A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization
In this paper, we propose a deep learning approach to tackle the automatic summarization tasks by incorporating topic information into the convolutional sequence-to-sequence (ConvS2S) model and using self-critical sequence training (SCST) for optimization. Through jointly attending to topics and word-level alignment, our approach can improve coherence, diversity, and informativeness of generated summaries via a biased probability generation mechanism. On the other hand, reinforcement training, like SCST, directly optimizes the proposed model with respect to the non-differentiable metric ROUGE, which also avoids the exposure bias during inference. We carry out the experimental evaluation with state-of-the-art methods over the Gigaword, DUC-2004, and LCSTS datasets. The empirical results demonstrate the superiority of our proposed method in the abstractive summarization.
💡 Research Summary
The paper introduces a novel approach to abstractive text summarization that integrates topic information into a convolutional sequence‑to‑sequence (ConvS2S) architecture and optimizes the model with self‑critical sequence training (SCST), a reinforcement learning technique. The authors argue that while ConvS2S offers parallel training efficiency and mitigates gradient vanishing compared to recurrent networks, it relies solely on word‑level attention, which can lead to incoherent or less informative summaries. To address this, they propose three key components: (1) a topic‑aware attention mechanism, (2) a biased probability generation process, and (3) reinforcement learning with SCST.
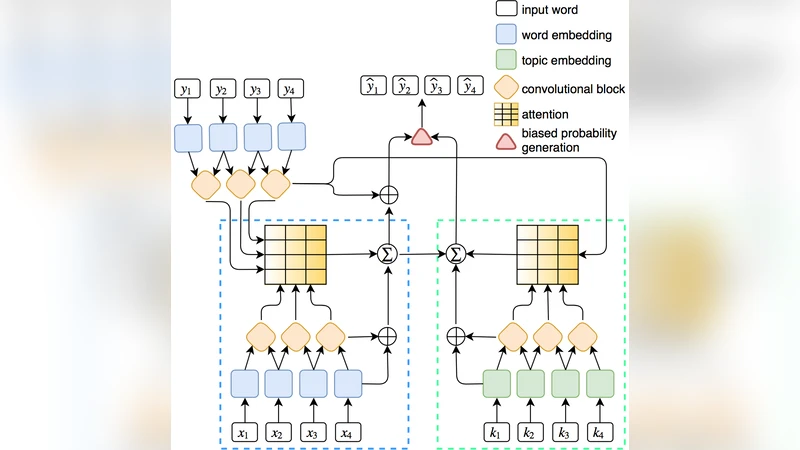
Topic‑aware attention is built on pre‑trained Latent Dirichlet Allocation (LDA) models. For each document, the most probable words for each latent topic are collected into a topic vocabulary K. Words belonging to K receive a dedicated topic embedding from a matrix D_topic, while all other words use standard word embeddings. Both word and topic embeddings are enriched with positional embeddings and processed by separate convolutional encoder blocks. During decoding, the model computes two sets of attention weights: α for word‑level encoder outputs and β for a combination of word‑ and topic‑level encoder outputs. These attentions produce two context vectors (c and \tilde{c}) that are added to the decoder’s hidden states, allowing the decoder to attend simultaneously to fine‑grained lexical cues and higher‑level thematic cues.
The biased probability generation step modifies the final softmax distribution. The decoder produces two logits: one from the word‑level decoder (Ψ(h^o)) and one from the topic‑level decoder (Ψ(\tilde{h}^t)). When a candidate token belongs to the topic vocabulary K, the topic logit is added to the word logit before normalization, effectively boosting the probability of topic‑related words. This bias reduces the search space and encourages the model to generate key thematic terms that are often central to a good summary.
Training with maximum likelihood (teacher forcing) suffers from two issues: (a) the loss does not directly correspond to evaluation metrics such as ROUGE, and (b) exposure bias arises because the model is conditioned on ground‑truth tokens during training but on its own predictions at test time. To overcome these problems, the authors adopt SCST. For each input, the model generates a greedy (baseline) summary \hat{y} and a sampled summary y_s. Both are scored with ROUGE, yielding rewards r(\hat{y}) and r(y_s). The reinforcement loss L_rl = -(r(y_s) - r(\hat{y})) * log p(y_s) is then minimized, which directly maximizes expected ROUGE while using the greedy baseline to reduce variance. This approach aligns training objectives with the evaluation metric and mitigates exposure bias.
Experiments are conducted on three benchmark datasets: the English Gigaword corpus (≈3.8 M training pairs), the DUC‑2004 test set (500 news articles with four reference summaries each), and the Chinese LCSTS dataset (≈2.4 M pairs). The authors report ROUGE‑1, ROUGE‑2, and ROUGE‑L scores. Adding the joint word‑topic attention and biased generation yields consistent improvements of 1–2 percentage points over the vanilla ConvS2S across all datasets. Incorporating SCST provides an additional boost of roughly 0.5–1 point. The gains are especially pronounced on LCSTS, where topic information is more salient, demonstrating that the model effectively captures high‑level semantic structure.
In summary, the contributions of the paper are threefold: (1) a joint attention mechanism that fuses word‑level and topic‑level representations within a ConvS2S framework, (2) a biased generation scheme that preferentially selects topic words, and (3) the application of self‑critical reinforcement learning to directly optimize ROUGE and alleviate exposure bias. The combined system outperforms state‑of‑the‑art RNN‑based and pure ConvS2S summarizers, offering a compelling direction for future work such as dynamic topic modeling, multi‑modal extensions, or end‑to‑end learning of topics jointly with summarization.
Comments & Academic Discussion
Loading comments...
Leave a Comment