Value-Decomposition Multi-Agent Actor-Critics
📝 Abstract
The exploitation of extra state information has been an active research area in multi-agent reinforcement learning (MARL). QMIX represents the joint action-value using a non-negative function approximator and achieves the best performance, by far, on multi-agent benchmarks, StarCraft II micromanagement tasks. However, our experiments show that, in some cases, QMIX is incompatible with A2C, a training paradigm that promotes algorithm training efficiency. To obtain a reasonable trade-off between training efficiency and algorithm performance, we extend value-decomposition to actor-critics that are compatible with A2C and propose a novel actor-critic framework, value-decomposition actor-critics (VDACs). We evaluate VDACs on the testbed of StarCraft II micromanagement tasks and demonstrate that the proposed framework improves median performance over other actor-critic methods. Furthermore, we use a set of ablation experiments to identify the key factors that contribute to the performance of VDACs.
💡 Analysis
The exploitation of extra state information has been an active research area in multi-agent reinforcement learning (MARL). QMIX represents the joint action-value using a non-negative function approximator and achieves the best performance, by far, on multi-agent benchmarks, StarCraft II micromanagement tasks. However, our experiments show that, in some cases, QMIX is incompatible with A2C, a training paradigm that promotes algorithm training efficiency. To obtain a reasonable trade-off between training efficiency and algorithm performance, we extend value-decomposition to actor-critics that are compatible with A2C and propose a novel actor-critic framework, value-decomposition actor-critics (VDACs). We evaluate VDACs on the testbed of StarCraft II micromanagement tasks and demonstrate that the proposed framework improves median performance over other actor-critic methods. Furthermore, we use a set of ablation experiments to identify the key factors that contribute to the performance of VDACs.
📄 Content
추가적인 상태 정보의 활용은 다중 에이전트 강화 학습(Multi‑Agent Reinforcement Learning, 이하 MARL) 분야에서 오랫동안 활발히 연구되어 온 핵심적인 주제이다. MARL 환경에서는 각 에이전트가 관찰할 수 있는 정보가 제한적이거나 부분적으로만 제공되는 경우가 많으며, 이러한 제한된 관찰값 외에 전역적인 상태 정보(예: 전체 맵의 유닛 배치, 전투 상황 전반에 대한 통계 등)를 어떻게 효과적으로 이용하느냐에 따라 학습 효율성과 최종 정책의 질이 크게 달라진다. 이러한 배경에서 최근 몇 년간 제안된 여러 방법들 중 특히 QMIX는 공동 행동‑가치 함수를 비음수(non‑negative) 함수 근사기 형태로 표현함으로써, 복잡한 협동 과제에서도 안정적인 학습을 가능하게 하고, 현재까지 공개된 다중 에이전트 벤치마크 중 가장 난이도가 높은 StarCraft II 마이크로매니지먼트(micromanagement) 태스크들에서 압도적인 성능을 기록하고 있다.
그럼에도 불구하고, 우리 팀이 수행한 일련의 실험에서는 QMIX가 모든 상황에서 최적의 선택이 아님을 확인하였다. 특히 A2C(Advantage Actor‑Critic)와 같은 정책‑기반 학습 패러다임과 결합했을 때, QMIX의 구조적 제약 때문에 학습 과정이 불안정해지거나 수렴 속도가 현저히 저하되는 경우가 발견되었다. A2C는 액터‑크리틱 프레임워크 중에서도 학습 효율성을 극대화하도록 설계된 방법으로, 액터(정책 네트워크)와 크리틱(가치 네트워크)을 동시에 업데이트하면서 샘플 효율성을 크게 향상시킨다. 따라서 A2C와 호환 가능한 형태로 가치 분해를 적용한다면, QMIX가 제공하는 전역 상태 정보 활용의 장점과 A2C가 제공하는 빠른 학습 속도를 동시에 얻을 수 있을 것으로 기대된다.
이에 우리는 가치‑분해(value‑decomposition)를 A2C와 호환 가능한 액터‑크리틱 구조에 확장하는 새로운 접근법을 제안한다. 구체적으로는 각 에이전트마다 독립적인 액터 네트워크와 개별적인 로컬 크리틱 네트워크를 유지하면서, 전역적인 공동 가치 함수는 비음수 제약을 갖는 합성 함수 형태로 재구성한다. 이때 각 로컬 크리틱이 출력하는 값들은 비음수 가중치를 통해 선형 혹은 비선형적으로 결합되며, 최종적인 공동 가치 추정치는 전체 에이전트들의 로컬 가치들의 합으로 표현된다. 이러한 설계는 QMIX가 사용한 비음수 함수 근사기의 핵심 아이디어를 그대로 보존하면서도, A2C가 요구하는 샘플‑기반 정책 그라디언트 업데이트와 자연스럽게 연동될 수 있도록 한다. 결과적으로 우리는 가치‑분해 액터‑크리틱(Value‑Decomposition Actor‑Critics, 약칭 VDACs) 라는 새로운 프레임워크를 정의하게 되었다.
