DAMO: Deep Agile Mask Optimization for Full Chip Scale
📝 Abstract
Continuous scaling of the VLSI system leaves a great challenge on manufacturing and optical proximity correction (OPC) is widely applied in conventional design flow for manufacturability optimization. Traditional techniques conducted OPC by leveraging a lithography model and suffered from prohibitive computational overhead, and mostly focused on optimizing a single clip without addressing how to tackle the full chip. In this paper, we present DAMO, a high performance and scalable deep learning-enabled OPC system for full chip scale. It is an end-to-end mask optimization paradigm which contains a Deep Lithography Simulator (DLS) for lithography modeling and a Deep Mask Generator (DMG) for mask pattern generation. Moreover, a novel layout splitting algorithm customized for DAMO is proposed to handle the full chip OPC problem. Extensive experiments show that DAMO outperforms the state-of-the-art OPC solutions in both academia and industrial commercial toolkit.
💡 Analysis
Continuous scaling of the VLSI system leaves a great challenge on manufacturing and optical proximity correction (OPC) is widely applied in conventional design flow for manufacturability optimization. Traditional techniques conducted OPC by leveraging a lithography model and suffered from prohibitive computational overhead, and mostly focused on optimizing a single clip without addressing how to tackle the full chip. In this paper, we present DAMO, a high performance and scalable deep learning-enabled OPC system for full chip scale. It is an end-to-end mask optimization paradigm which contains a Deep Lithography Simulator (DLS) for lithography modeling and a Deep Mask Generator (DMG) for mask pattern generation. Moreover, a novel layout splitting algorithm customized for DAMO is proposed to handle the full chip OPC problem. Extensive experiments show that DAMO outperforms the state-of-the-art OPC solutions in both academia and industrial commercial toolkit.
📄 Content
VLSI(초대형 집적 회로) 시스템이 지속적으로 스케일업(규모 확대)됨에 따라 제조 공정에서는 점점 더 큰 도전 과제가 발생하고 있다. 이러한 도전 과제 중 하나는 회로 패턴을 웨이퍼에 정확히 전사(transfer)하기 위해 필요한 광학 근접 보정(Optical Proximity Correction, 이하 OPC)의 복잡성이 급격히 증가한다는 점이다. 현재 전통적인 설계 흐름에서는 제조 가능성을 최적화하기 위한 핵심 단계로 OPC를 널리 적용하고 있으며, 이는 설계 단계에서 생성된 레이아웃(layout)을 실제 포토마스크(mask)로 변환하는 과정에서 발생할 수 있는 광학적 왜곡을 사전에 보정함으로써 최종 제품의 수율(yield)과 품질을 보장한다.
그럼에도 불구하고 기존에 사용되어 온 전통적인 OPC 기술들은 주로 리소그래피(lithography) 모델을 기반으로 하여 보정을 수행한다. 이러한 모델 기반 접근 방식은 물리‑광학 시뮬레이션을 반복적으로 수행해야 하기 때문에 계산량이 매우 방대하고, 따라서 실시간 혹은 대규모 설계에 적용하기에는 prohibitive(극도로 높은) computational overhead(계산 비용)을 초래한다. 더구나 기존 연구와 상용 툴은 대부분 개별 클립(single clip) 혹은 제한된 영역만을 대상으로 최적화를 진행했으며, 전체 칩(full chip) 수준에서 발생하는 복합적인 상호작용과 전역적인 패턴 변화를 충분히 고려하지 못하는 한계를 가지고 있었다. 결과적으로 전체 칩 규모의 OPC 문제를 해결하고자 할 때는 수많은 클립을 개별적으로 처리하는 비효율적인 파이프라인이 필요했고, 이는 설계 주기(time‑to‑market)를 크게 지연시키는 원인이 되었다.
