Evaluating Semantic Interaction on Word Embeddings via Simulation
💡 Research Summary
**
The paper investigates whether deep‑learning word embeddings can improve Semantic Interaction (SI) for visual text analytics compared with traditional bag‑of‑words (BoW) features. SI is an interaction technique that lets analysts manipulate a 2‑D projection of documents (by dragging and dropping) while the system automatically updates underlying machine‑learning models (typically metric learning) to reflect the analyst’s implicit intent. Existing SI systems such as ForceSPIRE and Cosmos rely on TF‑IDF keyword vectors, which capture only surface‑level term frequencies and may miss higher‑level semantic relationships.
The authors propose an SI variant that uses pre‑trained GloVe embeddings (300‑dimensional) averaged across all words in a document, calling this “SI‑embedding”. They also retain the classic BoW‑based SI, referred to as “SI‑keyword”. Both variants are implemented in a single prototype built on the Andromeda visual analytics platform, allowing a seamless switch between feature types. The prototype updates feature weights based on user interactions: for BoW, shared terms in dragged documents are up‑weighted; for embeddings, dimensions showing similar patterns across dragged documents are amplified.
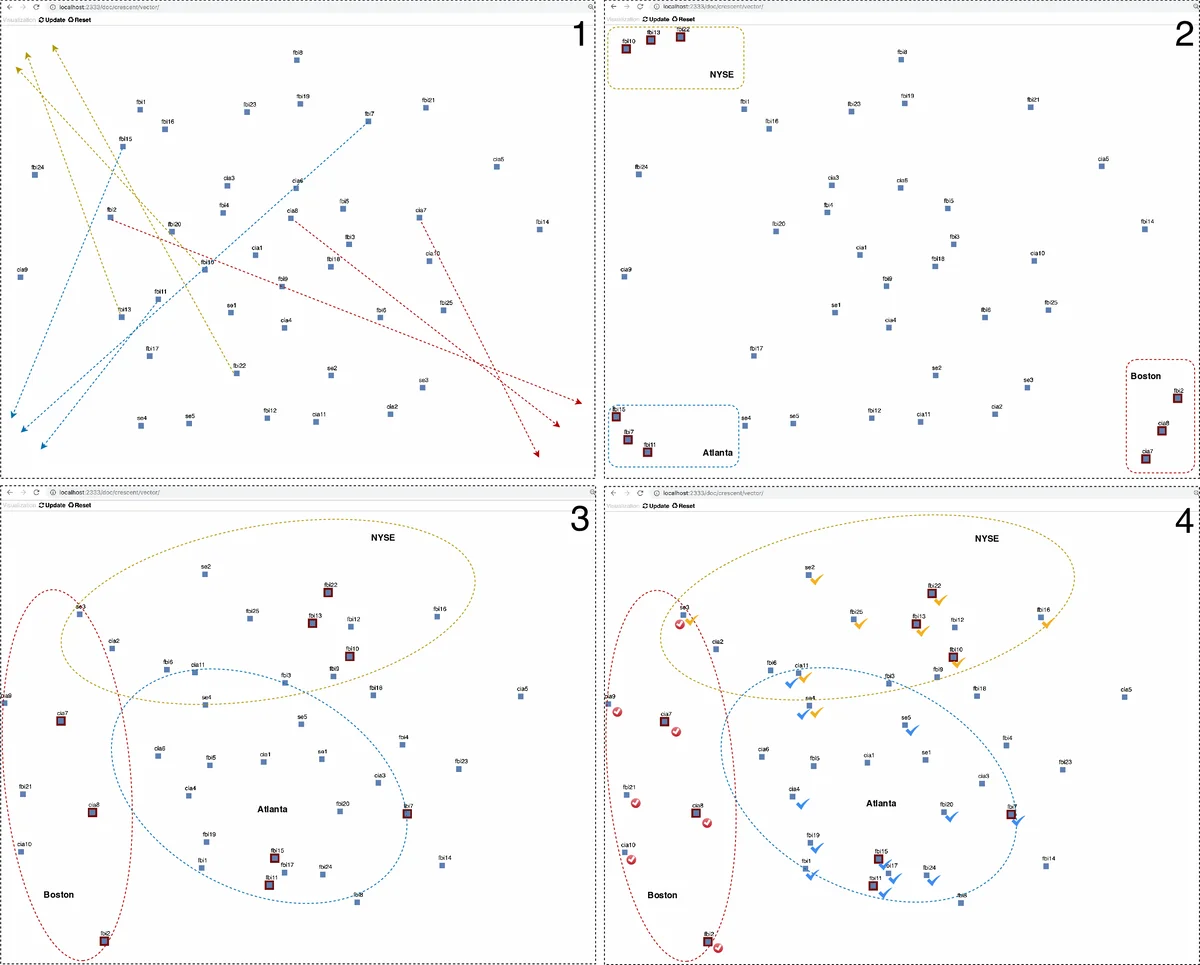
Two complementary evaluation strategies are employed. The first is a human‑centered qualitative study. An intelligence‑analysis expert works with a synthetic “Crescent” dataset containing 42 fictional reports about terrorist plots in Boston, New York, and Atlanta (24 of them relevant). Using SI‑embedding, the analyst can clearly separate the three threat clusters, and documents that discuss multiple plots (e.g., “se3”) naturally fall between the corresponding clusters, reflecting their mixed semantics. With SI‑keyword, the resulting layout is muddled: clusters overlap, and the system appears to over‑fit on a few noisy keywords, making it difficult to discern the three plots. The expert’s feedback confirms that the embedding‑based layout is more meaningful and better respects the underlying semantics.
