The Univariate Marginal Distribution Algorithm Copes Well With Deception and Epistasis
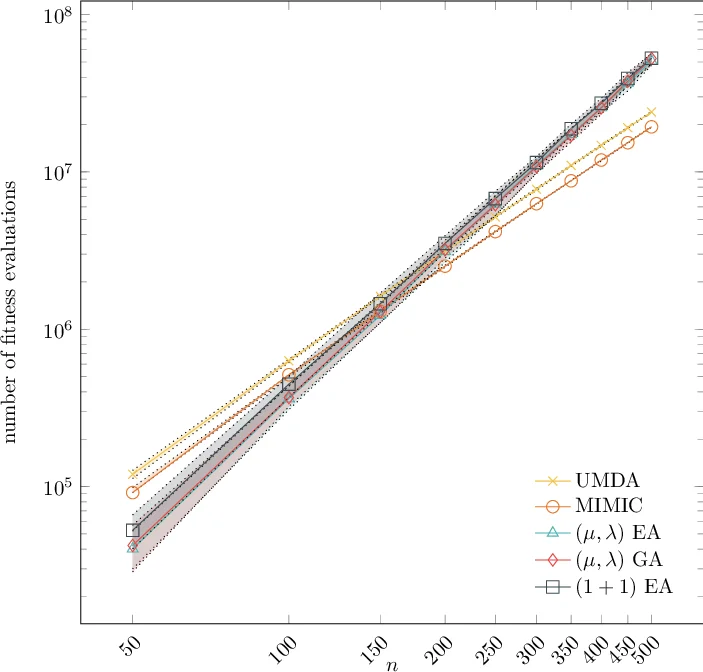
In their recent work, Lehre and Nguyen (FOGA 2019) show that the univariate marginal distribution algorithm (UMDA) needs time exponential in the parent populations size to optimize the DeceptiveLeadingBlocks (DLB) problem. They conclude from this result that univariate EDAs have difficulties with deception and epistasis. In this work, we show that this negative finding is caused by an unfortunate choice of the parameters of the UMDA. When the population sizes are chosen large enough to prevent genetic drift, then the UMDA optimizes the DLB problem with high probability with at most $λ(\frac{n}{2} + 2 e \ln n)$ fitness evaluations. Since an offspring population size $λ$ of order $n \log n$ can prevent genetic drift, the UMDA can solve the DLB problem with $O(n^2 \log n)$ fitness evaluations. In contrast, for classic evolutionary algorithms no better run time guarantee than $O(n^3)$ is known (which we prove to be tight for the ${(1+1)}$ EA), so our result rather suggests that the UMDA can cope well with deception and epistatis. From a broader perspective, our result shows that the UMDA can cope better with local optima than evolutionary algorithms; such a result was previously known only for the compact genetic algorithm. Together with the lower bound of Lehre and Nguyen, our result for the first time rigorously proves that running EDAs in the regime with genetic drift can lead to drastic performance losses.
💡 Research Summary
The paper revisits the recent negative result of Lehre and Nguyen (FOGA 2019), which claimed that the univariate marginal distribution algorithm (UMDA) suffers an exponential runtime in the parent population size µ when optimizing the DeceptiveLeadingBlocks (DLB) function, and consequently argued that single‑margin EDAs have inherent difficulties with deception and epistasis. The authors demonstrate that this pessimistic conclusion stems from an unfortunate choice of UMDA parameters that induces strong genetic drift. By selecting the population sizes large enough to avoid drift, they prove that UMDA solves DLB with high probability in at most
\
Comments & Academic Discussion
Loading comments...
Leave a Comment