemented simply and efficiently using standard sparse matrix addition operations. When a complete analysis is required, all matrices in the hierarchy are summed to produce the final result.
The performance results are staggering. A single instance of the hierarchical hypersparse matrix achieved over 1,000,000 updates per second. When scaled across the MIT SuperCloud—utilizing 31,000 instances on 1,100 server nodes—the system sustained a peak update rate of 75,000,000,000 (75 billion) updates per second. This performance significantly surpasses previously published results for other technologies, including D4M associative arrays on databases like Accumulo and SciDB, the Oracle TPC-C benchmark, and CrateDB.
This capability fundamentally enables the real-time analysis of extremely large-scale streaming network datasets, such as global internet traffic for botnet detection or dynamic social network analysis. Furthermore, the integration of this high-performance C-library with high-productivity programming environments like Python, Julia, and Matlab/Octave makes this powerful tool accessible to scientists and engineers without requiring expertise in low-level systems programming. The work demonstrates a successful fusion of rigorous mathematical principles, hierarchical systems optimization, and large-scale distributed computing to solve a pressing big data challenge.
Comments & Academic Discussion
Loading comments...
Leave a Comment