Benchmarking Symbolic Execution Using Constraint Problems -- Initial Results
Symbolic execution is a powerful technique for bug finding and program testing. It is successful in finding bugs in real-world code. The core reasoning techniques use constraint solving, path exploration, and search, which are also the same techniques used in solving combinatorial problems, e.g., finite-domain constraint satisfaction problems (CSPs). We propose CSP instances as more challenging benchmarks to evaluate the effectiveness of the core techniques in symbolic execution. We transform CSP benchmarks into C programs suitable for testing the reasoning capabilities of symbolic execution tools. From a single CSP P, we transform P depending on transformation choice into different C programs. Preliminary testing with the KLEE, Tracer-X, and LLBMC tools show substantial runtime differences from transformation and solver choice. Our C benchmarks are effective in showing the limitations of existing symbolic execution tools. The motivation for this work is we believe that benchmarks of this form can spur the development and engineering of improved core reasoning in symbolic execution engines.
💡 Research Summary
This paper proposes a novel benchmarking methodology to evaluate the core reasoning capabilities of symbolic execution tools, moving beyond traditional benchmarks based on real-world programs. The authors argue that the fundamental techniques underpinning symbolic execution—constraint solving, path exploration, and search—are the same as those used to solve combinatorial problems like finite-domain Constraint Satisfaction Problems (CSPs). Therefore, they suggest that challenging CSP instances can serve as effective stress tests for the core engines of these tools.
The core contribution is a method for transforming CSP instances, specified in the XCSP3 format, into C programs. The transformation encodes the CSP such that reaching a specific program point (an assertion failure, assert(0)) is equivalent to finding a solution to the original CSP. The paper introduces multiple transformation strategies to generate different C programs from the same underlying CSP. The two primary approaches are: 1) the “if” approach, which encodes constraints as conditional statements that cause the program to exit if violated, and 2) the “assume” approach, which uses built-in assumptions (e.g., klee_assume) to directly add constraints to the path condition. Furthermore, variations are created based on whether constraints are handled individually or grouped together, and whether logical or bitwise operators are used, resulting in 22 distinct transformation versions for extensional and intensional constraints.
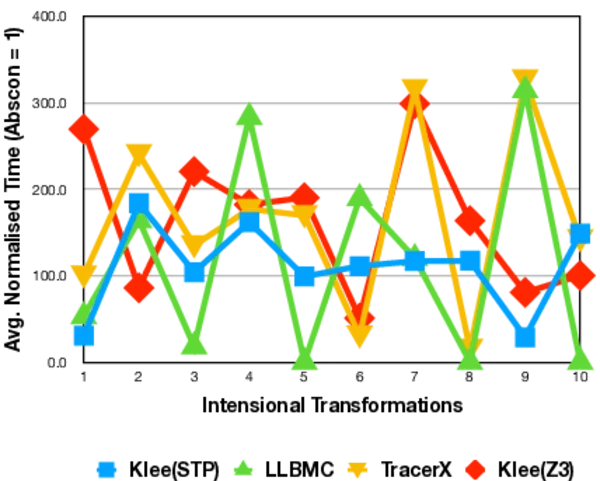
These generated C benchmarks were used in preliminary experiments with several LLVM-based analysis tools: the classic symbolic executor KLEE (with both STP and Z3 solvers), Tracer-X (which adds interpolation to KLEE), and the bounded model checker LLBMC. The results reveal significant insights:
- Code Structure Sensitivity: The execution time of the tools varied substantially across different transformation versions of the same CSP. This demonstrates that the benchmarks successfully expose how sensitive symbolic executors are to the syntactic structure and encoding of the logical problem.
- Tool Comparison: KLEE-based tools showed much greater sensitivity to code structure than LLBMC, highlighting differences in their internal constraint handling and exploration strategies.
- Solver Impact vs. Advanced Techniques: For KLEE-based systems, merely changing the underlying constraint solver (from STP to Z3) had a more pronounced effect on performance than employing Tracer-X’s advanced interpolation-based learning. This suggests that basic constraint solving efficiency remains a critical bottleneck, sometimes overshadowing gains from sophisticated path-reduction techniques.
The authors conclude that their CSP-based benchmarks provide a controlled and challenging way to measure and compare the pure reasoning power of symbolic execution engines, isolating it from other complexities like system calls or memory modeling. They draw an analogy to how hard SAT benchmarks have driven SAT solver development, expressing the hope that their benchmarks will similarly spur improvements in the core algorithms and engineering of symbolic execution tools.
Comments & Academic Discussion
Loading comments...
Leave a Comment