The second evaluation is algorithm‑centric and fully quantitative. Because there is no ground truth for user intent, the authors simulate interactions using labeled text corpora. They select the 20 Newsgroups dataset and the VISpubdata collection of IEEE VIS conference abstracts. Four binary classification tasks are defined: (1) “rec.autos” vs. “rec.motorcycles” (T_rec), (2) “comp.sys.mac.hardware” vs. “comp.sys.ibm.pc.hardware” (T_sys), (3) “talk.religion.misc” vs. “soc.religion.christian” (T_religion), and (4) IEEE InfoVis vs. VAST abstracts (T_vis). For each task, a 2‑D projection is created, and simulated interactions consist of moving five documents from each class to opposite corners of the space. After each interaction loop, the SI model updates its feature weights; the updated model is then evaluated with a 3‑nearest‑neighbour classifier using cross‑validation. Accuracy is recorded after every loop and also as the final average.
Results show a consistent advantage for SI‑embedding. In T_rec, the final average accuracy reaches 0.921 (±0.03) for SI‑embedding versus 0.497 (±0.05) for SI‑keyword. Similar gaps appear in the other three tasks (e.g., T_religion: 0.829 vs. 0.576; T_sys: 0.895 vs. 0.511; T_vis: 0.958 vs. 0.961, the latter being an outlier where both perform well). Overall, SI‑embedding achieves higher mean accuracies across all interaction loops, indicating that embeddings provide a richer, more stable representation that better captures incremental user feedback.
The paper’s contributions are threefold: (1) introducing a word‑embedding‑based SI pipeline that can be swapped with a BoW pipeline within the same visual analytics system; (2) proposing a reproducible simulation framework that leverages labeled datasets to quantitatively assess SI models, addressing the scalability and objectivity limitations of purely human‑centered studies; (3) empirically demonstrating that embedding‑based SI outperforms BoW‑based SI both qualitatively (clearer visual clusters) and quantitatively (higher classification accuracy) across multiple tasks.
Future work suggested includes exploring contextual embeddings such as BERT or RoBERTa for SI, integrating document‑level structural information (e.g., citation graphs), and validating the simulation approach against real user interaction logs to quantify any gap between simulated and authentic behavior. The authors argue that combining human‑centered and algorithm‑centered evaluations provides a more comprehensive picture of SI model performance, and that word embeddings represent a promising direction for making semantic interaction more attuned to analysts’ cognitive reasoning.
Comments & Academic Discussion
Loading comments...
Leave a Comment