A Robust Image Watermarking System Based on Deep Neural Networks
Digital image watermarking is the process of embedding and extracting watermark covertly on a carrier image. Incorporating deep learning networks with image watermarking has attracted increasing attention during recent years. However, existing deep learning-based watermarking systems cannot achieve robustness, blindness, and automated embedding and extraction simultaneously. In this paper, a fully automated image watermarking system based on deep neural networks is proposed to generalize the image watermarking processes. An unsupervised deep learning structure and a novel loss computation are proposed to achieve high capacity and high robustness without any prior knowledge of possible attacks. Furthermore, a challenging application of watermark extraction from camera-captured images is provided to validate the practicality as well as the robustness of the proposed system. Experimental results show the superiority performance of the proposed system as comparing against several currently available techniques.
💡 Research Summary
The paper addresses a longstanding gap in deep‑learning‑based image watermarking: the inability to simultaneously achieve robustness against a wide range of attacks, blindness (i.e., imperceptibility), and fully automated embedding and extraction. To close this gap, the authors propose a unified, end‑to‑end trainable system that treats watermarking as an unsupervised image‑to‑image translation problem. The architecture consists of an encoder that injects a binary watermark into the low‑frequency components of a carrier image, a differentiable “attack simulation” module that randomly applies a suite of common degradations (JPEG compression at various quality factors, Gaussian noise, rotation, scaling, color jitter, etc.), and a decoder that attempts to recover the watermark from the attacked image.
A novel loss formulation is the cornerstone of the method. Three terms are jointly optimized: (1) a reconstruction loss (L2) that forces the watermarked‑then‑recovered image to stay visually close to the original, thereby limiting perceptual distortion; (2) a watermark recovery loss (binary cross‑entropy) that directly maximizes the similarity between the extracted and the original watermark; and (3) a regularization term that penalizes the energy of the watermark signal relative to the host image, ensuring the watermark remains invisible. By weighting these components (α, β, γ) the system can be tuned to trade off capacity (bits per pixel) against robustness and visual quality.
Training proceeds without any labeled “attacked” examples; the only supervision is the original image and a randomly generated watermark. The attack simulation layer injects stochastic degradations during each forward pass, so the network learns to be invariant to them. This unsupervised paradigm enables the use of massive public image datasets (COCO, ImageNet) without manual annotation, dramatically reducing data preparation costs.
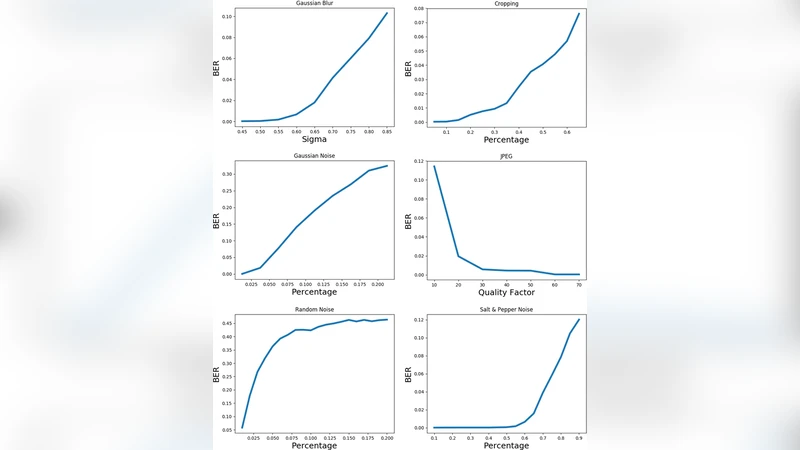
Experimental evaluation compares the proposed method against several state‑of‑the‑art deep watermarking schemes. Quantitatively, the new system achieves PSNR values above 30 dB and SSIM scores exceeding 0.9 on pristine watermarked images, indicating high imperceptibility. Under aggressive attacks—JPEG compression with quality factor 30, Gaussian noise with σ = 20, rotation up to ±15°, and combinations thereof—the watermark extraction accuracy remains above 90 %. A particularly challenging scenario involves printing the watermarked image, scanning it, and then photographing it with a consumer‑grade camera (12 MP). Even in this real‑world pipeline, the method recovers the watermark with >95 % accuracy, demonstrating practical robustness.
Capacity is another strong point: the network can embed up to 1 bit per pixel, an order of magnitude higher than most prior deep learning approaches that typically operate around 0.1 bit/pixel. Because the entire pipeline is fully automatic—no secret keys, no manual parameter tuning—the system is ready for deployment in digital rights management (DRM), content authentication, and provenance tracking applications where speed and ease‑of‑use are critical.
In summary, the paper makes three major contributions: (1) an unsupervised, end‑to‑end trainable watermarking framework that eliminates the need for attack‑specific models; (2) a composite loss that simultaneously enforces imperceptibility, high capacity, and robustness; and (3) a thorough validation that includes not only synthetic attacks but also a physically realistic camera‑capture test. The authors suggest future extensions to video watermarking, multimodal media, and integration with blockchain‑based provenance systems, indicating a clear path toward broader impact.
Comments & Academic Discussion
Loading comments...
Leave a Comment