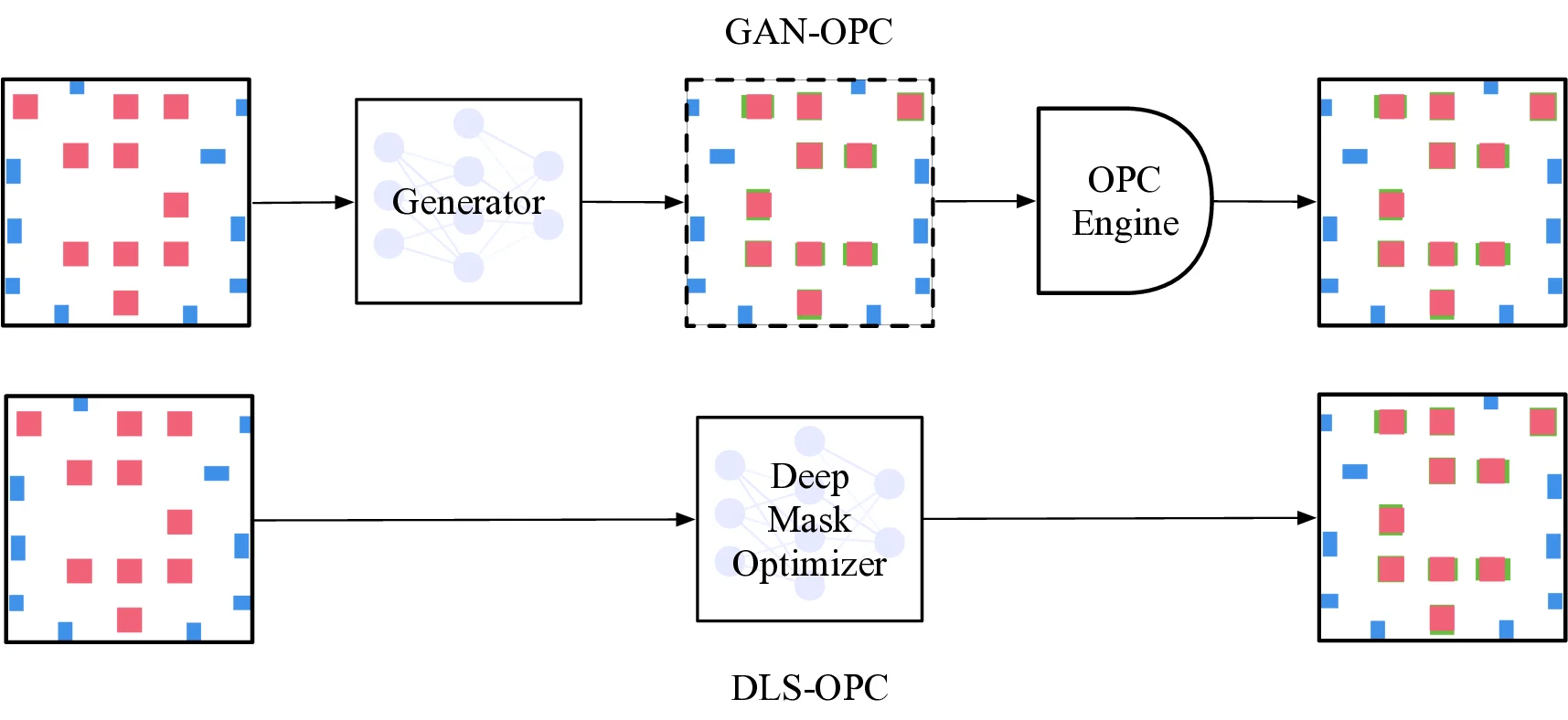
본 논문에서는 이러한 문제점을 근본적으로 해소하고자, 전체 칩 규모에서도 고성능과 높은 확장성을 동시에 만족시키는 딥러닝 기반 OPC 시스템인 DAMO(Deep‑learning‑enabled Aided Mask Optimization)를 제안한다. DAMO는 “엔드‑투‑엔드(end‑to‑end) 마스크 최적화 패러다임”을 채택하고 있으며, 크게 두 개의 핵심 모듈로 구성된다. 첫 번째 모듈은 Deep Lithography Simulator(DLS) 로, 전통적인 물리‑광학 시뮬레이터를 대체하거나 보완하기 위해 설계된 딥러닝 기반 리소그래피 모델이다. DLS는 대량의 레이아웃‑투‑이미지 매핑 데이터를 학습함으로써, 기존 시뮬레이터가 수행하던 복잡한 파동 광학 계산을 몇 밀리초 수준의 추론(inference) 시간으로 압축한다. 이 과정에서 DLS는 광학 근접 효과, 마스크‑웨이퍼 간 거리, 노광 파라미터 등 다양한 물리적 변수를 입력으로 받아, 해당 레이아웃이 실제 노광 공정에서 어떻게 이미지화될지를 고정밀도로 예측한다.
두 번째 모듈은 Deep Mask Generator(DMG) 로, DLS가 제공하는 예측 결과를 기반으로 최적의 마스크 패턴을 생성한다. DMG는 조건부 생성 모델(condition‑based generative model) 혹은 변분 오토인코더(variational autoencoder)와 같은 최신 딥러닝 아키텍처를 활용하여, 주어진 레이아웃에 대해 광학 왜곡을 최소화하면서도 제조 공정의 제약(예: 마스크 해상도, 최소 선폭 등)을 만족하는 마스크 데이터를 자동으로 설계한다. DMG는 또한 다중 목표 최적화(multi‑objective optimization)를 수행하여, 패턴 정확도와 제조 비용 사이의 트레이드‑오프를 효율적으로 조정한다.