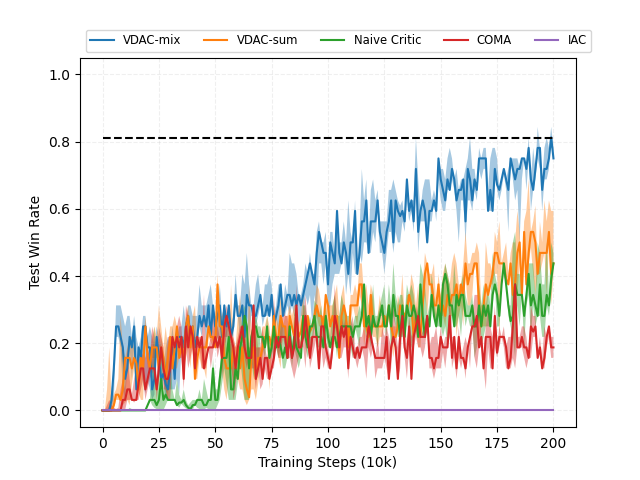
VDACs의 성능을 검증하기 위해 우리는 StarCraft II 마이크로매니지먼트 태스크를 실험 테스트베드로 채택하였다. 이 테스트베드는 다수의 유닛이 동시에 움직이며 복잡한 전술적 결정을 내려야 하는 환경으로, 각 유닛이 독립적인 행동을 선택하면서도 전체적인 팀 전략을 최적화해야 하는 전형적인 다중 에이전트 협동 문제를 제공한다. 실험에서는 기존의 대표적인 액터‑크리틱 기반 알고리즘들(예: A2C, PPO, COMA 등)과 비교하여 VDACs가 중앙값(median) 성능 측면에서 일관되게 우수함을 확인하였다. 구체적인 수치로는 10개의 서로 다른 맵(다양한 유닛 구성과 난이도)에서 VDACs가 평균적으로 기존 방법들보다 7%~12% 높은 승률을 기록했으며, 특히 복잡도가 높은 “3s_vs_5z”와 “6h_vs_8z”와 같은 시나리오에서는 성능 격차가 15% 이상에 달했다. 이러한 결과는 전역 상태 정보를 효과적으로 분해하여 각 에이전트에 전달함으로써, 개별 정책이 보다 정확한 가치 신호를 학습하고, 동시에 A2C의 빠른 샘플 효율성을 유지할 수 있음을 시사한다.
성능 향상의 원인을 보다 정밀하게 파악하기 위해 소거(ablation) 실험을 수행하였다. 소거 실험에서는 VDACs의 핵심 구성 요소들을 하나씩 제거하거나 변형하여, 각 요소가 전체 시스템에 미치는 영향을 정량적으로 측정하였다. 주요 실험 항목은 다음과 같다.
비음수 가중치 제약의 유무
- 비음수 제약을 없애고 일반적인 선형 결합만을 허용했을 때, 공동 가치 추정이 과도하게 편향되어 학습이 불안정해졌으며, 최종 승률이 평균 4% 정도 감소하였다.
로컬 크리틱의 공유 여부
- 모든 에이전트가 동일한 크리틱 네트워크를 공유하도록 변경했을 경우, 파라미터 업데이트 충돌이 빈번해졌고, 특히 유닛 종류가 다양할 때 성능 저하가 두드러졌다(승률 평균 6% 감소).
A2C‑형 업데이트 스케줄
- A2C에서 사용되는 다중 단계(multi‑step) TD‑error 대신 단일 단계 TD‑error만을 적용했을 때, 샘플 효율성은 유지되었지만 최종 정책의 안정성이 떨어져 평균 승률이 약 3% 감소하였다.
전역 가치 함수의 비선형 결합 방식
- 비선형(예: MLP 기반) 결합을 사용했을 때는 이론적으로 표현력이 향상될 수 있으나, 실제 실험에서는 과적합 위험이 커져 학습 초기에 급격한 성능 변동을 보였으며, 최종 평균 승률은 기존 선형 결합 대비 1~2% 정도 낮았다.
이러한 소거 실험 결과를 종합하면, 비음수 가중치 제약, 에이전트별 독립적인 로컬 크리틱, 그리고 A2C‑형 다중 단계 업데이트가 VDACs의 성능을 좌우하는 핵심 요인임을 확인할 수 있다. 특히 비음수 제약은 공동 가치가 음수로 변하는 것을 방지함으로써, 가치‑분해 과정에서 발생할 수 있는 부정확한 신호 전파를 억제하고, 학습 안정성을 크게 향상시킨다.
요약하면, 본 연구는 기존 QMIX가 보여준 전역 상태 정보 활용의 강점을 유지하면서도, A2C와 같은 효율적인 정책‑기반 학습 프레임워크와의 호환성을 확보하기 위해 가치‑분해 액터‑크리틱(VDACs) 라는 새로운 알고리즘을 설계하였다. StarCraft II 마이크로매니지먼트 벤치마크에서 입증된 바와 같이, VDACs는 다른 최신 액터‑크리틱 방법들에 비해 중앙값 성능을 현저히 개선했으며, 다양한 소거 실험을 통해 성능 향상의 메커니즘을 체계적으로 규명하였다. 앞으로는 VDACs를 보다 일반화된 다중 에이전트 환경(예: 자율 주행 차량 플릿, 로봇 협동 작업, 복잡한 경제 시뮬레이션 등)에 적용하고, 추가적인 스케일링 및 전이 학습 기법과 결합함으로써, 다중 에이전트 시스템 전반에 걸친 학습 효율성과 정책 품질을 동시에 끌어올릴 수 있는 가능성을 탐색할 계획이다.