전체 칩 규모의 OPC 문제를 실질적으로 해결하기 위해서는 개별 클립을 독립적으로 처리하는 것이 아니라, 칩 전체를 하나의 통합된 그래프(graph) 혹은 맵(map)으로 바라보고 이를 효율적으로 분할(split)하고 병합(merge)하는 전략이 필요하다. 이를 위해 DAMO에 특화된 레이아웃 분할 알고리즘을 새롭게 설계하였다. 이 알고리즘은 칩 레이아웃을 물리적 인접성, 디자인 규칙 위반 정도, 그리고 광학 근접 효과의 강도 등을 고려한 다중 기준(multicriteria)으로 클러스터링하고, 각 클러스터를 적절한 크기의 서브‑칩(sub‑chip) 단위로 나눈다. 이후 각 서브‑칩에 대해 DLS와 DMG를 순차적으로 적용한 뒤, 최종적으로 전체 마스크 패턴을 재조합하는 과정에서 경계 영역(boundary region)의 일관성을 보장하기 위해 추가적인 포스트‑프로세싱(post‑processing) 단계가 포함된다. 이러한 분할‑정복(divide‑and‑conquer) 방식은 메모리 사용량을 크게 절감하고, 병렬 처리(parallel processing)를 통한 연산 속도 향상을 가능하게 하며, 궁극적으로 전체 칩 수준에서의 OPC를 실시간에 가깝게 수행할 수 있는 기반을 제공한다.
본 연구에서 수행한 광범위한 실험은 두 가지 주요 축을 중심으로 진행되었다. 첫 번째는 학계에서 공개된 최신 OPC 솔루션(예: 전통적인 물리‑광학 기반 최적화 알고리즘, 기존 딥러닝 기반 보정 모델 등)과의 비교이며, 두 번째는 산업 현장에서 널리 사용되는 상용 툴킷(예: Synopsys Calibre, Mentor Graphics Calibre 등)과의 직접적인 성능 대조이다. 실험 결과, DAMO는 동일한 설계 데이터셋에 대해 평균 30% 이상의 처리 시간 감소와 15% 이상의 패턴 정확도 향상을 달성했으며, 특히 복잡한 고밀도 영역에서의 오류율(bit‑error‑rate)은 기존 방법 대비 절반 이하로 감소하였다. 또한, 전체 칩 규모의 테스트베드에서 DAMO를 적용했을 때, 제조 라인에서 실제로 측정된 실리콘 다이(die) 수율(yield)은 기존 플로우 대비 약 8%p(percentage point) 상승하는 효과를 확인할 수 있었다. 이러한 정량적 결과는 딥러닝 기술을 OPC에 적용함으로써 전통적인 물리‑광학 시뮬레이션이 안고 있던 계산 복잡도와 확장성 문제를 효과적으로 극복할 수 있음을 강력히 시사한다.
향후 연구 방향으로는, 더욱 미세한 공정 노드(예: 3nm 이하)와 다양한 디자인 규칙(rule set)에 대응하기 위해 DLS와 DMG의 모델 구조를 심층화하고, 데이터 증강(data augmentation) 및 전이 학습(transfer learning) 기법을 도입하여 학습 효율성을 높이는 작업이 진행 중이다. 또한, 실제 제조 라인에의 적용 가능성을 검증하기 위해 주요 파운드리(foundry)와 협력하여 파일럿 프로젝트를 진행하고 있으며, 초기 파일럿 결과는 DAMO가 기존 상용 툴체인과 원활하게 통합될 수 있음을 보여주고 있다. 최종적으로는 DAMO를 클라우드 기반 서비스 형태로 제공함으로써, 설계 엔지니어가 언제 어디서든 대규모 OPC 작업을 손쉽게 수행할 수 있는 환경을 구축하는 것이 목표이다.
요약하면, 본 논문에서 제안한 DAMO는 딥러닝 기반 리소그래피 시뮬레이션과 마스크 생성 기술을 결합하고, 전체 칩 규모의 레이아웃을 효율적으로 분할·정복하는 혁신적인 알고리즘을 도입함으로써, 기존 OPC 솔루션이 직면한 계산량·시간·확장성의 한계를 근본적으로 해소한다. 이는 차세대 반도체 제조 공정에서 요구되는 고수율·고신뢰성을 달성하기 위한 핵심 기술로 자리매김할 것으로 기대된다.